The Bulldozer Aftermath: Delving Even Deeper
by Johan De Gelas on May 30, 2012 1:15 AM ESTThe Front End: Branch Prediction
Bulldozer's branch prediction units have been described in many articles. Most insiders agree that Bulldozer's decoupled branch predictor is a step forward from the K10's multi-level predictor. A better predictor might reduce the branch misprediction rate from 5 to 4%, but that is not the end of the story. Here's a quick rundown of the branch prediction capabilities of various CPU architectures.
| Branch Prediction | |||||
| Architecture | Branch Misprediction Penalty | ||||
| AMD K10 (Barcelona, Magny-Cours) | 12 cycles | ||||
| AMD Bulldozer | 20 cycles | ||||
| Pentium 4 (NetBurst) | 20 cycles | ||||
| Core 2 (Conroe, Penryn) | 15 cycles | ||||
| Nehalem | 17 cycles | ||||
| Sandy Bridge | 14-17 cycles | ||||
The numbers above show the minimum branch misprediction penalty, and the fact is that the Bulldozer architecture has a branch misprediction penalty that is 66% higher than the previous generation. That means that the branch prediction of Bulldozer must correctly predict 40% of the pesky branches that were mispredicted by the K10 to compensate (at the same clock). Unfortunately, that kind of massive branch prediction improvement is almost impossible to achieve.
Quite a few people have commented that Bulldozer is AMD's version of Intel's Pentium 4: it has a long pipeline, with high branch misprediction penalties, and it's built for high clock speeds that it cannot achieve. The table above seems to reinforce that impression, but the resemblance between Bulldozer and NetBurst is very superficial.
The minimum branch prediction penalty of the Bulldozer chip is indeed in the same range as Pentium 4. However, the maximum penalty could be a horrifying 100 cycles or more on the P4, while it's a lot lower on Bulldozer. In most common scenarios, the Bulldozer's branch misprediction penalty will be below 30 cycles.
Secondly, the Pentium 4's pipeline was 28 ("Willamette") to 39 ("Prescott") cycles. Bulldozer's pipeline is deep, but it's not that deep. The exact number is not known, but it's in the lower twenties. Really, Bulldozer's pipeline length is not that much higher than Intel's Nehalem or Sandy Bridge architectures (around 16 to 19 stages). The big difference is that the introduction of the µop cache (about 6KB) in Sandy Bridge can reduce the typical branch misprediction to 14 cycles. Only when the instruction is not found in the µop cache and must be fetched from the L1 data cache will the branch misprediction penalty increase to about 17 cycles. So on average, even if the efficiency of Bulldozer's and Sandy Bridge's branch predictors is more or less the same, Sandy Bridge will suffer a lot less from mispredictions.
The Front End: Shared Decoders
Quite a few reviewers, including our own Anand, have pointed out that two integer cores in Bulldozer share four decoders, while two integer cores in the older “K10” architecture each get three decoders. Two K10 cores thus have six decoders, while two Bulldozer cores only have four. Considering that the complexity of the x86 ISA leads to power hungry decoders, reducing the power by roughly 1/3 (e.g. four decoders instead of six for dual-core) with a small single-threaded performance hit is a good trade off if you want to fit 16 of these integer cores in a power envelope of 115W. Instead of 48 decoders, Bulldozer tries to get by with just 32.
The single-threaded performance disadvantage of sharing four decoders between two integer cores could have been lessened somewhat by x86 fusion (test + jump and CMP + jump; Intel calls this macro-op fusion) in the pre-decoding stages. Intel first introduced this with their “Core” architecture back in 2006. If you are confused by macro-ops and micro-ops fusion, take a look here.
However AMD decided to introduce this kind of fusion in Bulldozer later in the decoding pipeline than Intel, where x86 branch fusion is already present in the predecoding phases. The result is that the decoding bandwidth of all Intel CPUs since Nehalem has been up to five (!) x86-64 instructions, while x86 branch fusion does not increase the maximum decode rate of a Bulldozer module.
This is no trifle, as on average this kind of x86 fusion can happen once every ten x86 instructions. So why did AMD let this chance to improve the effective decoding rate pass even if that meant creating a bottleneck in some applications? The most likely reason is that doing this prior to decoding increases the complexity of the chip, and thus the power consumption. Even if AMD's version of x86 branch fusion does not increase the decoding bandwidth, it still offers advantages:
- Increased dispatch bandwidth
- Reduced scheduler queue occupancy
- Faster branch misprediction recovery
The first two increase performance without any extra (or very minimal) power consumption, the last one increases performance and reduces power consumption. AMD preferred to get more cores in the same power envelop over higher decode bandwidth and thus single-threaded performance.
