Bulldozer for Servers: Testing AMD's "Interlagos" Opteron 6200 Series
by Johan De Gelas on November 15, 2011 5:09 PM ESTTrueCrypt 7.1 Benchmark
TrueCrypt is a software application used for on-the-fly encryption (OTFE). It is free, open source and offers full AES-NI support. The application also features a built-in encryption benchmark that we can use to measure CPU performance. First we test with the AES algorithm (256-bit key, symmetric).

You can compare those numbers directly with Anand's benchmark here. The Core i7-2600K at 3.4GHz delivers 3.4GB/s and the AMD FX-8150 at 3.6GHz about the same 3.3GB/s. We get about 2.3 times the performance here with four times as many "cores", but at 2.3GHz instead of 3.6GHz.
We also test with the heaviest combination of the cascaded algorithms available: Serpent-Twofish-AES.

The combination benchmark is limited by the slowest algorithms: twofish and serpent. The huge advantage that the architectures (Opteron "Bulldozer" and Xeon "Westmere") which support AES-NI had has evaporated: the Opteron 6174 keeps up with the best Xeons. The Opteron 6276 can leverage its higher threadcount as this benchmark scales extremely well.
It is good to realize that these benchmarks are not real-world but rather synthetic. It would be better to test a website that does some encrypting in the background or a fileserver with encrypted partitions. In that case the encryption software is only a small part of the total code being run. A large performance (dis)advantage might translate into a much smaller performance (dis)advantage in that real-world situation.
For example, eight times faster encryption resulted in a website with 23% higher throughput and a 40% faster encrypted file (see here). The advantage that the Xeon had in the first benchmark will not be noticeable, and the Opteron's 24% higher performance will translate into a few percentage points. But this is a benchmark where AMD's efforts to get a 16 integer cores inside a 115W TDP pay off.
7-Zip 9.2
7-zip is a file archiver with a high compression ratio. 7-Zip is open source software, and most of the source code is under the GNU LGPL license
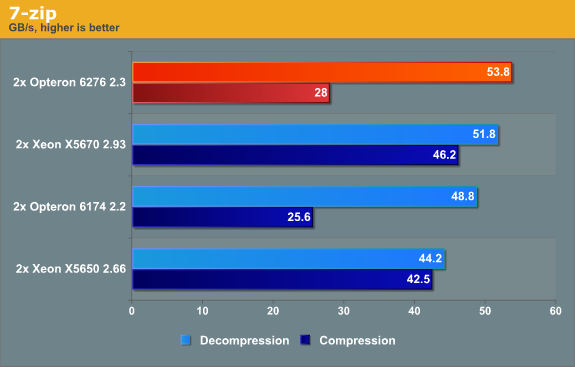
Compression is more CPU intensive than decompression, and the latter depends a little more on memory bandwidth. When it comes to load/stores and memory bandwidth, the Opteron 6276 is unbeateable. We've also seen indications that Bulldozer's cache does very well in reads but not so well in writes, and that could account for some of the gap between the compress/decompress results.
Compression is for a part determined by the quality of the branch predictor (higher than normal branch mispredictions on mediocre branch predictors). The Opteron 6276 has a better branch predictor than the Opteron 6174, but the branch misprediction penalty has grown from 12 to 20 cycles. As a result, a single branch intensive thread runs slower (see Anand's tests) on the newest AMD architecture. Luckily, the AMD Opteron 6276 can compensate for this with its 16 threads (vs 12 threads for the Opteron 6172) and a little bit of help from Turbo Core.
Intel still has the best branch predictors in the industry. The result is that the Xeon is by far the fastest compressor. The end result is that the Xeon is the more rounded CPU in this discipline.








106 Comments
View All Comments
veri745 - Tuesday, November 15, 2011 - link
Shouldn't there be 8 x 2MB L2 for Interlagos instead of just 4x?ClagMaster - Tuesday, November 15, 2011 - link
A core this complex in my opinion has not been optimized to its fullest potential.Expect better performance when AMD introduces later steppings of this core with regard to power consumption and higher clock frequencies.
I have seen this in earlier AMD and Intel Cores, this new core will be the same.
C300fans - Tuesday, November 15, 2011 - link
1x i7 3960x or 2x Interlagos 6272? It is up to you. Money cow.tech6 - Tuesday, November 15, 2011 - link
We have a bunch of 6100 in our data center and the performance has been disappointing. They do no better in single thread performance than old 73xx series Xeons. While this is OK for non-interactive stuff, it really isn't good enough for much else. These results just seem to confirm that the Bulldozer series of processors is over-hyped and that AMD is in danger of becoming irrelevant in the server, mobile and desktop market.mino - Wednesday, November 16, 2011 - link
Actually, for interactive stuff (read VDI/Citrix/containers) core counts rule the roost.duploxxx - Thursday, November 17, 2011 - link
this is exactly what should be fixed now with the turbo when set correct, btw the 73xx series were not that bad on single thread performance, it was wide scale virtualization and IO throughput which was awefull one these systems.alpha754293 - Tuesday, November 15, 2011 - link
"Let us first discuss the virtualization scene, the most important market." Yea, I don't know about that.Considering that they've already shipped like some half-a-million cores to the leading supercomputers of the world; where some of them are doing major processor upgrades with this new release; I wouldn't necessarily say that it's the most IMPORTANT market. Important, yes. But MOST important...I dunno.
Looking forward to more HPC benchmark results.
Also, you might have to play with thread schedule/process affinity (masks) to make it work right.
See the Techreport article.
JohanAnandtech - Thursday, November 17, 2011 - link
Are you talking about the Euler3D benchmark?And yes, by any metric (revenue, servers sold) the virtualization market is the most important one for servers. Depending on the report 60 to 80% of the servers are bought to be virtualized.
alpha754293 - Tuesday, November 15, 2011 - link
Folks: chip-multithreading (CMT) is nothing new.I would explain it this way: it is the physical, hardware manifestation of simultaneous multi-threading (SMT). Intel's HTT is SMT.
IBM's POWER (since I think as early as POWER4), Sun/Oracle/UltraDense's Niagara (UltraSPARC T-series), maybe even some of the older Crays were all CMT. (Don't quote me on the Crays though. MIPS died before CMT came out. API WOULD have had it probably IF there had been an EV8).
But the way I see it - remember what a CPU IS: it's a glorified calculator. Nothing else/more.
So, if it can't calculate, then it doesn't really do much good. (And I've yet to see an entirely integer-only program).
Doing integer math is fairly easy and straightforward. Doing floating-point math is a LOT harder. If you check the power consumption while solving a linear algebra equation using Gauss elimination (parallelized or using multiple instances of the solver); I can guarantee you that you will consume more power than if you were trying to run VMs.
So the way I see it, if a CPU is a glorified calculator, then a "core" is where/whatever the FPU is. Everything else is just ancillary and that point.
mino - Wednesday, November 16, 2011 - link
1) Power is NOT CMT, it allways was a VERY(even by RISC standards) wide SMT design.2) Niagara is NOT a CMT. It is interleaved multipthreading with SMT on top.
Bulldozer indeed IS a first of its kind. With all the associated advantages(future scaling) and disadvantages(alfa version).
There is a nice debate somewhere on cpu.arch groups from the original author(think 1990's) of the CMT concept.