The Bulldozer Aftermath: Delving Even Deeper
by Johan De Gelas on May 30, 2012 1:15 AM ESTThe Front End: Branch Prediction
Bulldozer's branch prediction units have been described in many articles. Most insiders agree that Bulldozer's decoupled branch predictor is a step forward from the K10's multi-level predictor. A better predictor might reduce the branch misprediction rate from 5 to 4%, but that is not the end of the story. Here's a quick rundown of the branch prediction capabilities of various CPU architectures.
| Branch Prediction | |||||
| Architecture | Branch Misprediction Penalty | ||||
| AMD K10 (Barcelona, Magny-Cours) | 12 cycles | ||||
| AMD Bulldozer | 20 cycles | ||||
| Pentium 4 (NetBurst) | 20 cycles | ||||
| Core 2 (Conroe, Penryn) | 15 cycles | ||||
| Nehalem | 17 cycles | ||||
| Sandy Bridge | 14-17 cycles | ||||
The numbers above show the minimum branch misprediction penalty, and the fact is that the Bulldozer architecture has a branch misprediction penalty that is 66% higher than the previous generation. That means that the branch prediction of Bulldozer must correctly predict 40% of the pesky branches that were mispredicted by the K10 to compensate (at the same clock). Unfortunately, that kind of massive branch prediction improvement is almost impossible to achieve.
Quite a few people have commented that Bulldozer is AMD's version of Intel's Pentium 4: it has a long pipeline, with high branch misprediction penalties, and it's built for high clock speeds that it cannot achieve. The table above seems to reinforce that impression, but the resemblance between Bulldozer and NetBurst is very superficial.
The minimum branch prediction penalty of the Bulldozer chip is indeed in the same range as Pentium 4. However, the maximum penalty could be a horrifying 100 cycles or more on the P4, while it's a lot lower on Bulldozer. In most common scenarios, the Bulldozer's branch misprediction penalty will be below 30 cycles.
Secondly, the Pentium 4's pipeline was 28 ("Willamette") to 39 ("Prescott") cycles. Bulldozer's pipeline is deep, but it's not that deep. The exact number is not known, but it's in the lower twenties. Really, Bulldozer's pipeline length is not that much higher than Intel's Nehalem or Sandy Bridge architectures (around 16 to 19 stages). The big difference is that the introduction of the µop cache (about 6KB) in Sandy Bridge can reduce the typical branch misprediction to 14 cycles. Only when the instruction is not found in the µop cache and must be fetched from the L1 data cache will the branch misprediction penalty increase to about 17 cycles. So on average, even if the efficiency of Bulldozer's and Sandy Bridge's branch predictors is more or less the same, Sandy Bridge will suffer a lot less from mispredictions.
The Front End: Shared Decoders
Quite a few reviewers, including our own Anand, have pointed out that two integer cores in Bulldozer share four decoders, while two integer cores in the older “K10” architecture each get three decoders. Two K10 cores thus have six decoders, while two Bulldozer cores only have four. Considering that the complexity of the x86 ISA leads to power hungry decoders, reducing the power by roughly 1/3 (e.g. four decoders instead of six for dual-core) with a small single-threaded performance hit is a good trade off if you want to fit 16 of these integer cores in a power envelope of 115W. Instead of 48 decoders, Bulldozer tries to get by with just 32.
The single-threaded performance disadvantage of sharing four decoders between two integer cores could have been lessened somewhat by x86 fusion (test + jump and CMP + jump; Intel calls this macro-op fusion) in the pre-decoding stages. Intel first introduced this with their “Core” architecture back in 2006. If you are confused by macro-ops and micro-ops fusion, take a look here.
However AMD decided to introduce this kind of fusion in Bulldozer later in the decoding pipeline than Intel, where x86 branch fusion is already present in the predecoding phases. The result is that the decoding bandwidth of all Intel CPUs since Nehalem has been up to five (!) x86-64 instructions, while x86 branch fusion does not increase the maximum decode rate of a Bulldozer module.
This is no trifle, as on average this kind of x86 fusion can happen once every ten x86 instructions. So why did AMD let this chance to improve the effective decoding rate pass even if that meant creating a bottleneck in some applications? The most likely reason is that doing this prior to decoding increases the complexity of the chip, and thus the power consumption. Even if AMD's version of x86 branch fusion does not increase the decoding bandwidth, it still offers advantages:
- Increased dispatch bandwidth
- Reduced scheduler queue occupancy
- Faster branch misprediction recovery
The first two increase performance without any extra (or very minimal) power consumption, the last one increases performance and reduces power consumption. AMD preferred to get more cores in the same power envelop over higher decode bandwidth and thus single-threaded performance.
Mark of Hardware.fr compared the performance of a four module CPU with only one core per module enabled with the standard configuration (two integer cores per module). Lightly threaded games were 3-5% faster, which is the first indication that the front end might be something of a bottleneck for some high IPC workloads, but not a big one.
The Memory Subsystem
One of the most important features of Intel's Core architecture was its speculative out-of-order memory pipeline. It gave the Core architecture a massive improvement in many integer benchmarks over the K8, which had a strictly in order pipeline. Barcelona improved this a bit by bringing the K10 to the level of the much older PIII architecture: out of order, but not speculative. Bulldozer now finally has memory disambiguation, a feature which Intel introduced in 2006 in their Core architecture, but there's more to the story.
