Facebook's "Open Compute" Server tested
by Johan De Gelas on November 3, 2011 12:00 AM ESTMeasuring Real-world Power Consumption, Part 1
vApus FOS EWL
The Equal Workload (EWL) test is very similar to our previous vApus Mark II "Real-world Power" test. To create a real-world “equal workload” scenario, we throttle the number of users in each VM to a point where you typically get somewhere between 20% and 80% CPU load on a modern dual CPU server. This is the CPU load of vApus FOS:
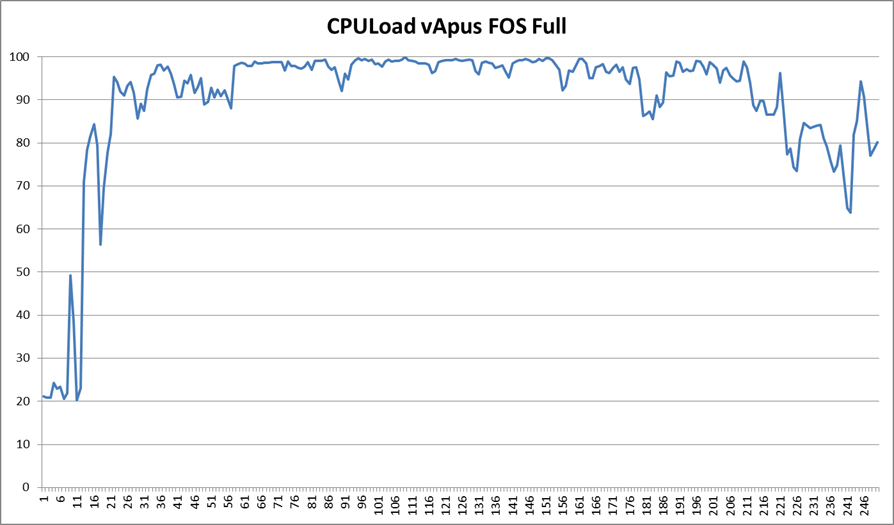
Note that we do not measure performance in the "start up" phase and at the end of test.
Compare this with vApus FOS EWL:

In this case we measure until the very end. The amount of work to be done is always equal, and the faster the system, the sooner it can idle. The time of the test is always the same, and all tested systems will spend some time in idle. The faster the system, the faster the workload will be done and the more time will be spent at idle. For this test we do not measure power but energy (power x time) consumed.
The measured performance cannot be compared as in "system x is z% faster than system y", but it does give you an idea of how well the server handles the load and how quickly it will save energy by entering a low power state.

The Xeons are all in the same ballpark. The AMD system with its slower CPUs needs more time to deal with this workload. One interesting thing to note is that Hyper-Threading does not boost throughput. That is not very surprising, considering that the total CPU load is between 20 and 80%. What about response time?

Note that we do not simply take a geomean of the response times. All response times are compared to the reference values. Those percentages (Response time/reference Response time) are then geometrically averaged.
The reference values are measured on the HP DL380 G7 running a native CentOS 5.6 client. We run four tiles of seven vCPUs on top of each server. So the value 117 means that the VMs are on average 17% slower than on the native machine. The 17% higher response times are a result of the fact that when a VM demands two virtual Xeon CPUs, the hypervisor cannot always oblige. It has 24 logical CPUs available, and 28 (7 vCPUs x 4 tiles) are requested. In contrast, the software running on the native machine gets two real cores.
Back to our results. The response time of the AMD based server tells us that even under medium load, a faster CPU can help to reduce the response time, which is the most important performance parameter anyway. However, Hyper-Threading does not help under these circumstances.
Also note that the Open Compute server handles this kind of load slightly better than the HP. So while the Open Compute servers offer a slightly lower top performance, they are at their best in the most realistic benchmark scenarios: between 20% and 80% CPU load. Of course, performance per watt remains the most important metric:
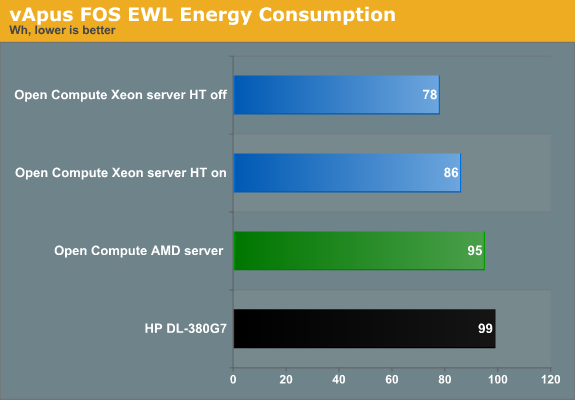
When the CPU load is between 20 and 80%, which is realistic, the HP uses 15% more power. We can reduce the energy consumed by another 10% if we disable Hyper-Threading, which as noted does not improve performance in this scenario anyway.








