Rendering and HPC Benchmark Session Using Our Best Servers
by Johan De Gelas on September 30, 2011 12:00 AM ESTCinebench R11.5
Cinebench, based on MAXON's software CINEMA 4D, is probably one of the most popular benchmarks around, and it is pretty easy to perform this benchmark on your own home machine. However, it gets a little bit more complicated when you try to run it on an 80 thread server: the benchmark only supports 64 threads.
First we tested single threaded performance, to evaluate the performance of each core.
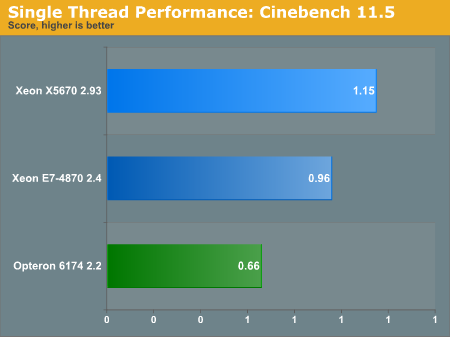
A Core i7-970, which is based on the same "Westmere" architecture gets about 1.2 at 3.2GHz, so there is little surprise that a slightly lower clocked Xeon 5670 is able to reach a 1.15 score. It is interesting to note however that the Westmere core inside the massive Westmere-EX gets a better score than expected. Considering that Cinebench scales almost perfectly with clockspeed, you would expect a score of about 0.9. The E7 can boost clockspeed by 17% from 2.4 to 2.8GHz, while the previously mentioned i7-970 gets only an 8% boost at most (from 3.2 to 3.46GHz). And of course, the massive L3-cache may help too.
The Opteron at 2.2GHz performs like its Phenom II desktop counterparts. A 3.2GHz Phenom II gets a score of about 0.92, so we are not surprised with the 0.66 for our 2.2GHz core.
When we started benchmarking Cinebench on our Xeon E7 platform, we ran into trouble. Cinebench only supports 64 threads at the most and recognized only 32 of our 40 available cores and 80 threads. The results were pretty bad. To get a decent result out of the Xeon E7, we had to disable Hyper-Threading and we forced Cinebench to start up 40 threads. We included a Core i7-970 (Hyper-Threading on) to give you an idea of how a powerful workstation/desktop compares to these servers. This kind of software is run a lot on fast workstations after all.

Even cheap servers will outperform a typical single socket workstation by almost a factor of two. The quad socket machines can offer up to three or four times as much performance. For those of you who can't get enough: you can find some dual Opteron numbers here. The dual Opteron 6174 scores about 15, and a dual Opteron 2435 2.6 "Istanbul" gets about 9.
Cinebench scales very easily as can be noticed from looking at the 32 core and 40 core results of the Xeon E7-4870. Increase the core count by 25% and you get a 22.4% performance increase. The Opteron scales slightly worse. Compare the 48-core result with the 32 core one: a 50% increase in core counts gets you "only" a 37% increase in performance.
Below you can see the rendering performance of two top machines rendering with different numbers of cores.
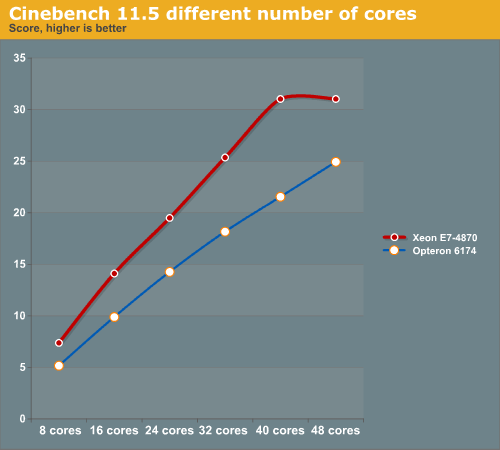
You need about 48 2.2GHz Opteron cores to match 32 Xeon cores. The good news for AMD is that even these 8-core Westmere-EX CPUs are almost twice as expensive. That means that quad AMD Opteron 61xx systems are a viable choice for rendering, at least in CINEMA 4D (assuming it has the same 64-thread limitation as Cinebench). AMD has carved out a niche here, which is one reason why there will be cheaper 4 socket Romley EP systems in the near future.








