Apple iPhone 4S: Thoroughly Reviewed
by Anand Lal Shimpi & Brian Klug on October 31, 2011 7:45 PM EST- Posted in
- Smartphones
- Apple
- Mobile
- iPhone
- iPhone 4S
The A5 Architecture & CPU Performance
The original iPhone debuted with a single 412MHz ARM11 core built on a 90nm process. The 3G improved network performance in 2008 but left the SoC untouched. It wasn't until the iPhone 3GS in 2009 that the SoC got a major performance and power update. Apple moved to a 65nm process node, a brand new ARM Cortex A8 based SoC and an upgraded GPU. The A4 released in 2010 once again gave us a process shrink but kept the architecture unchanged.

Apple's A5 SoC
Apple's A5, first introduced with the iPad 2, keeps process technology the same while introducing a brand new CPU and GPU. The A5 integrates two ARM Cortex A9 cores onto a single die. The improvement over the A4 is tremendous. At the single core level, Apple shortened the integer pipeline without reducing clock speed. With a shorter pipeline the A5 gets more done per clock, and without decreasing clock speed the A5 inherently achieves better performance at the same clock. The move to the Cortex A9 also enables out-of-order instruction execution, further improving architectural efficiency. I've heard there's a 20% increase in performance per clock vs. the Cortex A8, but combine that with the fact that you get two A9s vs a single A8 in last year's design and you get a pretty big performance increase.
There are several situations where the A5's two cores deliver a tangible performance benefit over the A4's single core. Like Android, iOS appears to be pretty well threaded. Individual apps and tasks can take advantage of the second core without a recompile or version update. The most obvious example is web browsing.
Mobile Safari is well threaded. Javascript rendering can be parallelized as well as parts of the HTML parsing/rendering process. All of the major Javascript performance benchmarks show a 60 - 70% increase in performance over the A4, which is partially due to the availability of the second core:
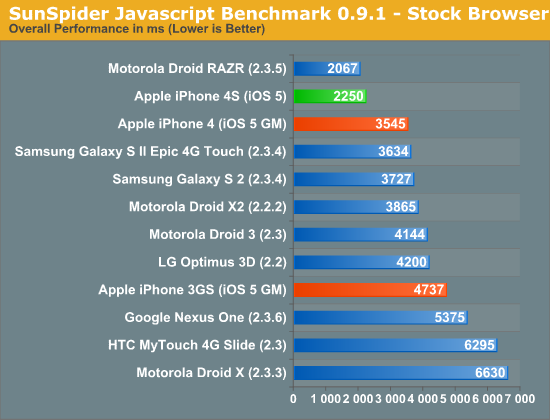

This translates directly into faster page load times. As you can see in the video below, the iPhone 4S (left) loads the AnandTech front page over WiFi in about 5 seconds compared to 9 seconds on the iPhone 4 (right). That's really the best case scenario, the improvement in the next page load time was only about a second (7s vs 8s).
Typical improvements in load time fall in the 10 - 70% range, contributing significantly to the phone feeling snappier than its predecessor. To quantify the improvement I ran through our standard web page loading suite, a test that hits AnandTech, CNN, NYTimes, Engadget, Amazon, Digg and Reddit hosted locally on our lab's network. The average page load time over WiFi for all of the pages is below:
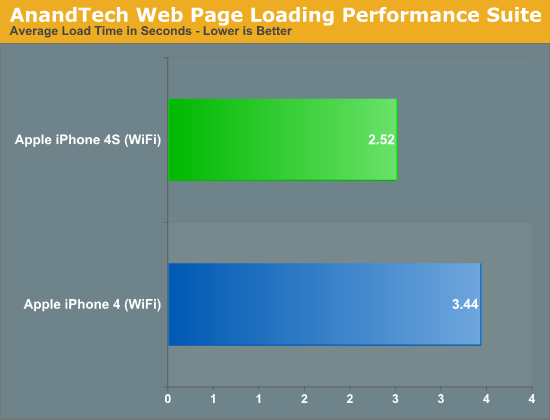
While web page rendering is a natural fit for multiple cores, I was surprised by how poorly threaded some apps ended up being. For example, although I did see performance improvements in exporting edited videos from the iOS version of iMovie, the gains weren't always evident. A quick profile of the app revealed that much of the export process is still single threaded. Just as we've seen on the desktop, there will be some added work necessary to get all apps to utilize multiple cores on iOS.
