AMD Radeon HD 7970 Review: 28nm And Graphics Core Next, Together As One
by Ryan Smith on December 22, 2011 12:00 AM EST- Posted in
- GPUs
- AMD
- Radeon
- ATI
- Radeon HD 7000
A Quick Refresher, Cont
Having established what’s bad about VLIW as a compute architecture, let’s discuss what makes a good compute architecture. The most fundamental aspect of compute is that developers want stable and predictable performance, something that VLIW didn’t lend itself to because it was dependency limited. Architectures that can’t work around dependencies will see their performance vary due to those dependencies. Consequently, if you want an architecture with stable performance that’s going to be good for compute workloads then you want an architecture that isn’t impacted by dependencies.
Ultimately dependencies and ILP go hand-in-hand. If you can extract ILP from a workload, then your architecture is by definition bursty. An architecture that can’t extract ILP may not be able to achieve the same level of peak performance, but it will not burst and hence it will be more consistent. This is the guiding principle behind NVIDIA’s Fermi architecture; GF100/GF110 have no ability to extract ILP, and developers love it for that reason.
So with those design goals in mind, let’s talk GCN.
VLIW is a traditional and well proven design for parallel processing. But it is not the only traditional and well proven design for parallel processing. For GCN AMD will be replacing VLIW with what’s fundamentally a Single Instruction Multiple Data (SIMD) vector architecture (note: technically VLIW is a subset of SIMD, but for the purposes of this refresher we’re considering them to be different).

A Single GCN SIMD
At the most fundamental level AMD is still using simple ALUs, just like Cayman before it. In GCN these ALUs are organized into a single SIMD unit, the smallest unit of work for GCN. A SIMD is composed of 16 of these ALUs, along with a 64KB register file for the SIMDs to keep data in.
Above the individual SIMD we have a Compute Unit, the smallest fully independent functional unit. A CU is composed of 4 SIMD units, a hardware scheduler, a branch unit, L1 cache, a local date share, 4 texture units (each with 4 texture fetch load/store units), and a special scalar unit. The scalar unit is responsible for all of the arithmetic operations the simple ALUs can’t do or won’t do efficiently, such as conditional statements (if/then) and transcendental operations.
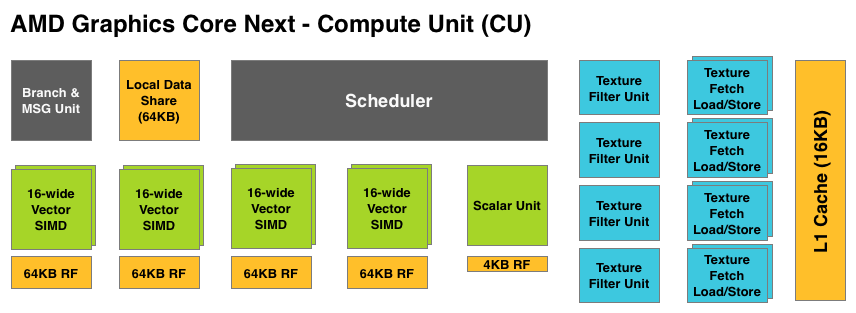
Because the smallest unit of work is the SIMD and a CU has 4 SIMDs, a CU works on 4 different wavefronts at once. As wavefronts are still 64 operations wide, each cycle a SIMD will complete ¼ of the operations on their respective wavefront, and after 4 cycles the current instruction for the active wavefront is completed.
Cayman by comparison would attempt to execute multiple instructions from the same wavefront in parallel, rather than executing a single instruction from multiple wavefronts. This is where Cayman got bursty – if the instructions were in any way dependent, Cayman would have to let some of its ALUs go idle. GCN on the other hand does not face this issue, because each SIMD handles single instructions from different wavefronts they are in no way attempting to take advantage of ILP, and their performance will be very consistent.