52 Comments
View All Comments
jaguarpp - Friday, September 30, 2011 - link
what if instead of using a full program, create a small test program that is compiled for each platform something likedeclare variables int, floats, arrays to test diferent workloads
put the variables on loops and do some operation sum, div, the integers then the floats and so on measure the time that take to exit from each block
the hardest part will be how to make it threadable
and get acces to diferent compilers, maybe a friend?
anyway great article i really enjoy it even when i never get close to that class of hardware
thanks very much for the reading
Michael REMY - Friday, September 30, 2011 - link
very interesting analyze but...why use a score in cinebench instead a time render score ?Time result are more meaning for common and pro user than integer score !
MrSpadge - Friday, September 30, 2011 - link
Because time is totally dependent on the complexity of your scene, output resolution etc. And the score can be directly translated into time if you know the time for any of the configurations tested.MrS
Casper42 - Friday, September 30, 2011 - link
Go back to Quanta and see if they have a newer BIOS with the Core Disable feature properly implemented. I Know the big boys are now implementing the feature and it allows you to disable as many cores as you want as long as its done in pairs. So your 10c proc can be turned into 2/4/6/8 core versions as well.So for your first test where you had to turn HT off because 80 threads was too much, you could instead turn off 2 cores per proc and synthetically create a 4p32c server and then leave HT on for the full 64 threads.
alpha754293 - Sunday, October 2, 2011 - link
"Hyper-Threading offers better resource utilization but that does not negate the negative performance effect of the overhead of running 80 threads. Once we pass 40 threads on the E7-4870, performance starts to level off and even drop."It isn't thread-locking that limits the performance. It isn't because it has to sync/coordinate 80-threads. It's because there's only 40 FPUs available to do the actual calculations on/with.
Unlike virtualization, where thread locking is a real possiblity because there really isn't much in the way of underlying computations (I would guess that if you profiled the FPU workload, it wouldn't show up much), whereas for CFD, solving the Navier-Stokes equations requires a HUGE computational effort.
it also depends on the means that the parallelization is done, whether it's multi-threading, OpenMP, or MPI. And even then, within different flavors of MPI, they can also yield different results; and to make things even MORE complicated, how the domain is decomposed also can make a HUGE impact on performance as well. (See the studies performed by LSTC with LS-DYNA).
alpha754293 - Sunday, October 2, 2011 - link
Try running Fluent (another CFD) code and LS-DYNA.CAUTION: both are typically usually VERY time-intensive benchmarks, so you have to be very patient with them.
If you need help in setting up standardized test cases, let me know.
alpha754293 - Sunday, October 2, 2011 - link
I'm working on trying to convert an older CFX model to Fluent for a full tractor-trailer aerodynamics run. The last time that I ran that, it had about 13.5 million elements.deva - Monday, October 3, 2011 - link
If you want something that currently scales well, Terra Vista would be a good bet (although it is expensive).Have a look at the Multi Machine Build version.
http://www.presagis.com/products_services/products...
"...capability to generate databases of
100+ GeoCells distributed to 256 individual
compute processes with a single execution."
That's the bit that caught my eye and made me think it might be useful to use as a benchmarking tool.
Daniel.
mapesdhs - Tuesday, October 4, 2011 - link
Have you guys considered trying C-ray? It scales very well with no. of cores, benefits from as
many threads as one can throw at it, and the more complex version of the example render
scene stresses RAM a bit aswell (the small model doesn't stress RAM at all, deliberately so).
I started a page for C-ray (Google for, "c-ray benchmark", 1st link) but discovered recently
it's been taken up by the HPC community and is now part of the Phoronix Test Suite (Google
for, "c-ray benchmark pts", 1st link again). I didn't create C-ray btw (creds to John Tsiombikas),
just took over John's results page.
Hmm, don't suppose you guys have the clout to borrow or otherwise have access to an SGI
Altix UV? Would be fascinating to see how your tests scale with dozens of sockets instead of
just four, eg. the 960-core UV 100. Even a result from a 40-core UV 10 would be interesting.
Shared-memory system so latency isn't an issue.
Ian.
shodanshok - Wednesday, October 5, 2011 - link
Hi Johan,thank you for the very interesting article.
The Hyperthreading ON vs OFF results somewhat surprise me, as Windows Server 2008 should be able to prioritize hardware core vs logical ones. Was this the case, or you saw that logical processors were used before full hardware core utilization? If so, you probably encounter one corner case were extensive hardware sharing (and contention) between two threads produce lower aggregate performance.
Regards.