The Bulldozer Aftermath: Delving Even Deeper
by Johan De Gelas on May 30, 2012 1:15 AM ESTNext stop: SPEC CPU2006 Int Rate
There is no denying that SPEC CPU2006 was never one of our favorite benchmarks in the Professional IT section of AnandTech. Although it is the standard benchmark of most CPU designers and academic researchers, it is far from a real world benchmark for most professional IT users.
For starters, a typical SPEC CPU2006 benchmark consists of running as many SPEC CPU2006 instances as there are cores available in the machine. The SPEC CPU2006 instances run completely independently from each other, so there are much fewer locks or other synchronization mechanisms at work: the benchmark scales almost perfectly as long as there is enough bandwidth available. Unfortunately, that is not how the majority of business software behaves: databases have high locking overhead and most applications need some synchronization.
Secondly, most of the subtests are related to gaming and simulations (HPC). Typically these applications are much more processing intensive and achieve a higher IPC than your average business application.
Lastly, the source code of the SPEC CPU2006 tests is compiled with extremely aggressively tuned compiler settings and compilers that are less used in the rest of the IT world. Few SPEC CPU2006 results are compiled with gcc and Microsoft's Visual Studio, for example.
However, it would be a step too far to call SPEC CPU2006 useless. From a high level perspective, the scores of SPEC CPU2006 show a strong correlation with L2/L3 cache misses, cache latency, and to a lesser degree branch prediction, just like many business applications. Given similar platforms (like Intel Nehalem and AMD's Shanghai), the CPU SPEC2006 Int score gives a vague idea of which CPU has the most raw integer crunching power, although it overemphasizes memory bandwidth and core count.
To understand the weaknesses and strengths of a certain CPU architecture, even in server workloads, there is no better test than SPEC CPU2006. The first reason is that it has been profiled by so many different people from academia to engineers. If we zoom in on the subtests we can derive a lot of information as we know exactly how these applications behave: there have been lots of performance characterization papers going into great detail.
The second reason is that SPEC CPU2006 tests are compiled with the most optimal compilers and compiler options available at a certain point in time. This gives us some insight into the "real" (e.g. future) potential of a processor. We can exclude the possibility that a processor performs badly because some legacy piece of code is detrimental to the performance. If the CPU cannot score well with these kinds of binaries, it never will!
Auto-parallelization made the normal single-threaded SPEC CPU benchmarks very hard to read. We turn to the rate version instead. Since it scales almost perfectly, it is relatively easy to deduce single-threaded performance from the SPEC rate numbers--on the condition that cache interference and bandwidth bottlenecks do not blur the picture too much, so we have to be careful with those benchmarks that miss the L2 cache a lot. The current CPU2006 int scores are as follows:
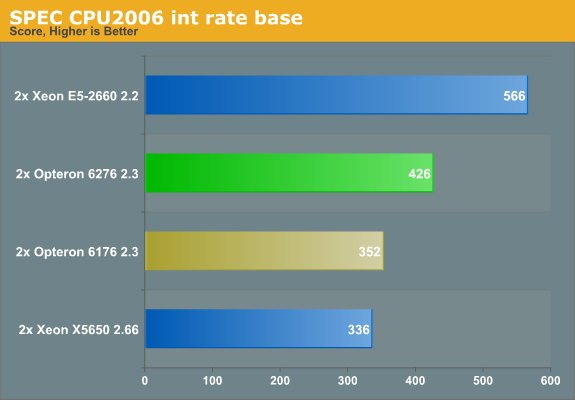
The Xeon E5 is the most efficient clock for clock, core for core. But let us compare the Opteron 6276 (2.3GHz, 16-core Bulldozer) and the Opteron 6176 (2.3GHz, 12-core Magny-Cours) in the subtests.
