The Bulldozer Aftermath: Delving Even Deeper
by Johan De Gelas on May 30, 2012 1:15 AM ESTThe Front End: Branch Prediction
Bulldozer's branch prediction units have been described in many articles. Most insiders agree that Bulldozer's decoupled branch predictor is a step forward from the K10's multi-level predictor. A better predictor might reduce the branch misprediction rate from 5 to 4%, but that is not the end of the story. Here's a quick rundown of the branch prediction capabilities of various CPU architectures.
| Branch Prediction | |||||
| Architecture | Branch Misprediction Penalty | ||||
| AMD K10 (Barcelona, Magny-Cours) | 12 cycles | ||||
| AMD Bulldozer | 20 cycles | ||||
| Pentium 4 (NetBurst) | 20 cycles | ||||
| Core 2 (Conroe, Penryn) | 15 cycles | ||||
| Nehalem | 17 cycles | ||||
| Sandy Bridge | 14-17 cycles | ||||
The numbers above show the minimum branch misprediction penalty, and the fact is that the Bulldozer architecture has a branch misprediction penalty that is 66% higher than the previous generation. That means that the branch prediction of Bulldozer must correctly predict 40% of the pesky branches that were mispredicted by the K10 to compensate (at the same clock). Unfortunately, that kind of massive branch prediction improvement is almost impossible to achieve.
Quite a few people have commented that Bulldozer is AMD's version of Intel's Pentium 4: it has a long pipeline, with high branch misprediction penalties, and it's built for high clock speeds that it cannot achieve. The table above seems to reinforce that impression, but the resemblance between Bulldozer and NetBurst is very superficial.
The minimum branch prediction penalty of the Bulldozer chip is indeed in the same range as Pentium 4. However, the maximum penalty could be a horrifying 100 cycles or more on the P4, while it's a lot lower on Bulldozer. In most common scenarios, the Bulldozer's branch misprediction penalty will be below 30 cycles.
Secondly, the Pentium 4's pipeline was 28 ("Willamette") to 39 ("Prescott") cycles. Bulldozer's pipeline is deep, but it's not that deep. The exact number is not known, but it's in the lower twenties. Really, Bulldozer's pipeline length is not that much higher than Intel's Nehalem or Sandy Bridge architectures (around 16 to 19 stages). The big difference is that the introduction of the µop cache (about 6KB) in Sandy Bridge can reduce the typical branch misprediction to 14 cycles. Only when the instruction is not found in the µop cache and must be fetched from the L1 data cache will the branch misprediction penalty increase to about 17 cycles. So on average, even if the efficiency of Bulldozer's and Sandy Bridge's branch predictors is more or less the same, Sandy Bridge will suffer a lot less from mispredictions.
The Front End: Shared Decoders
Quite a few reviewers, including our own Anand, have pointed out that two integer cores in Bulldozer share four decoders, while two integer cores in the older “K10” architecture each get three decoders. Two K10 cores thus have six decoders, while two Bulldozer cores only have four. Considering that the complexity of the x86 ISA leads to power hungry decoders, reducing the power by roughly 1/3 (e.g. four decoders instead of six for dual-core) with a small single-threaded performance hit is a good trade off if you want to fit 16 of these integer cores in a power envelope of 115W. Instead of 48 decoders, Bulldozer tries to get by with just 32.
The single-threaded performance disadvantage of sharing four decoders between two integer cores could have been lessened somewhat by x86 fusion (test + jump and CMP + jump; Intel calls this macro-op fusion) in the pre-decoding stages. Intel first introduced this with their “Core” architecture back in 2006. If you are confused by macro-ops and micro-ops fusion, take a look here.
However AMD decided to introduce this kind of fusion in Bulldozer later in the decoding pipeline than Intel, where x86 branch fusion is already present in the predecoding phases. The result is that the decoding bandwidth of all Intel CPUs since Nehalem has been up to five (!) x86-64 instructions, while x86 branch fusion does not increase the maximum decode rate of a Bulldozer module.
