The Bulldozer Aftermath: Delving Even Deeper
by Johan De Gelas on May 30, 2012 1:15 AM ESTNext stop: SPEC CPU2006 Int Rate
There is no denying that SPEC CPU2006 was never one of our favorite benchmarks in the Professional IT section of AnandTech. Although it is the standard benchmark of most CPU designers and academic researchers, it is far from a real world benchmark for most professional IT users.
For starters, a typical SPEC CPU2006 benchmark consists of running as many SPEC CPU2006 instances as there are cores available in the machine. The SPEC CPU2006 instances run completely independently from each other, so there are much fewer locks or other synchronization mechanisms at work: the benchmark scales almost perfectly as long as there is enough bandwidth available. Unfortunately, that is not how the majority of business software behaves: databases have high locking overhead and most applications need some synchronization.
Secondly, most of the subtests are related to gaming and simulations (HPC). Typically these applications are much more processing intensive and achieve a higher IPC than your average business application.
Lastly, the source code of the SPEC CPU2006 tests is compiled with extremely aggressively tuned compiler settings and compilers that are less used in the rest of the IT world. Few SPEC CPU2006 results are compiled with gcc and Microsoft's Visual Studio, for example.
However, it would be a step too far to call SPEC CPU2006 useless. From a high level perspective, the scores of SPEC CPU2006 show a strong correlation with L2/L3 cache misses, cache latency, and to a lesser degree branch prediction, just like many business applications. Given similar platforms (like Intel Nehalem and AMD's Shanghai), the CPU SPEC2006 Int score gives a vague idea of which CPU has the most raw integer crunching power, although it overemphasizes memory bandwidth and core count.
To understand the weaknesses and strengths of a certain CPU architecture, even in server workloads, there is no better test than SPEC CPU2006. The first reason is that it has been profiled by so many different people from academia to engineers. If we zoom in on the subtests we can derive a lot of information as we know exactly how these applications behave: there have been lots of performance characterization papers going into great detail.
The second reason is that SPEC CPU2006 tests are compiled with the most optimal compilers and compiler options available at a certain point in time. This gives us some insight into the "real" (e.g. future) potential of a processor. We can exclude the possibility that a processor performs badly because some legacy piece of code is detrimental to the performance. If the CPU cannot score well with these kinds of binaries, it never will!
Auto-parallelization made the normal single-threaded SPEC CPU benchmarks very hard to read. We turn to the rate version instead. Since it scales almost perfectly, it is relatively easy to deduce single-threaded performance from the SPEC rate numbers--on the condition that cache interference and bandwidth bottlenecks do not blur the picture too much, so we have to be careful with those benchmarks that miss the L2 cache a lot. The current CPU2006 int scores are as follows:
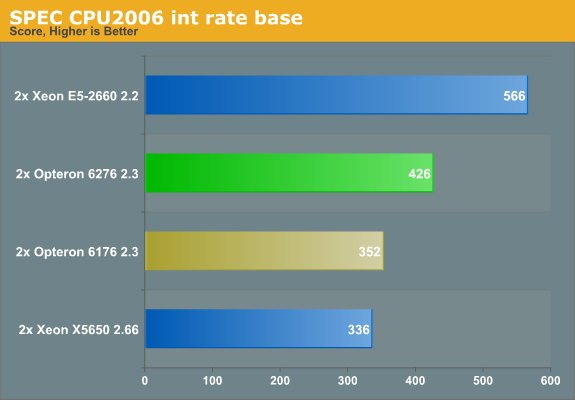
The Xeon E5 is the most efficient clock for clock, core for core. But let us compare the Opteron 6276 (2.3GHz, 16-core Bulldozer) and the Opteron 6176 (2.3GHz, 12-core Magny-Cours) in the subtests.
