Sandy Bridge Memory Scaling: Choosing the Best DDR3
by Jared Bell on July 25, 2011 1:55 AM EST3DMark 11
We're going to start the graphics benchmarks with the synthetic 3DMark test. The latest version, 3DMark 11, is still very GPU dependent. However, it does include a CPU Physics test and a combined graphics/physics test for simulating those types of loads. We’ll use the overall score with the three subtests to see if we can find any areas where memory performance makes a noticeable difference.
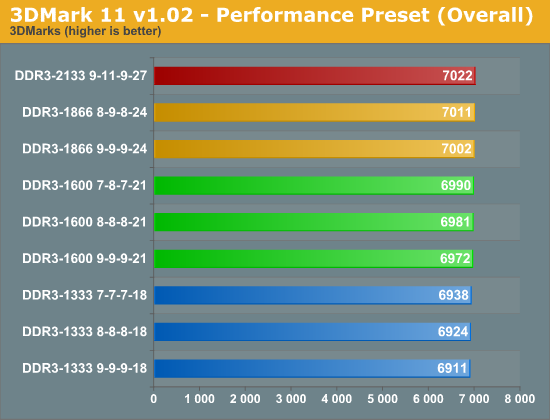
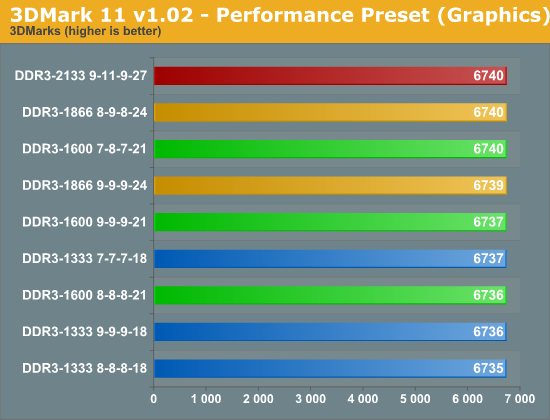
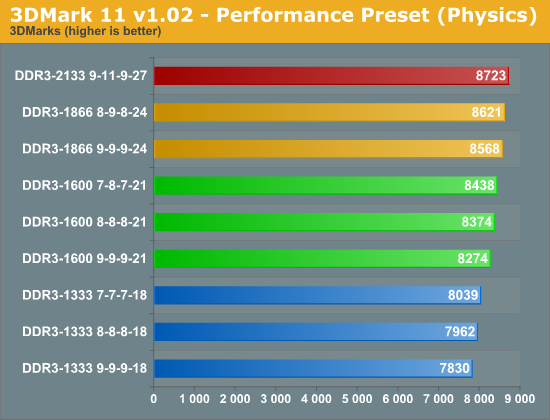

The overall score, which is heavily based on the graphics tests, shows a mere ~1% change across the board. When you get to the graphics test, you can see that the faster memory makes absolutely no difference at all. It's not until we get to the physics test where we see some improvement from increasing the memory speed. We get performance boost of up to 11% when going from DDR3-133 to DDR3-2133. The combined test entails the rendering of a 3D scene with the GPU while performing physics tasks on the CPU. Here again, were see a very small 2% increase in performance from the slowest to the fastest.
Crysis and Metro 2033
Based on 3DMark 11, then, we’d expect most games to show very little improvement from upgrading your memory, but we ran several gaming benchmarks just to be sure. I decided to combine the analysis for Crysis: Warhead and Metro 2033 due to the virtually non-existent differences observed during these tests. Crysis: Warhead was the previous king of the hill when it came to bringing video cards to their knees. The newer kid on the block, Metro 2033, has somewhat taken over that throne. Just how do they react to the various memory configurations we're testing today?
It's worth noting that the settings used here are the settings that I would actually play these games at: 1920x1080 with most of the high quality features enabled. Frame rates are well above 30, so definitely playable, though they’re below 60 so some would say they’re not perfectly smooth. Regardless, unless you play at settings where your GPU isn’t the primary bottleneck, you should see similar scaling from memory performance.
