AMD Radeon HD 7970 Review: 28nm And Graphics Core Next, Together As One
by Ryan Smith on December 22, 2011 12:00 AM EST- Posted in
- GPUs
- AMD
- Radeon
- ATI
- Radeon HD 7000
A Quick Refresher, Cont
Having established what’s bad about VLIW as a compute architecture, let’s discuss what makes a good compute architecture. The most fundamental aspect of compute is that developers want stable and predictable performance, something that VLIW didn’t lend itself to because it was dependency limited. Architectures that can’t work around dependencies will see their performance vary due to those dependencies. Consequently, if you want an architecture with stable performance that’s going to be good for compute workloads then you want an architecture that isn’t impacted by dependencies.
Ultimately dependencies and ILP go hand-in-hand. If you can extract ILP from a workload, then your architecture is by definition bursty. An architecture that can’t extract ILP may not be able to achieve the same level of peak performance, but it will not burst and hence it will be more consistent. This is the guiding principle behind NVIDIA’s Fermi architecture; GF100/GF110 have no ability to extract ILP, and developers love it for that reason.
So with those design goals in mind, let’s talk GCN.
VLIW is a traditional and well proven design for parallel processing. But it is not the only traditional and well proven design for parallel processing. For GCN AMD will be replacing VLIW with what’s fundamentally a Single Instruction Multiple Data (SIMD) vector architecture (note: technically VLIW is a subset of SIMD, but for the purposes of this refresher we’re considering them to be different).

A Single GCN SIMD
At the most fundamental level AMD is still using simple ALUs, just like Cayman before it. In GCN these ALUs are organized into a single SIMD unit, the smallest unit of work for GCN. A SIMD is composed of 16 of these ALUs, along with a 64KB register file for the SIMDs to keep data in.
Above the individual SIMD we have a Compute Unit, the smallest fully independent functional unit. A CU is composed of 4 SIMD units, a hardware scheduler, a branch unit, L1 cache, a local date share, 4 texture units (each with 4 texture fetch load/store units), and a special scalar unit. The scalar unit is responsible for all of the arithmetic operations the simple ALUs can’t do or won’t do efficiently, such as conditional statements (if/then) and transcendental operations.
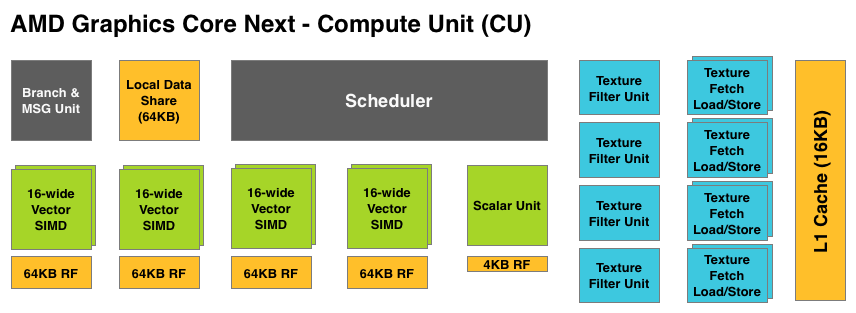
Because the smallest unit of work is the SIMD and a CU has 4 SIMDs, a CU works on 4 different wavefronts at once. As wavefronts are still 64 operations wide, each cycle a SIMD will complete ¼ of the operations on their respective wavefront, and after 4 cycles the current instruction for the active wavefront is completed.
Cayman by comparison would attempt to execute multiple instructions from the same wavefront in parallel, rather than executing a single instruction from multiple wavefronts. This is where Cayman got bursty – if the instructions were in any way dependent, Cayman would have to let some of its ALUs go idle. GCN on the other hand does not face this issue, because each SIMD handles single instructions from different wavefronts they are in no way attempting to take advantage of ILP, and their performance will be very consistent.