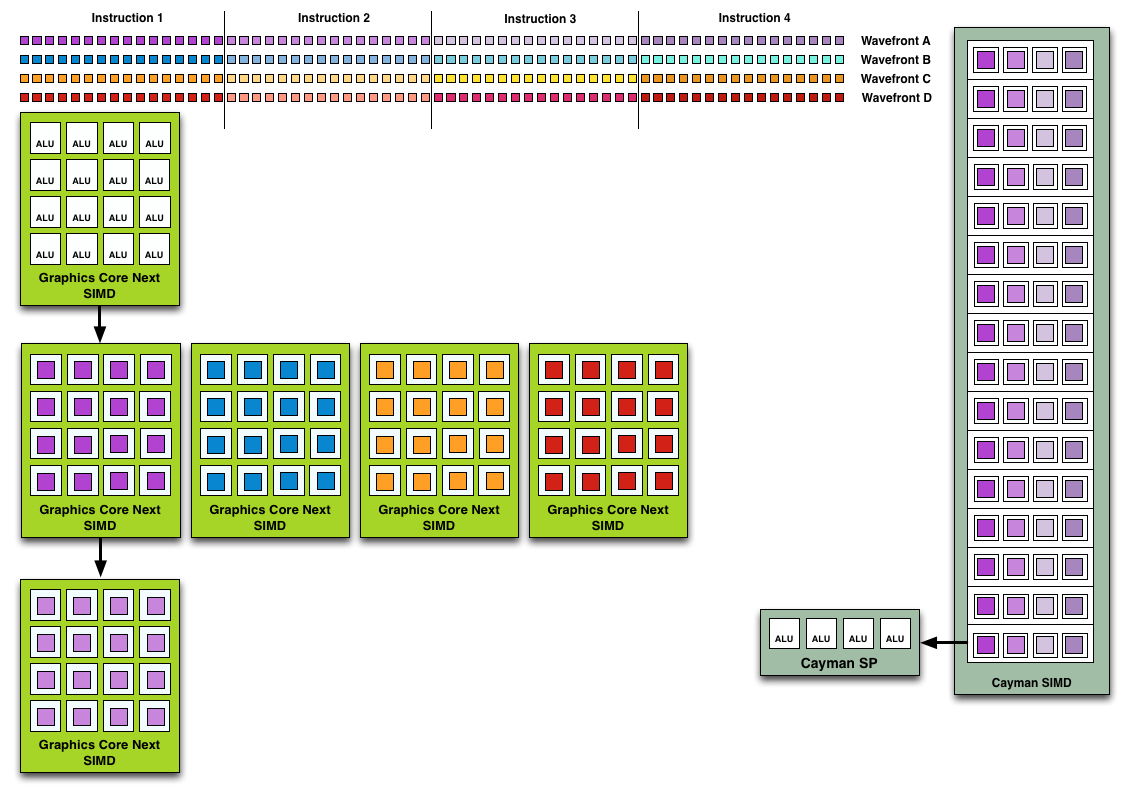
Wavefront Execution Example: SIMD vs. VLIW. Not To Scale - Wavefront Size 16
There are other aspects of GCN that influence its performance – the scalar unit plays a huge part – but in comparison to Cayman, this is the single biggest difference. By not taking advantage of ILP, but instead taking advantage of Thread Level Parallism (TLP) in the form of executing more wavefronts at once, GCN will be able to deliver high compute performance and to do so consistently.
Bringing this all together, to make a complete GPU a number of these GCN CUs will be combined with the rest of the parts we’re accustomed to seeing on a GPU. A frontend is responsible for feeding the GPU, as it contains both the command processors (ACEs) responsible for feeding the CUs and the geometry engines responsible for geometry setup. Meanwhile coming after the CUs will be the ROPs that handle the actual render operations, the L2 cache, the memory controllers, and the various fixed function controllers such as the display controllers, PCIe bus controllers, Universal Video Decoder, and Video Codec Engine.
