AMD's Graphics Core Next Preview: AMD's New GPU, Architected For Compute
by Ryan Smith on December 21, 2011 9:38 PM ESTMany SIMDs Make One Compute Unit
When we move up a level we have the Compute Unit, what AMD considers the fundamental unit of computation. Whereas a single SIMD can execute vector operations and that’s it, combined with a number of other functional units it makes a complete unit capable of the entire range of compute tasks. In practice this replaces a Cayman SIMD, which was a collection of Cayman SPs. However a GCN Compute Unit is capable of far, far more than a Cayman SIMD.
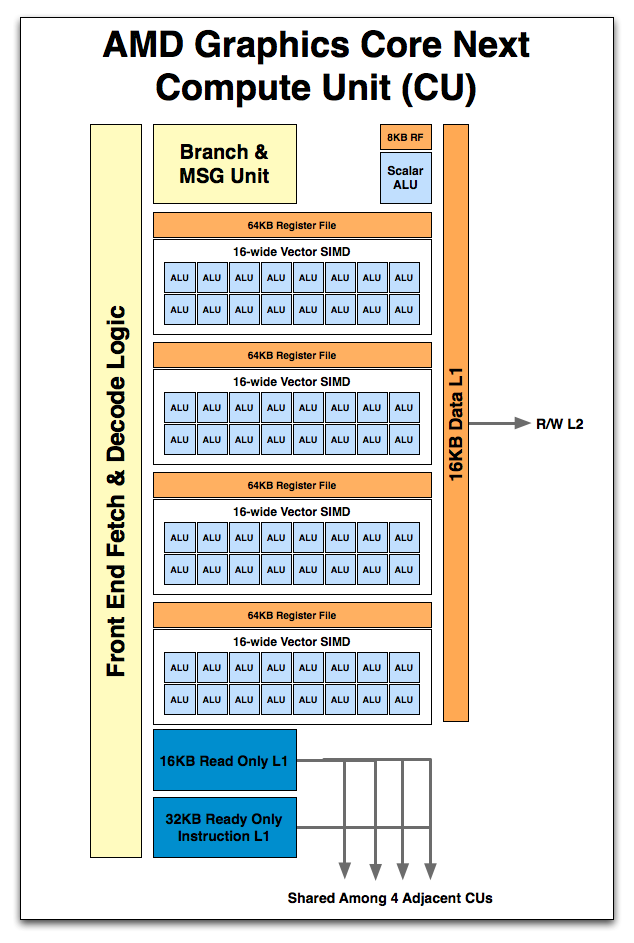
So what’s in a Compute Unit? Just as a Cayman SIMD was a collection of SPs, a Compute Unit starts with a collection of SIMDs. 4 SIMDs are in a CU, meaning that like a Cayman SIMD, a GCN CU can work on 4 instructions at once. Also in a Compute Unit is the control hardware & branch unit responsible for fetching, decoding, and scheduling wavefronts and their instructions. This is further augmented with a 64KB Local Data Store and 16KB of L1 data + texture cache. With GCN data and texture L1 are now one and the same, and texture pressure on the L1 cache has been reduced by the fact that AMD is now keeping compressed rather than uncompressed texels in the L1 cache. Rounding out the memory subsystem is access to the L2 cache and beyond. Finally there is a new unit: the scalar unit. We’ll get back to that in a bit.
But before we go any further, let’s stop here for a moment. Now that we know what a CU looks like and what the weaknesses are of VLIW, we can finally get to the meat of the issue: why AMD is dropping VLIW for non-VLIW SIMD. As we mentioned previously, the weakness of VLIW is that it’s statically scheduled ahead of time by the compiler. As a result if any dependencies crop up while code is being executed, there is no deviation from the schedule and VLIW slots go unused. So the first change is immediate: in a non-VLIW SIMD design, scheduling is moved from the compiler to the hardware. It is the CU that is now scheduling execution within its domain.
Now there’s a distinct tradeoff with dynamic hardware scheduling: it can cover up dependencies and other types of stalls, but that hardware scheduler takes up die space. The reason that the R300 and earlier GPUs were VLIW was because the compiler could do a fine job for graphics, and the die space was better utilized by filling it with additional functional units. By moving scheduling into hardware it’s more dynamic, but we’re now consuming space previously used for functional units. It’s a tradeoff.