67 Comments
View All Comments
mrsprewell - Thursday, November 3, 2011 - link
This review claims this facebook server is more efficient than Hp's, but I see no prove. They only compares the power supply power factor performance. But what about efficiency? I guess the lab has no 277Vac input(which most datecenter don't have as well) and they can only power the server in 208/230Vac. As a result, they can't compare the servers efficiency. Also they didn't describe at what loading condition is the test being done on... I am sure the HP server has better efficiency than the facebook one at 230Vac input. The only good thing about the facebook one is that it might not need a UPS. But the consequence to that is, you have to use the battery rack from Facebook, which is not standard and can be costly.Also it is nice to know that the Powerone power supply will overheat when using DC input for more than 10min....hahahahh...that's a smart way to cost down the power supply...
marc1000 - Thursday, November 3, 2011 - link
what does this "noSQL" means??? they don't use any relational database at all? how facebook stores information? plain files?erple2 - Thursday, November 3, 2011 - link
Google doesn't use relational databases to store and retrieve its information either. Neither does the high performance data warehouse that was developed on a program I worked on a few years ago - we migrated away from Oracle for cost and performance reasons.I think that the days of the Relational Database are numbered. The mainstay of the Relational Database (stored procedures) are quickly showing their age in a complete inability to debug issues with them outside of expensive specialized tools. We've been replacing them as much as we can with an abstraction layer.
But we still have goofy constructs to deal with (joins just don't make sense from a OO perspective).
I think that Relational Databases's days are numbered.
FunBunny2 - Saturday, November 5, 2011 - link
RDBMS is numbered only for those who've no idea that what they think is "new" is just their grandpappy's olde COBOL crap. Just because you're so young, so inexperienced, and so stupid that you can't model data intelligently; doesn't mean you've got it right. But if you're in love with getting paid by LOC metrics, then Back to The Future is what you want. Remember, Facebook and Twitter and such are just toys; they ain't serious.Ceencee - Wednesday, November 9, 2011 - link
This is completely false, RDBMS have their place but are also extremely inefficient ways to access large amounts of data as ACID compliance hamstrings many of the operations.As someone who would consider himself an Oracle Expert I would say that NoSQL databases like Cassandra and HBase are really exciting technology for the future.
Starfireaw11 - Thursday, November 3, 2011 - link
I can see how the OpenCompute compares well to a DL380G7 in terms of performance vs power consumption and may compare well in price (those details aren't readily available), but the things that the OpenCompute has going for it are that it has been stripped of unneeded components, fitted with efficient fans and matched to efficient power supplies. From what I have seen and done in and around datacenters, these are exactly the objectives of a blade based system, where you can have large, efficient power supplies, large fans and missing or shared devices that are non-critical. I would like to see this article modified to include a comparison against a blade-based solution of equivalent specification to see how that stacks up - if you can swing it, use a fully populated blade chassis and average out the results against the number of blades. The blades also have an advantage of allowing approximately 14 servers in a 9 RU space - allowing approximately 70 servers per 45 RU rack, vs the 30 odd of the OpenCompute.Whenever I need to put equipment into a datacenter, the important specifications are performance, cost price, power efficiency, size, weight and heat. Whenever a large number of servers are required, blades always stack up well, possibly with the exception of weight where there are limitations on floor-loading in a datacenter, but they do compare well with weight when compared to equivalent performing non-blade servers (such as 28 RU of DL380G7s).
Doby - Saturday, November 5, 2011 - link
Although I think blades could be favorable if, at least if you take into account the infrastructure reduction such as networking ports. Thing is, if you look at the HP products that are available there are better alternatives.HP, as the specific example, has a product call the SL6500. Its a second generation product specifically designed for these types of environements, and meant to compete with exactly the type of system that FaceBook created. A comparitive use case would be a 8 node configuration, which would take up 4U of rack space and could run off of 2-4 PSU that would be shared between the nodes. Additionally it has a shared redundant FAN configuration that uses larger, more efficient fans to cool the chassis. Its like blades, but doesn't have any shared networking, is made specifically to be lighter and cheaper, and has options for lower cost nodes.
The DL380 has a few things working against it in this comparison, from hot swapable drives, to enterprise class onboard management (iLO, not just basic BMC), reduandant fans, scalable power infrastructure, 6 PCI-E slots, onboard, high perfromance RAID controller, 4 NICs, and simplified servicability with single tool and/or toolless servicibility, and even a display for component failures.
The SL6500 would be able to have very basic nodes, with non hot swap SATA drives, basic SATA raid function, dual NICs, and features much more inline with the Facebook system. Sure, it woudln't be as specific to Facebooks needs, but would be a more interesting comparison as it would be at least comparing two systems designed for similar roles, not a general enterprise compute node to a purpose built scale out system, but a comparison of 2 scale out platforms.
Ceencee - Wednesday, November 9, 2011 - link
The SL6500 chasis with SL160s G6 servers seems to be a good solution to storage level nodes. Wonder if Facebook will release a storage node spec next?Penti - Saturday, November 5, 2011 - link
You have different cooling requirement also. Obviously Googles or Facebooks option isn't about the maximum density per rack. But they are also not using any traditional hot aisle cold aisle setup. Not will all datacenters be able to handle your 20-30kW rack. In terms off cooling requirements and power.rikmorgan - Thursday, November 3, 2011 - link
The idle power chart shows HP 160w, Open Compute 118w. That's 42w savings, not 32w.