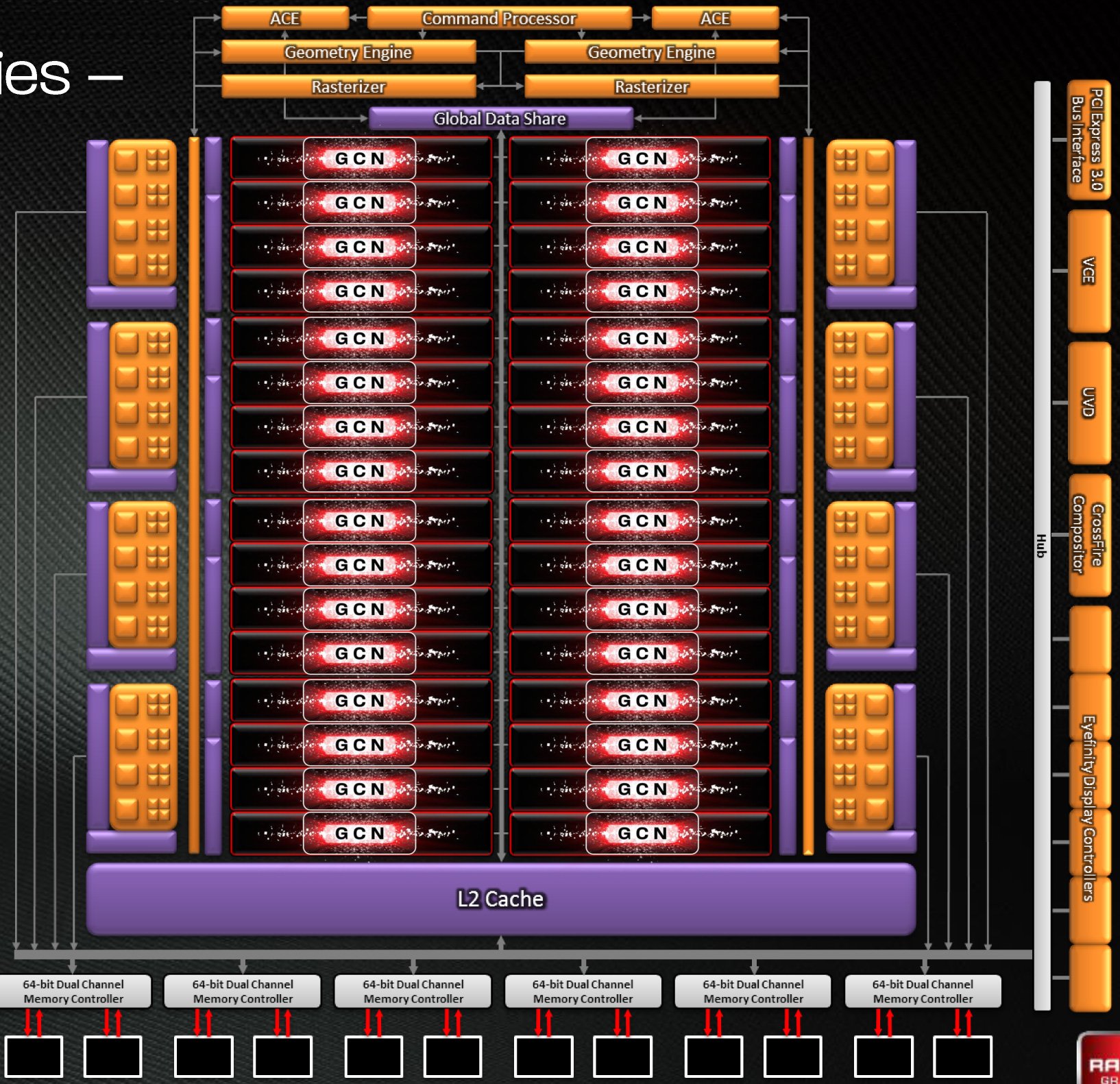
At the end of the day if AMD has done their homework GCN should significantly improve compute performance relative to VLIW4 while gaming performance should be just as good. Gaming shader operations will execute across the CUs in a much different manner than they did across VLIW, but they should do so at a similar speed. And for games that use compute shaders, they should directly benefit from the compute improvements. It’s by building out a GPU in this manner that AMD can make an architecture that’s significantly better at compute without sacrificing gaming performance, and this is why the resulting GCN architecture is balanced for both compute and graphics.