Bulldozer can have up to 33% more memory instructions in flight, and each module (two integer stores) can do four load/stores per cycle. It's clear that AMD’s engineers have invested heavily in Memory Level Parallelism (MLP). Considering that MLP is often the most important bottleneck in server workloads, this is yet another sign that Bulldozer is targeted at the server world. In this particular area of its architecture, Bulldozer can even beat the Westmere Intel CPUs: two threads on top of the current Intel architecture have only 2 load/stores available and have to share the L1 data cache bandwidth.
The memory controller is improved too, as you can see in the stream benchmark results below. For details about our Stream binary, check here.
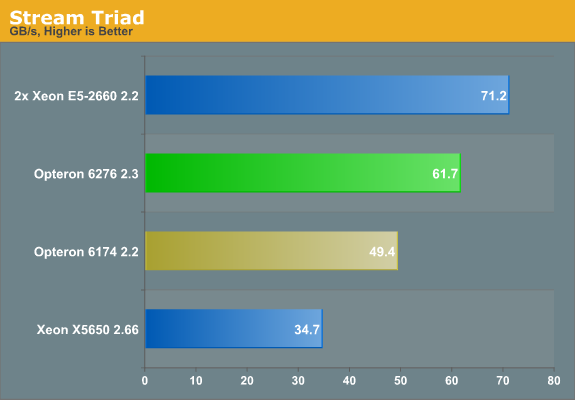
Bandwidth is 25% higher than Barcelona, while the clock speed of the RAM modules has only increased by 20%. Clearly, the Orochi die of the Opteron 6200 has a better memory controller than the Opteron 6100. The memory controller and load/store units are among the strongest parts of the Bulldozer architecture.








84 Comments
View All Comments
Homeles - Wednesday, May 30, 2012 - link
This. Read 3rd party reviews (like AnandTech!) -- several of them -- and draw your conclusions from there. That's pretty much the point of reviews; if marketing teams could provide honest, reliable benchmarks over a wide range of applications, we'd have little need for 3rd party reviews.Mugur - Thursday, May 31, 2012 - link
Well... they actually did!moravista - Wednesday, May 30, 2012 - link
Great article Johan! I have been reading your articles since the Pentium III / K6-2 days and have really enjoyed them! Thanks for sharing your insight! Keep 'em coming!JohanAnandtech - Friday, June 1, 2012 - link
Great to hear from you. Did you used to participate at the different forums on a different callsign?muy - Wednesday, May 30, 2012 - link
i want a phenom II x4 980+ on 32 nm. this whole idea of "lets put as many crippled dual cores on a die and smack a level 3 cache on top and call it out next cpu" is utter crap stuff that doesn't multi thread well (95 % of all stuff).6 core bulldozer i bought to replace my amd x3 450 is slower than the chip i wanted to replace at the same clock speed. now i have a shiny asus rog mb, a x3 450 powering it, and a 6 core bulldozer gathering dust. what a waste of money that was.
shame i can't find any x4 970+'s anymore and amd is to foolhardy to keep manufacturing their best gaming cpu's, let alone do a shrink on them to 32 nm.
i can only imagine how much better a phenom 2 x4 9xx, default clocked at 4.2 ghz+ would be than any bulldozer. (and how much cheaper to manufacture considering the die size compared to the die size of bulldozer).
i just don't understand amd.
Roland00Address - Wednesday, May 30, 2012 - link
Microcenter has these following processors1045t six core for $99
965 quad core black edition for $99
960t quad core black edition for $89 (this model is a disabled six core and has a possibility of unlocking to a 6 core. The 960t is a clearance processor so it is while supplies last.
fic2 - Thursday, May 31, 2012 - link
Those are all 45 nm. He is wanting a tick - a die shrunk Phenom II.Would have to agree with him. If AMD would do a die shrink they would have a killer product - assuming GloFo didn't f*ck it up.
muy - Wednesday, May 30, 2012 - link
bulldozer doesn't do single threaded, highly branching (cough games cough) stuff well.and before you say "some games use multiple cores", i'll say that 1 core running on 100 % and 7 cores at 5 % is not a good use of multi threading.
(1 * 100) + (7 * 5) = (1 * 100) + (1 * 35) - 1.35 cores used. this means that a DUAL core going at 10 % higher speed than the exampled 8 core would be 10 % faster than the 8 core 'using' it's 8 cores.
clock speed + ipc are the only things that matter 90% + of the time for games.
wolfman3k5 - Wednesday, May 30, 2012 - link
People don't buy CPUs based on theoretical performance, ideology or brand loyalty (OK, some fan-boys do). Most of us are not computer engineers, and even if we where, it wouldn't matter, because at the end of the day only the end result would matter: performance, efficiency and price. Just like I didn't buy Intel because it looked good on paper back in the glory days of AMD (cca. 2005). So no matter how deep and involved these articles are, AMD still trails Intel when it comes to performance, and it will do so until their lazy and incompetent CPU engineers will get off their lazy buts and start working. The sole reason why Bulldozer was such a massive fail was because most of the design process was highly automated. So, stop slacking and start working lazy AMD engineers!Homeles - Wednesday, May 30, 2012 - link
Being a "lazy" electrical engineer is practically impossible. The amount of work that has to go into making these processors simply function is quite massive. These guys work hard to get to where they are with their careers and work even harder to keep those careers. The margin of error here is also quite huge... a small flaw can create enormous performance penalties.I'd be willing to bet that many, if not most of Bulldozer's shortcomings could be blamed on management. Saying it was "lazy engineers" is callous and ignorant.