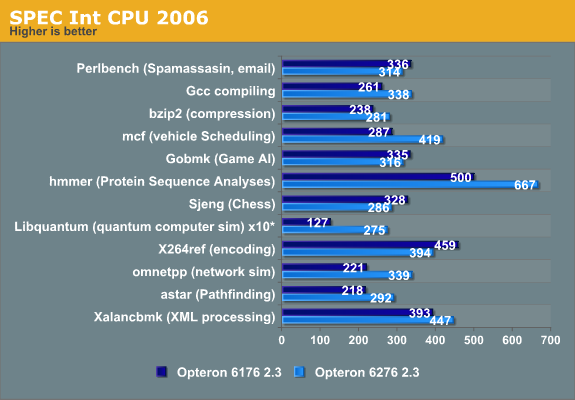
You can immediately derive from these numbers that the "Bulldozer" architecture has a very different architecture profile than Magny-Cours (which was based on the improved Barcelona architecture, Istanbul). Libquantum, omnetpp and mcf show larger performance boosts than you might expect from the 33% higher corecount. These benchmarks show that in some scenarios, Bulldozer can even increase the IPC compared to its predecessor.
We also notice that Bulldozer has some serious weaknesses compared to its predecessor, as performance decreases in the Perlbench, the game AI (gobmk), the chess (Sjeng), and the x264 encoding subtests. And although it is not uncommon that a new architecture fails to beat the previous architecture in every benchmark, it is not a good sign that even a 33% core count cannot overcome the IPC decrease in a very good scaling benchmark. If we try to understand what makes these subtests different from the others, we can get an idea of what kind of software makes Bulldozer choke. This in turn can help us to understand if relatively small tweaks can help future Opterons.








84 Comments
View All Comments
ArteTetra - Wednesday, May 30, 2012 - link
"A core this complex in my opinion has not been optimized to its fullest potential. Expect better performance when AMD introduces later steppings of this core with regard to power consumption and higher clock frequencies."You don't say?
JohanAnandtech - Thursday, May 31, 2012 - link
A quote by a reader, not ours :-). The idea is probably that Bulldozer was AMD's very first implementation of their new architecture.haplo602 - Wednesday, May 30, 2012 - link
now this was a great read. finaly something interesting (the consumer benchmarks are NOT intereseted anymore for me).I hope there will be a differential analysis once you have Piledriver CPUs available.
JohanAnandtech - Thursday, May 31, 2012 - link
Piledriver analysis: definitely. Thanks for the encouraging words :-)mikato - Friday, June 1, 2012 - link
I agree - great critical thinking in this article! This subject definitely needed more research.Spunjji - Wednesday, June 6, 2012 - link
+1. This is the sort of thing I come here for!Beenthere - Wednesday, May 30, 2012 - link
Expecting Vishera to be an Intel killer is foolish as it's not going to happen and there is no need for it to happen. Ivy Bridge is very much like FX in that it's only 5% faster than SB and runs hot. At least FX chips OC and scale well unlike Ivy Bridge.If AMD can use some of the techniques imployed in Trinity they should be able to get a 15+% improvement over the FX CPUs. This combined with higher clockspeeds now that GloFo has sorted 32nm production should provide a nice performance bump in Vishera.
95% of consumers do not buy the fastest, most over-hyped and over-priced CPU on the planet for their PC or server apps. Mainstream use is what AMD is shooting for at the moment and doing pretty well at it. Eventually they will release APUs for all PC market segments that perform well, use less power and cost less than discrete CPU/GPU combo. THAT is what 95% of the X86 world will be using.
Homeles - Wednesday, May 30, 2012 - link
"Ivy Bridge is very much like FX in that it's only 5% faster than SB and runs hot"I think you need to go read about Intel's tick-tock strategy.
Also, unlike Bulldozer, Ivy Bridge was a step forward. A small one, but performance per watt went up, while with Bulldozer it often went backwards.
Process maturity from GloFo will help, but probably not as much as you would think.
Finally, "95% of users" aren't going to benefit best from a processor built with server workloads in mind. Even with server workloads, Bulldozer fails to deliver. APUs are definitely the future, but keep in mind that Intel's had an APU out for as long as AMD has. If you think that AMD's somehow going to pull a fast one on Intel, you're delusional. Intel and Nvidia as well are very, very well aware of heterogeneous computing.
The_Countess - Wednesday, May 30, 2012 - link
looking at how much the performance per watt went up with piledriver compared with llano, I think they''ll have a lot more headroom on the desktop and server space to increase the clock frequencies to where they are suppose to be with the bulldozer launch.Homeles - Wednesday, May 30, 2012 - link
Yeah, Piledriver will likely perform the way AMD had intended Bulldozer to perform.