So what can you do with dynamic scheduling and independent SIMDs that you could not do with Cayman’s collection of SPs (SIMDs)? You can work around dependencies and schedule around things. The worst case scenario for VLIW is that something scheduled is completely dependent or otherwise blocking the instruction before and after it – it must be run on its own. Now GCN is not an out-of-order architecture; within a wavefront the instructions must still be executed in order, so you can’t jump through a pixel shader program for example and execute different parts of it at once. However the CU and SIMDs can select a different wavefront to work on; this can be another wavefront spawned by the same task (e.g. a different group of pixels/values) or it can be a wavefront from a different task entirely.
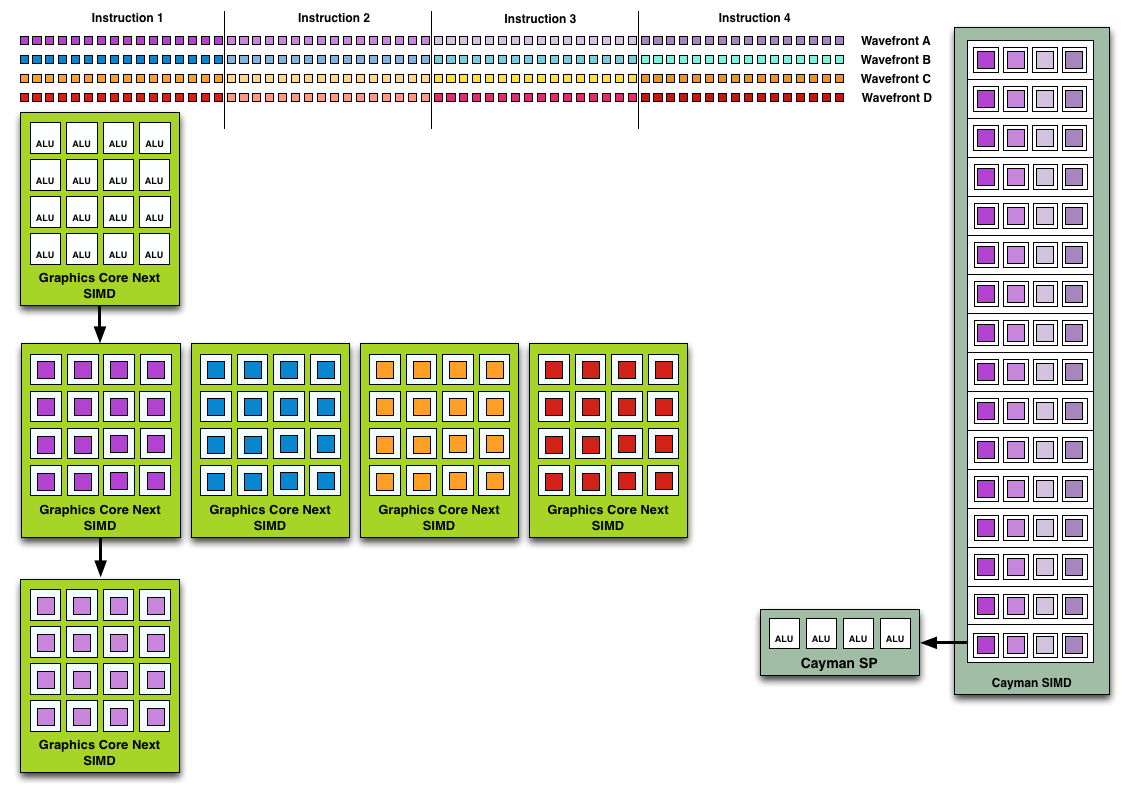
Wavefront Execution Example: SIMD vs. VLIW. Not To Scale - Wavefront Size 16
Cayman had a very limited ability to work on multiple tasks at once. While it could consume multiple wavefronts from the same task with relative ease, its ability to execute concurrent tasks was reliant on the API support, which was limited to an extension to OpenCL. With these hardware changes, GCN can now concurrently work on tasks with relative ease. Each GCN SIMD has 10 wavefronts to choose from, meaning each CU in turn has up to a total of 40 wavefronts in flight. This in a nutshell is why AMD is moving from VLIW to non-VLIW SIMD for Graphics Core Next: instead of VLIW slots going unused due to dependencies, independent SIMDs can be given entirely different wavefronts to work on.