This is no trifle, as on average this kind of x86 fusion can happen once every ten x86 instructions. So why did AMD let this chance to improve the effective decoding rate pass even if that meant creating a bottleneck in some applications? The most likely reason is that doing this prior to decoding increases the complexity of the chip, and thus the power consumption. Even if AMD's version of x86 branch fusion does not increase the decoding bandwidth, it still offers advantages:
- Increased dispatch bandwidth
- Reduced scheduler queue occupancy
- Faster branch misprediction recovery
The first two increase performance without any extra (or very minimal) power consumption, the last one increases performance and reduces power consumption. AMD preferred to get more cores in the same power envelop over higher decode bandwidth and thus single-threaded performance.
Mark of Hardware.fr compared the performance of a four module CPU with only one core per module enabled with the standard configuration (two integer cores per module). Lightly threaded games were 3-5% faster, which is the first indication that the front end might be something of a bottleneck for some high IPC workloads, but not a big one.
The Memory Subsystem
One of the most important features of Intel's Core architecture was its speculative out-of-order memory pipeline. It gave the Core architecture a massive improvement in many integer benchmarks over the K8, which had a strictly in order pipeline. Barcelona improved this a bit by bringing the K10 to the level of the much older PIII architecture: out of order, but not speculative. Bulldozer now finally has memory disambiguation, a feature which Intel introduced in 2006 in their Core architecture, but there's more to the story.
Bulldozer can have up to 33% more memory instructions in flight, and each module (two integer stores) can do four load/stores per cycle. It's clear that AMD’s engineers have invested heavily in Memory Level Parallelism (MLP). Considering that MLP is often the most important bottleneck in server workloads, this is yet another sign that Bulldozer is targeted at the server world. In this particular area of its architecture, Bulldozer can even beat the Westmere Intel CPUs: two threads on top of the current Intel architecture have only 2 load/stores available and have to share the L1 data cache bandwidth.
The memory controller is improved too, as you can see in the stream benchmark results below. For details about our Stream binary, check here.
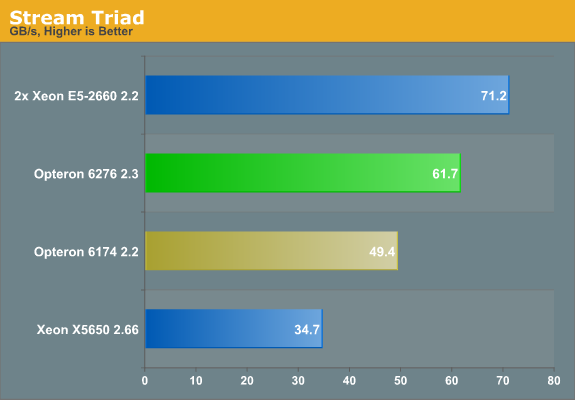
Bandwidth is 25% higher than Barcelona, while the clock speed of the RAM modules has only increased by 20%. Clearly, the Orochi die of the Opteron 6200 has a better memory controller than the Opteron 6100. The memory controller and load/store units are among the strongest parts of the Bulldozer architecture.








84 Comments
View All Comments
Schmide - Wednesday, May 30, 2012 - link
I do remember from some analysis that the L2 cache reads were as slow as main memory. That's great if you hit a L2 cache, but it's not going to buy you anything if it's that slow.SocketF - Wednesday, May 30, 2012 - link
Impossible, you probably mix some things up, maybe latency and bandwidth?Schmide - Wednesday, May 30, 2012 - link
Yup. It was late at night, I was thinking writes. the L1 write through basically makes L1 writes the same as L2 writes.Homeles - Wednesday, May 30, 2012 - link
Not even close. L2 is about 10 times faster than main memory.http://www.anandtech.com/show/4955/the-bulldozer-r...
jcollake - Wednesday, May 30, 2012 - link
Through research here at Bitsum on the AMD Bulldozer platform (specifically the 9150), I found a couple things of interest.First, disabling CPU core parking seems to make a big difference in performance. I believe that by default the CPU core parking is just too aggressive. I wrote a tool to let you enable or disable CPU parking in *real time* without a reboot, so you can test this yourself. It is called ParkControl, http://bitsum.com/about_cpu_core_parking.php . For *me*, it seemed to make a night and day difference.