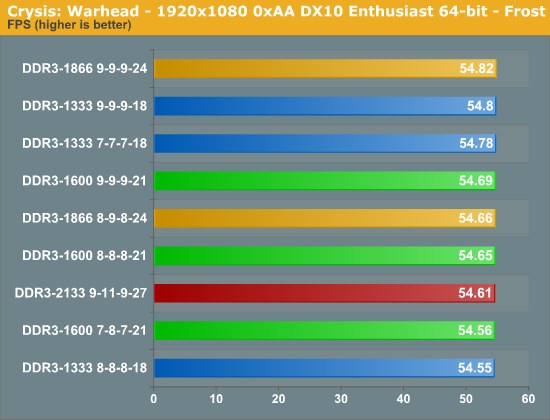
The results weren't very stimulating, were they? Just as expected, gaming with faster memory just doesn't make any notable difference. I could have potentially lowered the resolution and settings in an attempt to produce some sort of difference, but I felt that testing these games at the settings they're most likely to be played at was far more enlightening. If you want better gaming performance, the GPU is the best component to upgrade—no news there.








76 Comments
View All Comments
mga318 - Monday, July 25, 2011 - link
You mentioned Llano at the end, but in the Llano reviews & tests, memory bandwidth was tested primarily with little reference to latency. I'd be curious as to which is more important with a higher performance IGP like Llano's. Would CAS 7 (or 6) be preferrable over 1866 or 2166 speeds wtih CAS 8 or 9?DarkUltra - Monday, July 25, 2011 - link
How about testing Valves particle benchmark or a source based game at low reslution with a non-geometry limited 3d card (fermi) and overclocked cpu? Valve did an incredible job with their game engine. They used a combination of fine-grained and coarse threading to max out all the cpu cores. Very few games can do that today, but may in the future.DarkUltra - Monday, July 25, 2011 - link
Why test with 4GB? RAM is cheap, most people who buy the premium 2600K should pair it with two 4GB modules. I imagine Windows would require 4GB ram and games the same in the future. Just look at all the .net developers out there, .net usually results in incredible memory bloated programs.dingetje - Monday, July 25, 2011 - link
hehe yeah.net sucks
Atom1 - Monday, July 25, 2011 - link
Most algorithms on CPU platform are optimized to have their data 99% of time inside the CPU cache. If you look at the SisSoft Sandra where there is a chart of bandwidth as a function of block size copied you can see that CPU cache is 10-50x faster than global memory depending on the level. Linpack here is no exception. The primary reason for success of linpack is its ability to have data in CPU cache nearly all of the time. Therefore, if you do find an algorithm which can benefit considerably from global memory bandwidth, you can be sure it is a poor job on the programmers side. I think it is a kind of a challenge to see which operations and applications do take a hit when the main memory is 2x faster or 2x slower. I would be interested to see where is the breaking point, when even well written software starts to take a hit.DanNeely - Monday, July 25, 2011 - link
That's only true for benchmarks and highly computationally intensive apps (and even there many problem classes can't be packed into the cache or written to stream data into it). In the real world where 99% of software's performance is bound by network IO, HD IO, or user input trying to tune data to maximize the CPU cache is wasted engineering effort. This is why most line of business is written using java or .net, not C++; the finer grained memory control of the latter doesn't benefit anything while the higher level nature of the former allows for significantly faster development.Rick83 - Monday, July 25, 2011 - link
I think image editing (simple computation on large datasets) and engineering software (numerical simulations) are two types of application that benefit more than average from memory bandwidth, and in the second case, latency.But, yeah, with CPU caches reaching the tens of Megabytes, Memory bandwidth and latency is getting less important for many problems.
MrSpadge - Wednesday, July 27, 2011 - link
True.. large matrix operations love bandwidth and low latency never hurts. I've seen ~13% speedup on part of my Matlab code going from DDR3-1333 CL9 to DDR3-1600 CL9 on an i7 870!MrS
Patrick Wolf - Monday, July 25, 2011 - link
You don't test CPU gaming benchmarks at normal settings cause you may become GPU limited so why do it here?http://www.xbitlabs.com/articles/memory/display/sa...
dsheffie - Monday, July 25, 2011 - link
....uh...Linpack is just LU which in turn is just DGEMM. DGEMM has incredible operand reuse (O(sqrt(cache size)).