As a consequence, compiling also becomes much easier. With the compiler freed from scheduling tasks, compilation behaves in a rather standard manner, since most other architectures are similarly scheduled in hardware. Writing a compiler still isn’t absolutely easy, but when it comes to optimizing the execution of a program the compiler can focus on other matters, making it much easier for other languages to target GCN. In fact without the need to generate long VLIW instructions or to including scheduling information, the underlying ISA for GCN is also much simpler. This makes debugging much easier since the code generated reflects the fact that scheduling is now done in hardware, which is reflected in our earlier assembly code example.
Now while leaving behind the drawbacks of VLIW is the biggest architectural improvement for compute performance coming from Cayman, the move to non-VLIW SIMDs is not the only benefit. We still have not discussed the final component of the CU: the Scalar ALU. New to GCN, the Scalar unit serves to further keep inefficient operations out of the SIMDs, leaving the vector ALUs on the SIMDs to execute instructions en mass. The scalar unit is composed of a single scalar ALU, along with an 8KB register file.
So what does a scalar unit do? First and foremost it executes “one-off” mathematical operations. Whole groups of pixels/values go through the vector units together, but independent operations go to the scalar unit as to not waste valuable SIMD time. This includes everything from simple integer operations to control flow operations like conditional branches (if/else) and jumps, and in certain cases read-only memory operations from a dedicated scalar L1 cache. Overall the scalar unit can execute one instruction per cycle, which means it can complete 4 instructions over the period of time it takes for one wavefront to be completed on a SIMD.
Conceptually this blurs a bit more of the remaining line between a scalar GPU and a vector GPU, but by having both types of units it means that each unit type can work on the operations best suited for it. Besides avoiding feeding SIMDs non-vectorized datasets, this will also improve the latency for control flow operations, where Cayman had a rather nasty 44 cycle latency.








83 Comments
View All Comments
DoctorPizza - Monday, June 20, 2011 - link
I can't understand that at all.The next architecture will have 16-wide SIMD. How does that fit computational problems better than a 16-wide MIMD VLIW architecture? VLIW can act as if it were SIMD if necessary (simply make each instruction within the word the same, varying only the operands), so how on earth can SIMD be better? SIMD is strictly less general and less flexible than VLIW. This makes it applicable to a narrower set of problems--if you have problems that aren't 16-wide, then you're wasting those additional ALUs, and there's nothing you can do with them, ever. MIMD can't always use them, but there the restriction is unbreakable dependencies, not an inability to encode instructions.
And while VLIW heritage is indeed statically scheduled, nothing about VLIW mandates static scheduling. The next generation Itanium will use dynamic scheduling, for example.
This whole article reads like AMD has offered a rationale for its architectural change, and the author has accepted that rationale without ever stopping to consider if it makes sense.
DoctorPizza - Monday, June 20, 2011 - link
(FYI: the *real* reason to go for SIMD instead of VLIW is simply that VLIW takes up more die area. AMD has decided that the problems people are working on have enough data- and thread-level parallelism that it's not worth having extra decode logic to enable extraction of more instruction-level parallelism.The result is a design that's actually *worse* for general-purpose computation--for non-vector computations, it'll only ever use one of those sixteen ALUs, whereas the previous design could in principle use them all--but better for embarrassingly parallel workloads.
Why the article couldn't say this is anybody's guess.)
Quantumboredom - Tuesday, June 21, 2011 - link
I don't understand your argument. They have moved from 16-wide SIMD where each instruction is a 4-operation VLIW (where there are quite a few restrictions on what that VLIW instruction can actually be) to _four_ 16-wide SIMDs where each instruction is scalar. The new architecture is in every way more general and more suited to a wide range of computational problems while retaining the same power. It does presumably cost more (in terms of area/transistors), but hopefully it will be worth it.DoctorPizza - Tuesday, June 21, 2011 - link
Where does it say that Cayman SPs are ganged into groups of 16? It says they're grouped somehow, but never makes the claim that their groups are as wide as the new SIMD short vectors.Quantumboredom - Tuesday, June 21, 2011 - link
It is well-known that Cypress and Cayman both have arrays of 16 processing elements operating in SIMD mode, and they have to execute work-items from the same work-group over four cycles, leading to a wavefront size of 64. See for example the AMD APP OpenCL Programming Guide 1.3c section 1.2 where this is described. Specifically it says "All stream cores within a compute unit execute the same instruction sequence in lock-step".DoctorPizza - Tuesday, June 21, 2011 - link
"well-known"? I assure you, the vast majority of people have not read AMD's OpenCL Programming Guide.Nonetheless, the article still makes little sense.