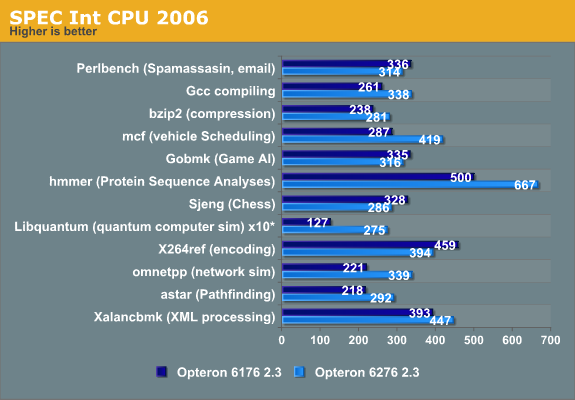
You can immediately derive from these numbers that the "Bulldozer" architecture has a very different architecture profile than Magny-Cours (which was based on the improved Barcelona architecture, Istanbul). Libquantum, omnetpp and mcf show larger performance boosts than you might expect from the 33% higher corecount. These benchmarks show that in some scenarios, Bulldozer can even increase the IPC compared to its predecessor.
We also notice that Bulldozer has some serious weaknesses compared to its predecessor, as performance decreases in the Perlbench, the game AI (gobmk), the chess (Sjeng), and the x264 encoding subtests. And although it is not uncommon that a new architecture fails to beat the previous architecture in every benchmark, it is not a good sign that even a 33% core count cannot overcome the IPC decrease in a very good scaling benchmark. If we try to understand what makes these subtests different from the others, we can get an idea of what kind of software makes Bulldozer choke. This in turn can help us to understand if relatively small tweaks can help future Opterons.








84 Comments
View All Comments
Spunjji - Wednesday, June 6, 2012 - link
Agreed. That will be nice!haukionkannel - Wednesday, May 30, 2012 - link
Very nice article! Can we get more thorough explanation about µop cache? It seems to be important part of Sandy bridge and you predict that it would help bulldoser...How complex it is to do and how heavily it has been lisensed?
JohanAnandtech - Thursday, May 31, 2012 - link
Don't think there is a license involved. AMD has their own "macro ops" so they can do a macro ops cache. Unfortunately I can not answer your question of the top of head on how easy it is to do, I would have to some research first.name99 - Thursday, May 31, 2012 - link
Oh for fsck's sake.The stupid spam filter won't let me post a URL.
Do a google search for
sandy bridge Real World Technologies
and look at the main article that comes up.
SocketF - Friday, June 1, 2012 - link
It is already planned, AMD has a patent for sth like that, google for "Redirect Recovery Cache". Dresdenboy found it already back in 2009:http://citavia.blog.de/2009/10/02/return-of-the-tr...
The BIG Question is:
Why did AMD not implement it yet?
My guess is that they were already very busy with the whole CMT approach. Maybe Streamroller will bring it, there are some credible rumors in that direction.
yuri69 - Wednesday, May 30, 2012 - link
Howdy,FOA thanks for the effort to investigate the shortcomings of this march :)
Quoting M. Butler (BD's chief architect): 'The pipeline within our latest "Bulldozer" microarchitecture is approximately 25 percent deeper than that of the previous generation architectures. ' This gives us 12 stages on K8/K10 => 12 * 1.25 = 15.
Btw all the major and significant architectural improvements & features for the upcoming BD successor line were set in stone long time ago. Remember, it takes 4-5 years for a general purpose CPU from the initial draft to mass availability. The stage when you can move and bend stuff seems to be around half of this period.
BenchPress - Wednesday, May 30, 2012 - link
"This means that Bulldozer should be better at extracting ILP (Instruction Level Parallelism) out of code that has low IPC (Instructions Per Clock)."This should be reversed. ILP is inherent to the code, and it's the hardware's job to extract it and achieve a high IPC.
Arnulf - Wednesday, May 30, 2012 - link
Ugh, so much crap in a single article ... this should never have been posted on AT.You weren't promised anything. You came across a website put up by some "fanboy" dumbass and you're actually using it as a reference. Why not quote some actual references (such as transcripts of the conference where T. Seifert clearly stated that gains are expected to be in line with core number increase, i.e. ~33%) instead of rehashing this Fruehe nonsense ?
erikvanvelzen - Wednesday, May 30, 2012 - link
Yes AMD totally set out to make a completely new architecture with a massive increase in transistors per core but 0 gains in IPC.Don't fool yourself.
Homeles - Wednesday, May 30, 2012 - link
It's a more intelligent analysis than your sorry ass could ever produce. Getting hung up on one quote... really?