292 Comments
View All Comments
Scali - Saturday, December 24, 2011 - link
I have never heard Jen-Hsun call the mock-up a working board.They DID however have working boards on which they demonstrated the tech-demos.
Stop trying to make something out of nothing.
Scali - Saturday, December 24, 2011 - link
Actually, since Crysis 2 does not 'tessellate the crap' out of things (unless your definition of that is: "Doesn't run on underperforming tessellation hardware"), the 7970 is actually the fastest card in Crysis 2.Did you even bother to read some other reviews? Many of them tested Crysis 2, you know. Tomshardware for example.
If you try to make smart fanboy remarks, at least make sure they're smart first.
Scali - Saturday, December 24, 2011 - link
But I know... being a fanboy must be really hard these days..One moment you have to spread nonsense about how Crysis 2's tessellation is totally over-the-top...
The next moment, AMD comes out with a card that has enough of a boost in performance that it comes out on top in Crysis 2 again... So you have to get all up to date with the latest nonsense again.
Now you know what the AMD PR department feels like... they went from "Tessellation good" to "Tessellation bad" as well, and have to move back again now...
That is, they would, if they weren't all fired by the new management.
formulav8 - Tuesday, February 21, 2012 - link
Your worse than anything he said. Grow upCeriseCogburn - Sunday, March 11, 2012 - link
He's exactly correct. I quite understand for amd fanboys that's forbidden, one must tow the stupid crybaby line and never deviate to the truth.crazzyeddie - Sunday, December 25, 2011 - link
Page 4:" Traditionally the ROPs, L2 cache, and memory controllers have all been tightly integrated as ROP operations are extremely bandwidth intensive, making this a very design for AMD to use. "
Scali - Monday, December 26, 2011 - link
Ofcourse it isn't. More polygons is better. Pixar subdivides everything on screen to sub-pixel level.That's where games are headed as well, that's progress.
Only fanboys like you cry about it.... even after AMD starts winning the benchmarks (which would prove that Crysis is not doing THAT much tessellation, both nVidia and new AMD hardware can deal with it adequately).
Wierdo - Monday, January 2, 2012 - link
http://techreport.com/articles.x/21404"Crytek's decision to deploy gratuitous amounts of tessellation in places where it doesn't make sense is frustrating, because they're essentially wasting GPU power—and they're doing so in a high-profile game that we'd hoped would be a killer showcase for the benefits of DirectX 11
...
But the strange inefficiencies create problems. Why are largely flat surfaces, such as that Jersey barrier, subdivided into so many thousands of polygons, with no apparent visual benefit? Why does tessellated water roil constantly beneath the dry streets of the city, invisible to all?
...
One potential answer is developer laziness or lack of time
...
so they can understand why Crysis 2 may not be the most reliable indicator of comparative GPU performance"
I'll take the word of professional reviewers.
CeriseCogburn - Sunday, March 11, 2012 - link
Give them a month or two to adjust their amd epic fail whining blame shift.When it occurs to them that amd is actually delivering some dx11 performance for the 1st time, they'll shift to something else they whine about and blame on nvidia.
The big green MAN is always keeping them down.
Scali - Monday, December 26, 2011 - link
Wrong, they showed plenty of demos at the introduction. Else the introduction would just be Jen-Hsun holding up the mock card, and nothing else... which was clearly not the case.They demo'ed Endless City, among other things. Which could not have run on anything other than real Fermi chips.
And yea, I'm really going to go to SemiAccurate to get reliable information!