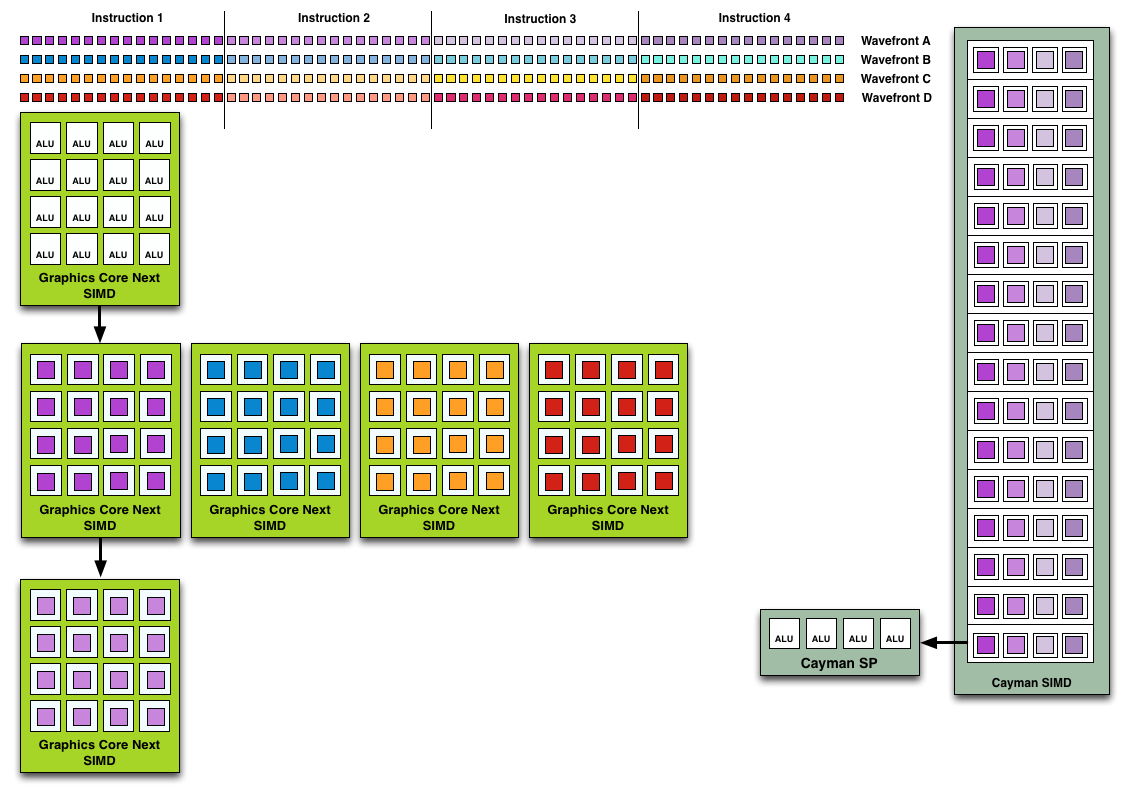
Wavefront Execution Example: SIMD vs. VLIW. Not To Scale - Wavefront Size 16
There are other aspects of GCN that influence its performance – the scalar unit plays a huge part – but in comparison to Cayman, this is the single biggest difference. By not taking advantage of ILP, but instead taking advantage of Thread Level Parallism (TLP) in the form of executing more wavefronts at once, GCN will be able to deliver high compute performance and to do so consistently.
Bringing this all together, to make a complete GPU a number of these GCN CUs will be combined with the rest of the parts we’re accustomed to seeing on a GPU. A frontend is responsible for feeding the GPU, as it contains both the command processors (ACEs) responsible for feeding the CUs and the geometry engines responsible for geometry setup. Meanwhile coming after the CUs will be the ROPs that handle the actual render operations, the L2 cache, the memory controllers, and the various fixed function controllers such as the display controllers, PCIe bus controllers, Universal Video Decoder, and Video Codec Engine.
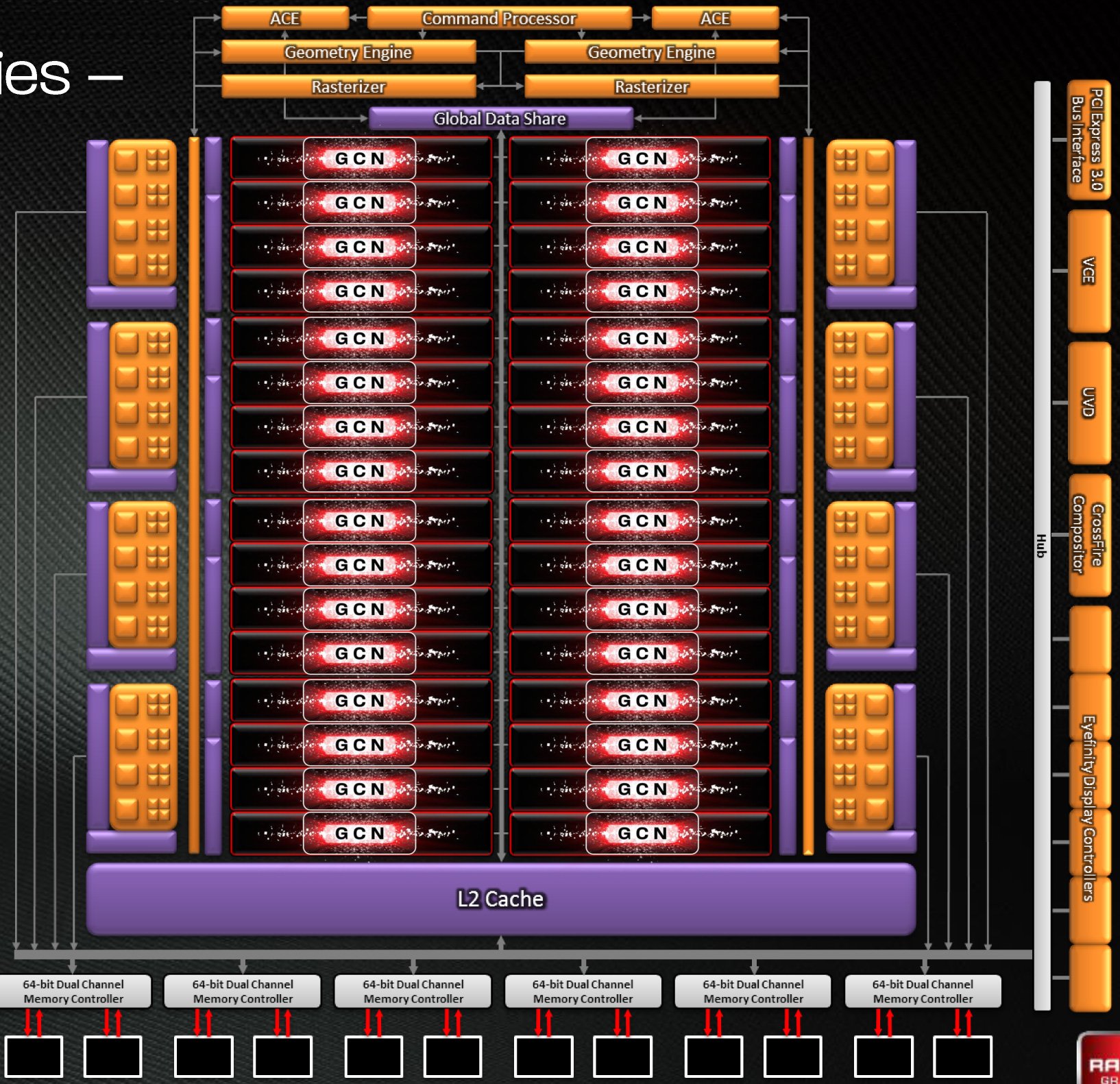
At the end of the day if AMD has done their homework GCN should significantly improve compute performance relative to VLIW4 while gaming performance should be just as good. Gaming shader operations will execute across the CUs in a much different manner than they did across VLIW, but they should do so at a similar speed. And for games that use compute shaders, they should directly benefit from the compute improvements. It’s by building out a GPU in this manner that AMD can make an architecture that’s significantly better at compute without sacrificing gaming performance, and this is why the resulting GCN architecture is balanced for both compute and graphics.








292 Comments
View All Comments
B3an - Thursday, December 22, 2011 - link