A vector of 16 instruction-parallel processors is more versatile than a vector of 16 strictly SISD ones. In the worst case, with unbreakable data dependencies, the former degrades to the latter. In the best case, the former can do 4 (VLIW4) or 5 (VLIW5) times the work of the latter. The average case cited in the article was about 3.5 times.
If you only had one thread of work, the old architecture would tend to be better. For every 64 ALUs (one old VLIW vector or four new SIMD vectors), a single-threaded task would average usage of 56 out of 64 ALUs (3.5 per VLIW) on the old arch, but only 16 out of 64 on the new.
However, AMD is plainly counting on there being many, many potential threads. If you have abundant threads then you can guarantee that you can fill up the remaining 48 ALUs with different threads, whereas the 8 unused ALUs in the VLIW arch are off-limits.
This is a less general architecture, but as long as all your problems are massively parallel, creating all those extra threads shouldn't be a problem. AMD is sacrificing generality in favour of the embarrassingly parallel.
Quantumboredom - Tuesday, June 21, 2011 - link
I actually asked a similar question at the AMD Fusion Developer Summit.The minimum number of wavefronts (i.e., batches of 64 work-items) needed to keep a Cypress/Cayman CU fed is two, while GCN requires four wavefronts (so twice as many). However it is the case that quite often (for all of my programs actually) you really do need four wavefronts per CU on Cypress/Cayman to effectively hide the global memory latency. The guy I was talking to at AMD seemed to thnik that in practice the number of work-items needed would stay about the same between Cayman and GCN for most applications.
I've asked this question on the AMD developer forums as well, but I don't know how many answers will be given about GCN there.
DoctorPizza - Tuesday, June 21, 2011 - link
I certainly wouldn't be surprised to hear that typical GPGPU workloads could inundate the GPU with threads and so provide more than enough wavefronts. The GPGPU workloads are pretty much all of the embarrassingly parallel kind, so creating more threads should tend to be pretty trivial.So your experience certainly makes sense with what I'd expect.
It's not that I think this is necessarily a bad change for the applications that people use GPGPU processing for.
It's more that I'm disputing the implication that this somehow makes the GPU more general and easier to take advantage of; to my mind it's doing the exact opposite of that.
Or to put it another way: virtually every single program has a reasonable amount of instruction level parallelism. Data-/thread-level parallelism is much rarer. We're losing the former to improve the latter.
For problems amenable to massive thread-/data-level parallelism the result should be substantially more ALUs available to process on. But for problems with only limited data-/thread-level parallelism, it's a step backwards.
name99 - Thursday, December 22, 2011 - link
"The next architecture will have 16-wide SIMD. How does that fit computational problems better than a 16-wide MIMD VLIW architecture? VLIW can act as if it were SIMD if necessary (simply make each instruction within the word the same, varying only the operands), so how on earth can SIMD be better? SIMD is strictly less general and less flexible than VLIW."A VLIW system has to have instruction decoders and routers for every instruction, and thus for every data item that is processed.
A SIMD system only has to have one instruction decoder and router for every 16 data items that are processed. If your computations consist primarily of doing the same thing to multiple data items this is a win. (More processing for less power and less silicon.) If your computations do NOT consist primarily of doing the same thing to multiple data items, it's a loss.
Or, to put it differently, is it worth investing silicon in moving instructions around with great facility, or is it better to invest silicon in moving data around with great facility? Seymour Crane thought (for the problems he cared about) the answer was data. I'd like to think AMD know enough about what they are doing that they have the numbers in hand, and have calculated that, once again for them the answer is data.
MySchizoBuddy - Tuesday, June 21, 2011 - link
where is the information about the toolkit to take advantage of this hardware?