It's not always performance within an app that saw improvement with the A5: application install and launch times are also much quicker on the 4S. The time to launch Epic's iOS Citadel demo went from 32 seconds on the iPhone 4 to 22 seconds on the 4S. While the iPhone 4 may feel fast enough for many users, the 4S is noticeably faster.
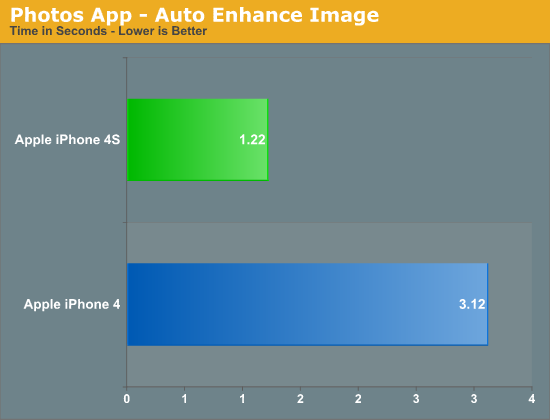
Much of the faster feel comes from by shaving off of seconds here or there. For example, I noticed apps like Messages pop up just slightly quicker on the 4S and you'll see your listing of messages a hair faster than you would on the 4. In the video above you get a brief idea of the sort of subtle improvements I'm talking about. YouTube launches a fraction of a second quicker on the 4S vs the 4.
These subtle decreases in response time are simply icing on the cake. The move from a 4 to a 4S is one of those upgrades that you'll notice right off the bat but will really appreciate if you go back to an iPhone 4 and try to use it. If you do a lot of web browsing on your phone, you'll appreciate the 4S.
I wasn't entirely sure whether or not I could attribute all of these performance improvements to the faster CPU. It's possible that some of the tests I mentioned are IO bound and Apple could have used faster NAND in the 4S. To find out I rounded up a bunch of iPhone 4Ses at all available capacities and measured sequential write speed:
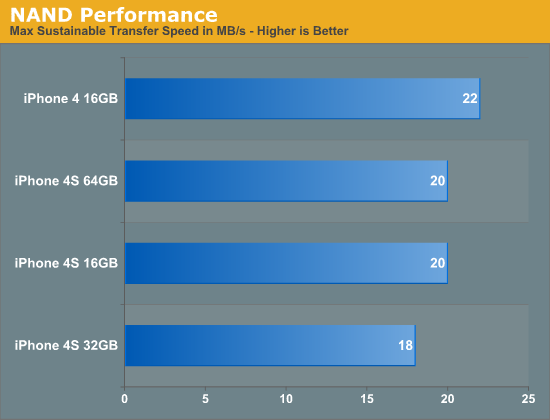
Apple uses multiple sources for NAND so it's possible that you'll see these numbers move around a bit depending on your particular phone. It looks like the iPhone 4S' NAND is no faster than what Apple shipped last year - at least in sequential write speed. The target appears to be 20MB/s and Apple does its best to stay around there. My iPhone 4 is actually pretty quick at 22MB/s but the advantage isn't significant enough to make a huge deal about. I don't have a good way of measuring random IO performance yet but application launch time is largely governed by sequential IO so I don't expect we're seeing gains from anything outside of the CPU and memory bandwidth in the earlier tests.








199 Comments
View All Comments
doobydoo - Friday, December 2, 2011 - link
Its still absolute nonsense to claim that the iPhone 4S can only use '2x' the power when it has available power of 7x.Not only does the iPhone 4s support wireless streaming to TV's, making performance very important, there are also games ALREADY out which require this kind of GPU in order to run fast on the superior resolution of the iPhone 4S.