Anyone with half a brain should have worked out that being as this was going to be AMD's Fermi that it would not of had a massive increase for gaming, simply because many of those extra transistors are there for computing purposes. NOT for gaming. Just as with Fermi.The performance of this card is pretty much exactly as i expected.
Peichen - Friday, December 23, 2011 - link
AMD has been saying for ages that GPU computing is useless and CPU is the only way to go. I guess they just have a better PR department than Nvidia.BTW, before suggesting I have suffered brain trauma, remember that Nvidia delivered on Fermi 2 and GK100 will be twice as powerful as GF110
CeriseCogburn - Thursday, March 8, 2012 - link
Well it was nice to see the amd fans with half a heart admit amd has accomplished something huge by abandoned gaming, as they couldn't get enough of screaming it against nvidia... even as the 580 smoked up the top line stretch so many times...It's so entertaining...
CeriseCogburn - Thursday, March 8, 2012 - link
AMD is the dumb company. Their dumb gpu shaders. Their x86 copying of intel. Now after a few years they've done enough stealing and corporate espionage to "clone" Nvidia architecture and come out with this 7k compute.If they're lucky Nvidia will continue doing all software groundbreaking and carry the massive load by a factor of ten or forty to one working with game developers, porting open gl and open cl to workable programs and as amd fans have demanded giving them PhysX ported out to open source "for free", at which point it will suddenly be something no gamer should live without.
"Years behind" is the real story that should be told about amd and it's graphics - and it's cpu's as well.
Instead we are fed worthless half truths and lies... a "tesselator" in the HD2900 (while pathetic dx11 perf is still the amd norm)... the ddr5 "groundbreaker" ( never mentioned was the sorry bit width that made cheap 128 and 256 the reason for ddr5 needs)...
Etc.