Mark of Hardware.fr compared the performance of a four module CPU with only one core per module enabled with the standard configuration (two integer cores per module). Lightly threaded games were 3-5% faster, which is the first indication that the front end might be something of a bottleneck for some high IPC workloads, but not a big one.
The Memory Subsystem
One of the most important features of Intel's Core architecture was its speculative out-of-order memory pipeline. It gave the Core architecture a massive improvement in many integer benchmarks over the K8, which had a strictly in order pipeline. Barcelona improved this a bit by bringing the K10 to the level of the much older PIII architecture: out of order, but not speculative. Bulldozer now finally has memory disambiguation, a feature which Intel introduced in 2006 in their Core architecture, but there's more to the story.
Bulldozer can have up to 33% more memory instructions in flight, and each module (two integer stores) can do four load/stores per cycle. It's clear that AMD’s engineers have invested heavily in Memory Level Parallelism (MLP). Considering that MLP is often the most important bottleneck in server workloads, this is yet another sign that Bulldozer is targeted at the server world. In this particular area of its architecture, Bulldozer can even beat the Westmere Intel CPUs: two threads on top of the current Intel architecture have only 2 load/stores available and have to share the L1 data cache bandwidth.
The memory controller is improved too, as you can see in the stream benchmark results below. For details about our Stream binary, check here.
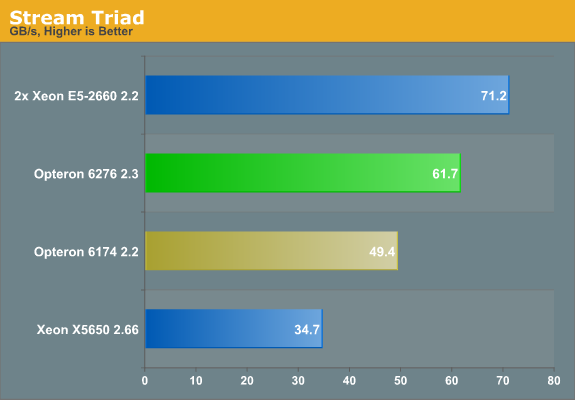
Bandwidth is 25% higher than Barcelona, while the clock speed of the RAM modules has only increased by 20%. Clearly, the Orochi die of the Opteron 6200 has a better memory controller than the Opteron 6100. The memory controller and load/store units are among the strongest parts of the Bulldozer architecture.








84 Comments
View All Comments
shodanshok - Thursday, May 31, 2012 - link
Mmm... the link was malformed in the previous message.The correct one is: http://www.ilsistemista.net/index.php/hardware-ana...
Thanks.
name99 - Thursday, May 31, 2012 - link
"First of all, in most applications, an OOO processor can easily hide the 4-cycle latency of an L1 cache."I know you guys are interested in the question --- why does Bulldozer frequently suck? --- rather than the question ---why is Sandy Bridge so much better? --- but it is this latter question that interests me the most.
What strikes me, on going through all this data (including information that is NOT in the article, and on my experience back in the day when I was writing assembly and counting cycles) is that the "eventual cost" of misses that go all the way to RAM is not covered in the article, and I suspect this is a large part of the issue.
What I mean here is the following: consider an extremely simple model --- an L1 hit takes 1 cycle, an L1 miss that goes to RAM takes 100 cycles. Then a 97% L1 hit rate takes a total of basically 400 cycles; a 99% L1 hit rate takes 200 cycles --- apparently minor differences have a huge effect! But that's not the point I want to focus on.
Let's make the model more complicated. First let's make L1 hit cost more realistic --- 4 cycles. As the article says, this is, for the most part, trivially hidden by the OoO engine. But then why can't the OoO engine also hide all or most of the cost of all those cycles to RAM?
And that, I think, is where the Intel advantage is. They do such a good job with their OoO engine.
At a gross level, OoO engines all look kinda the same --- look at a PPC 750 and an IB and, at a superficial level, they look similar. But firstly the IB has just so much larger buffers (what, 168 or so, compared to the 750s what, 6 or so) that, of course, it has a vastly larger stock of instructions it can keep chewing through as it waits for the RAM.
But, you say, AMD also has large buffers now. Yes, but it's not only the raw buffers. Whenever you start looking at these chips, you discover all sorts of weird limitations on what they can actually do to use all those buffers. I've no idea what the current exact limitations are, but the sort of thing you would have in the past is that maybe all the buffers are flushed on an interrupt or system call; or there'd be strange conditions that could occur where, although in theory the integer engine could keep going past a blocking FP instruction, it turned out to be easier to prevent some race condition by freezing the integer engine under these conditions.
