Facebook's "Open Compute" Server tested
by Johan De Gelas on November 3, 2011 12:00 AM ESTMeasuring Real-world Power Consumption, Part 1
vApus FOS EWL
The Equal Workload (EWL) test is very similar to our previous vApus Mark II "Real-world Power" test. To create a real-world “equal workload” scenario, we throttle the number of users in each VM to a point where you typically get somewhere between 20% and 80% CPU load on a modern dual CPU server. This is the CPU load of vApus FOS:
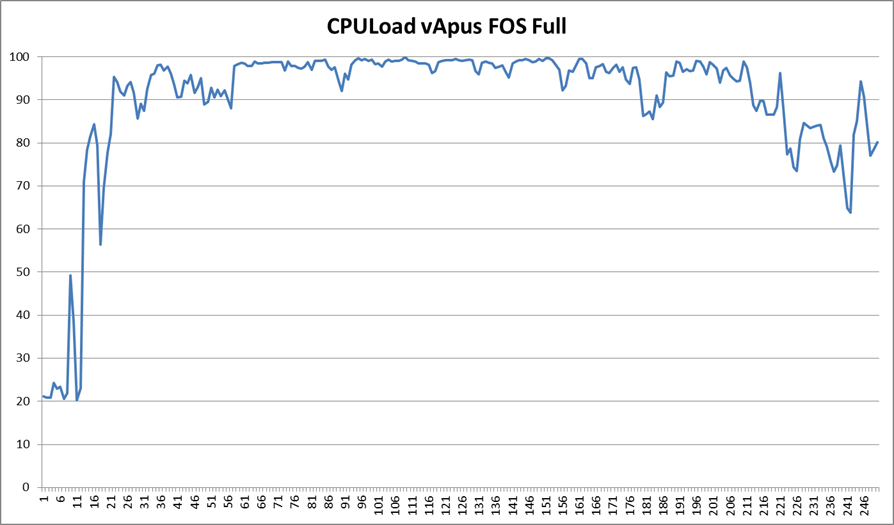
Note that we do not measure performance in the "start up" phase and at the end of test.
Compare this with vApus FOS EWL:

In this case we measure until the very end. The amount of work to be done is always equal, and the faster the system, the sooner it can idle. The time of the test is always the same, and all tested systems will spend some time in idle. The faster the system, the faster the workload will be done and the more time will be spent at idle. For this test we do not measure power but energy (power x time) consumed.
The measured performance cannot be compared as in "system x is z% faster than system y", but it does give you an idea of how well the server handles the load and how quickly it will save energy by entering a low power state.

The Xeons are all in the same ballpark. The AMD system with its slower CPUs needs more time to deal with this workload. One interesting thing to note is that Hyper-Threading does not boost throughput. That is not very surprising, considering that the total CPU load is between 20 and 80%. What about response time?

Note that we do not simply take a geomean of the response times. All response times are compared to the reference values. Those percentages (Response time/reference Response time) are then geometrically averaged.
The reference values are measured on the HP DL380 G7 running a native CentOS 5.6 client. We run four tiles of seven vCPUs on top of each server. So the value 117 means that the VMs are on average 17% slower than on the native machine. The 17% higher response times are a result of the fact that when a VM demands two virtual Xeon CPUs, the hypervisor cannot always oblige. It has 24 logical CPUs available, and 28 (7 vCPUs x 4 tiles) are requested. In contrast, the software running on the native machine gets two real cores.
Back to our results. The response time of the AMD based server tells us that even under medium load, a faster CPU can help to reduce the response time, which is the most important performance parameter anyway. However, Hyper-Threading does not help under these circumstances.
Also note that the Open Compute server handles this kind of load slightly better than the HP. So while the Open Compute servers offer a slightly lower top performance, they are at their best in the most realistic benchmark scenarios: between 20% and 80% CPU load. Of course, performance per watt remains the most important metric:
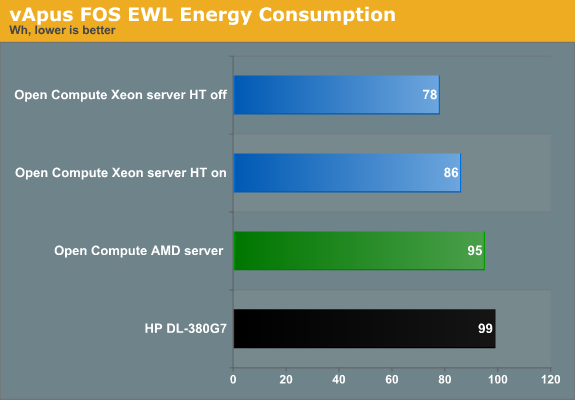
When the CPU load is between 20 and 80%, which is realistic, the HP uses 15% more power. We can reduce the energy consumed by another 10% if we disable Hyper-Threading, which as noted does not improve performance in this scenario anyway.