Second, I am working on a neat little benchmarking tool called ThreadRacer, currently only in alpha prototype. It allows you to really see the effects of these paired cores, and how much it matters that the scheduler is properly aware of them. Take this 1 second or so sample, as seen in the screenshot here (downloads available, but it is an early prototype that I'll quickly be finishing up): http://bitsum.com/forum/index.php/topic,1434.0.htm...
The scheduler update that Microsoft issued of course treats these paired cores as it would a hyper-threaded core. Indeed, the concept is very similar, except perhaps to avoid patents, AMD took the 'share a little' instead of 'share a lot' approach when it comes to shared computational resources. This was the proper way to *quickly* address the issue, but I believe the scheduler is still suboptimal on these processors (likely to be resolved in Windows 8 or a later update to Windows 7/Vista).
For Bulldozer, as you know, they are two real processors, but because they have shared dependencies, the performance can really be drained if the other processor in the 'pair' is busy. You can see the effects from ThreadRacer, the core without its pair busy quickly out-paced the paired cores that were both busy.
jcollake - Wednesday, May 30, 2012 - link
I should have also mentioned that ThreadRacer also allows you to see how a single CPU consuming thread gets swapped around to different cores (the multi-core thread in the utility). This is its other use. The less the thread gets swapped from core to core, the greater the performance will be. It is interesting to compare and contrast the behavior of the scheduler. I fully believe that most the problems with Bulldozer are due to the Windows scheduler, something that could be tested by using linux and replacing the scheduler with a custom one, or an off the shelf alternative that may behave substantially differently than the Windows scheduler.SocketF - Wednesday, May 30, 2012 - link
Some people running BOINC programs have reported that Windows-applications run faster when they use a Linux and WINE or a VM.The Win-scheduler especially hurts AMD chips, because of the huge exclusive caches. If a thread on an intel CPU is switched to another core, it can load the warmed up L2 portion from the L2 inclusive L3.
I did some google-search and it seems that under Linux, each core has its own run-queue, whereas on Windows, there is only one run queue for all cores.
But i didn't delve into it deeply, there are so many different schedulers for Linux, seems to be a complex issue ;-)
Btw. your link to download is off limits for non-members of your discussion board:
-------------------------
Warning!
The topic or board you are looking for appears to be either missing or off limits to you.
Please login below or register an account with Bitsum Forums.
----------------------------
Maybe you can upload it somewhere else?
jcollake - Saturday, September 1, 2012 - link
Sorry for the late reply. First, the forum permissions were fixed. Second, the utility (still in early stages) is included in Process Lasso *and* available here: http://bitsum.com/threadracer.phpeoerl - Wednesday, May 30, 2012 - link
Very interesting article, together with the hardware.fr report there's a lot of information. One question though, if you read commentaries : you didn't speak much about the influence of compilers. This proved to change a lot of things on Linux (see phoronix extensive tests on both ivy bridge and bulldozer depending on compiler used and compiler options, for examplehttp://www.phoronix.com/scan.php?page=article&...
http://www.phoronix.com/scan.php?page=article&...
Benchmark results really change a lot with bulldozer, much more than with ivy or sandy bridge. Do you think AMD lost being oversensitive to compiler optimisations, due to a very original architecture ?
JohanAnandtech - Thursday, May 31, 2012 - link
I deliberately avoided the compiler issues as this would make the article too convoluted. But notice that what we found is not influenced by compiler choice: we find the same indications in SAP and SQL server (compiled by "conservative" compilers and compiler settings) as in CPU CPU 2006, which uses the best optimized settings and compiler as possible.