Secondly while you're executing other instructions, waiting on your RAM, you may well execute a few more load/store instructions that again miss in RAM. How well do you handle these? Can you just keep firing out these load/stores, or do you block at the second (or third, or fourth)? Frequently these load-stores refer to the same cache-line that's already in play from the first L1 miss, and how do you handle that? the truly dumb thing, of course, is to send out ANOTHER memory request. Smarter is to suppress that, but you're still using load-store entries in the main "miss to RAM" data structures. Smarter still is to be aware that this line will be coming eventually, and use auxiliary data structures to hold info about this load/store.
It's these sorts of technical details, which don't appear in the gross specs (and sometimes not even in the detailed CPU descriptions) that make so much difference. They are obviously astonishingly difficult to get right. Intel has the manpower to worry about every one of them, AMD does not.
Point is --- if I had to look for a single difference between the the two, that's what I'd be looking at --- how much time is REALLY wasted waiting on DRAM in SB vs on Bulldozer.
misiu_mp - Monday, June 11, 2012 - link
It is the compiler's and Out-Of-Order engine's job to order loads, stores and other instructions to minimize the total execution time.So making sure no stupid and unnecessary loads are being committed is what the OOO mechanism normally does.
There is no reason to suspect it is fundamentally broken in Bulldozer.
IceDread - Friday, June 1, 2012 - link
It really is simple, Amd did a Huge mistake.The product is a bust, simple as that.
The next generation or the generations after that might be a whole different matter, but guess what? No one cares. It wont help the poor souls that bought this busted product.
It's annoying that Amd could not do better because now Intel reigns supreme and competes with itself .
mikato - Friday, June 1, 2012 - link
I know I shouldn't feed the trolls but...You say next generations might be a whole different matter - well what do you think is the point of learning about the Bulldozer architecture? The next generations are based on it.
IceDread - Monday, June 4, 2012 - link
What is the point of releasing a product that does not outperform it's predecessor?Hope that people will purchase the product anyway and learn it?
Which companies would be interested in this, how many? Why would they invest money into this?
_vor_ - Saturday, June 2, 2012 - link
Yes. I too would be interested in exactly what aspects you think Bulldozer failed and your design ideas and approach on how you would fix them. Do tell.wiyosaya - Friday, June 1, 2012 - link
Personally, I think it is always nice to see in-depth articles like this that explain the details of the structure of a processor.To me, it sounds like AMD has a foundation that with a few well-directed tweaks, may put them in contention with Intel again in the CPU arena. Though AMD has said that they are through competing with Intel, I truly hope this is not the case. Perhaps this is a marketing tactic remove focus from themselves after the enthusiast arena panned BD and its siblings.
I've built my systems with AMD for a long time; however, this time I went with Intel because I thought they had the better value. Perhaps the future will bring me back to AMD, however, I cannot see doing so right now simply because Intel has become the "value" line over AMD.
With an i7-3820 in my most recent rig, I think I picked the SB-E value processor. I run more than games, and some of what I run takes advantage of quad-channel memory.
In any event, I'm set for a while. Perhaps AMD will once again produce a superior product by the time I am ready for my next build.
jamyryals - Friday, June 1, 2012 - link
What a great read, thanks!SocketF - Friday, June 1, 2012 - link
Hi Johan,thanks for the test, it is great.
However, on page 9 you have some trouble with percentage calculations. You wrote:
quote:
-------------------
We get a 65% speed up (2x 0.71 vs 0.86), which is somewhat lower than the 80% predicted by the AMD slides discussing CMT.
-------------------
This numbers are totally correct and within AMD's predictions. AMD promised 80% performance for the CMT-Bulldozer module, compared to an hypothetical Bulldozer CMP core, i.e. 2 (single) cores.
So you have to double your single-thread results, to get the score of 2 (single) Bulldozer cores (2 CMP cores). That gives: 0.86 x 2 = 1.72
Now compare that to the real performance of 2 CMT cores of one module, which is 0.71 x 2 = 1.42
1.42 are 82.6% of 1.72, which is better than AMD's 80% claim. Thus their claim holds. Everything's fine, don't worry.
Source of AMD's claim is e.g. here:
http://techreport.com/r.x/bulldozer-uarch/bulldoze...
(sorry, didn't find it on anandtech)
Please update your article accordingly.
Oh and one last question, why did you add up the SMT scores but not the CMT scores? Seems odd, an IPC of "two threads", This is just weired. Furthermore it is somehow useless, because you cannot compare it directly with the CMT scores. A diagram should visualize the results not force the reader to do some re-calculations.
Thanks again
Erik