Not only that, but you failed to take into account the typical life-cycle of iPhones - this phone has to be capable of performing well for around a year.
The bottom line is that Apple really got one over all Android manufacturers with the GPU in the iPhone 4S - it's the best there is, in any phone, full stop. Trying to turn that into a criticism is outrageous.
PeteH - Tuesday, November 1, 2011 - link
Actually it is about the architecture. How GPU performance scales with size is in large part dictated by the GPU architecture, and Imagination's architecture scales better than the other solutions.loganin - Tuesday, November 1, 2011 - link
And I showed it above Apple's chip isn't larger than Samsung's.PeteH - Tuesday, November 1, 2011 - link
But chip size isn't relevant, only GPU size is.All I'm pointing out is that not all GPU architectures scale equivalently with size.
loganin - Tuesday, November 1, 2011 - link
But you're comparing two different architectures here, not two carrying the same architecture so the scalability doesn't really matter. Also is Samsung's GPU significantly smaller than A5's?Now we've discussed back and forth about nothing, you can see the problem with Lucian's argument. It was simply an attempt to make Apple look bad and the technical correctness didn't really matter.
PeteH - Tuesday, November 1, 2011 - link
What I'm saying is that Lucian's assertion, that the A5's GPU is faster because it's bigger, ignores the fact that not all GPU architectures scale the same way with size. A GPU of the same size but with a different architecture would have worse performance because of this.Put simply architecture matters. You can't just throw silicon at a performance problem to fix it.
metafor - Tuesday, November 1, 2011 - link
Well, you can. But it might be more efficient not to. At least with GPU's, putting two in there will pretty much double your performance on GPU-limited tasks.This is true of desktops (SLI) as well as mobile.
Certain architectures are more area-efficient. But the point is, if all you care about is performance and can eat the die-area, you can just shove another GPU in there.
The same can't be said of CPU tasks, for example.
PeteH - Tuesday, November 1, 2011 - link
I should have been clearer. You can always throw area at the problem, but the architecture dictates how much area is needed to add the desired performance, even on GPUs.Compare the GeForce and the SGX architectures. The GeForce provides an equal number of vertex and pixel shader cores, and thus can only achieve theoretical maximum performance if it gets an even mix of vertex and pixel shader operations. The SGX on the other hand provides general purpose cores that work can do either vertex or pixel shader operations.
This means that as the SGX adds cores it's performance scales linearly under all scenarios, while the GeForce (which adds a vertex and a pixel shader core as a pair) gains only half the benefit under some conditions. Put simply, if a GeForce core is limited by the number of pixel shader cores available, the addition of a vertex shader core adds no benefit.
Throwing enough core pairs onto silicon will give you the performance you need, but not as efficiently as general purpose cores would. Of course a general purpose core architecture will be bigger, but that's a separate discussion.
metafor - Tuesday, November 1, 2011 - link
I think you need to check your math. If you double the number of cores in a Geforce, you'll still gain 2x the relative performance.Double is a multiplier, not an adder.
If a task was vertex-shader bound before, doubling the number of vertex-shaders (which comes with doubling the number of cores) will improve performance by 100%.
Of course, in the case of 543MP2, we're not just talking about doubling computational cores.
It's literally 2 GPU's (I don't think much is shared, maybe the various caches).
Think SLI but on silicon.
If you put 2 Geforce GPU's on a single die, the effect will be the same: double the performance for double the area.
Architecture dictates the perf/GPU. That doesn't mean you can't simply double it at any time to get double the performance.
PeteH - Tuesday, November 1, 2011 - link
But I'm not talking about relative performance, I'm talking about performance per unit area added. When bound by one operation adding a core that supports a different operation is wasted space.So yes, doubling space always doubles relative performance, but adding 20 square millimeters means different things to the performance of different architectures.