67 Comments
View All Comments
JohanAnandtech - Thursday, November 3, 2011 - link
It is an ATI ES 1000, that is a server/thin client chip. That chip is only 2D. I can not find the power specs, but considering that the chip does not even need a heatsink, I think this chip consumes maybe 1W in idle.mczak - Thursday, November 3, 2011 - link
ES 1000 is almost the same as radeon 7000/ve (no that's not HD 7000...) (some time in the past you could even force 3d in linux with the open-source driver though it usually did not work). The chip also has dedicated ram chip (though only 16bit wide memory interface) and I'm not sure how good the powersaving methods of it are (probably not downclocking but supporting clock gating) - not sure if it fits into 1W at idle (but certainly shouldn't be much more).JohanAnandtech - Thursday, November 3, 2011 - link
I can not find any good tech resources on the chip, but I can imagine that AMD/ATI have shrunk the chip since it's appearance in 2005. If not, and the chip does consume quite a bit, it is a bit disappointing that server vendors still use it as the videochip is used very rarely. You don't need a videochip for RDP for example.mczak - Thursday, November 3, 2011 - link
I think the possibility of this chip being shrunk since 2005 is 0%. The other question is if it was shrunk from rv100 or if it's actually the same - even if it was shrunk it probably was a well mature process like 130nm in 2005 otherwise it's 180nm.At 130nm (estimated below 20 million transistors) the die size would be very small already and probably wouldn't get any smaller due to i/o anyway. Most of the power draw might be due to i/o too so shrink wouldn't help there neither. It is possible though it's really below 1W (when idle).
Taft12 - Thursday, November 3, 2011 - link
A shrink WOULD allow production of many more units on each wafer. Since almost every server shipped needs an ES1000 chip, demand is consistently on the order of millions per year.mczak - Thursday, November 3, 2011 - link
There's a limit how much i/o you can have for a given die size (actually the limiting factor is not area but circumference so making it rectangular sort of helps). i/o pads apparently don't shrink well hence if your chip has to have some size because you've got too many i/o pads a shrink will do nothing but make it more expensive (since smaller process nodes are generally more expensive per area).Being i/o bound is quite possible for some chips though I don't know if this one really is - it's got at least display outputs, 16bit memory interface, 32bit pci interface and the required power/ground pads at least.
In any case even at 180nm the chip should be below 40mm² already hence the die size cost is probably quite low compared to packaging, cost of memory etc.
Penti - Saturday, November 5, 2011 - link
It's the integrated BMC/ILO solution which also includes a GPU that would use more power then the ES1000 any how. That is also what is lacking in the simple Google / Facebook compute-node setup. They don't need that kind off management and can handle that a node goes offline.haplo602 - Thursday, November 3, 2011 - link
It seems to me that the HP server is doing as well as the Facebook ones. Considering it has more featuers (remote management, integrated graphics) and a "common" PSU.JohanAnandtech - Thursday, November 3, 2011 - link
The HP does well. However, if you don't need integrated graphics and you hardly use the BMC at all, you still end up with a server that wastes power on features you hardly use.twhittet - Thursday, November 3, 2011 - link
I would assume cost is also a major factor. Why pay for so many features you don't need? Manufacturing costs should be lower if they actually build these in bulk.