When you don't see the promised improvement, the radeonites see a red rocket shooting to the outer depths of the galaxy and beyond...
Just get ready to pay some more taxes for the amd bailout coming.
durinbug - Thursday, December 22, 2011 - link
I was intrigued by the comment about driver command lists, somehow I missed all of that when it happened. I went searching and finally found this forum post from Ryan:http://forums.anandtech.com/showpost.php?p=3152067...
It would be nice to link to that from the mention of DCL for those of us not familiar with it...
digitalzombie - Thursday, December 22, 2011 - link
I know I'm a minority, but I use Linux to crunch data and GPU would help a lot...I was wondering if you guys can try to use these cards on Debian/Ubuntu or Fedora? And maybe report if 3d acceleration actually works? My current amd card have bad driver for Linux, shearing and glitches, which sucks when I try to number crunch and map stuff out graphically in 3d. Hell I try compiling the driver's source code and it doesn't work.
Thank you!
WaltC - Thursday, December 22, 2011 - link
Somebody pinch me and tell me I didn't just read a review of a brand-new, high-end ATi card that apparently *forgot* Eyefinity is a feature the stock nVidia 580--the card the author singles out for direct comparison with the 7970--doesn't offer in any form. Please tell me it's my eyesight that is failing, because I missed the benchmark bar charts detailing the performance of the Eyefinity 6-monitor support in the 7970 (but I do recall seeing esoteric bar-chart benchmarks for *PCIe 3.0* performance comparisons, however. I tend to think that multi-monitor support, or the lack of it, is far more an important distinction than PCIe 3.0 support benchmarks at present.)Oh, wait--nVidia's stock 580 doesn't do nVidia's "NV Surround triple display" and so there was no point in mentioning that "trivial fact" anywhere in the article? Why compare two cards so closely but fail to mention a major feature one of them supports that the other doesn't? Eh? Is it the author's opinion that multi-monitor gaming is not worth having on either gpu platform? If so, it would be nice to know that by way of the author's admission. Personally, I think that knowing whether a product will support multi monitors and *playable* resolutions up to 5760x1200 ROOB is *somewhat* important in a product review. (sarcasm/massive understatement)
Aside from that glaring oversight, I thought this review was just fair, honestly--and if the author had been less interested in apologizing for nVidia--we might even have seen a better one. Reading his hastily written apologies was kind of funny and amusing, though. But leaving out Eyefinity performance comparisons by pretending the feature isn't relative to the 7970, or that it isn't a feature worth commenting on relative to nVidia's stock 580? Very odd. The author also states: "The purpose of MST hubs was so that users could use several monitors with a regular Radeon card, rather than needing an exotic all-DisplayPort “Eyefinity edition” card as they need now," as if this is an industry-standard component that only ATi customers are "asking for," when it sure seems like nVidia customers could benefit from MST even more at present.
I seem to recall reading the following statement more than once in this review but please pardon me if it was only stated once: "... but it’s NVIDIA that makes all the money." Sorry but even a dunce can see that nVidia doesn't now and never has "made all the money." Heh...;) If nVidia "made all the money," and AMD hadn't made any money at all (which would have to be the case if nVidia "made all the money") then we wouldn't see a 7970 at all, would we? It's possible, and likely, that the author meant "nVidia made more money," which is an independent declaration I'm not inclined to check, either way. But it's for certain that in saying "nVidia made all the money" the author was--obviously--wrong.
The 7970 is all the more impressive considering how much longer nVidia's had to shape up and polish its 580-ish driver sets. But I gather that simple observation was also too far fetched for the author to have seriously considered as pertinent. The 7970 is impressive, AFAIC, but this review is somewhat disappointing. Looks like it was thrown together in a big hurry.
Finally - Friday, December 23, 2011 - link
On AT you have to compensate for their over-steering while reading.Death666Angel - Thursday, December 22, 2011 - link
"Intel implemented Quick Sync as a CPU company, but does that mean hardware H.264 encoders are a CPU feature?" << Why is that even a question. I cannot use the feature unless I am using the iGPU or use the dGPU with Lucid Virtu. As such, it is not a feature of the CPU in my book.Roald - Thursday, December 22, 2011 - link
I don't agree with the conclusion. I think it's much more of a perspective thing. Comming from the 6970 to the 7970 it's not a great win in the gaming deparment. However the same can be said from the change from 4870 to 5870 to 6970. The only real benefit the 5870 had over the 4870 was DX11 support, which didn't mean so much for the games at the time.Now there is a new architechture that not only manages to increase FPS in current games, it also has growing potential and manages to excell in the compute field aswell at the same time.
The conclusion made in the Crysis warhead part of this review should therefore also have been highlighted as finals words.