AMD's Graphics Core Next Preview: AMD's New GPU, Architected For Compute
by Ryan Smith on December 21, 2011 9:38 PM ESTFinal Words
As GPUs have increased in complexity, the refresh cycle has continued to lengthen. 6 month cycles have largely given way to 1 year cycles, and even then it can be 2+ years between architecture refreshes. This is not only a product of the rate of hardware development, but a product of the need to give developers time to breathe and to absorb information about new architectures.
The primary purpose of the AMD Fusion Developer Summit and the announcement of the AMD Graphics Core Next is to give developers even more time to breathe by extending the refresh window backwards as well as forwards. It can take months to years to deliver a program, so the sooner an architecture is introduced the sooner a few brave developers can begin working on programs utilizing it; the alternative is that it may take years after the launch of a new architecture before programs come along that can fully exploit the new architecture. One only needs to take a look at the gaming market to see how that plays out.
Because of this need to inform developers of the hardware well in advance, while we’ve had a chance to see the fundamentals of GCN products using it are still some time off. At no point has AMD specified when a GPU will appear using GCN will appear, so it’s very much a guessing game. What we know for a fact is that Trinity – the 2012 Bulldozer APU – will not use GCN, it will be based on Cayman’s VLIW4 architecture. Because Trinity will be VLIW4, it’s likely-to-certain that AMD will have midrange and low-end video cards using VLIW4 because of the importance they place on being able to Crossfire with the APU. Does this mean AMD will do another split launch, with high-end parts using one architecture while everything else is a generation behind? It’s possible, but we wouldn’t make at bets at this point in time. Certainly it looks like it will be 2013 before GCN has a chance to become a top-to-bottom architecture, so the question is what the top discrete GPU will be for AMD by the start of 2012.
Moving on, it’s interesting that GCN effectively affirms most of NVIDIA’s architectural changes with Fermi. GCN is all about creating a GPU good for graphics and good for computing purposes; Unified addressing, C++ capabilities, ECC, etc were all features NVIDIA introduced with Fermi more than a year ago to bring about their own compute architecture. I don’t believe there’s ever been a question whether NVIDIA was “right”, but the question has been whether it’s time to devote so much engineering effort and die space on technologies that benefit compute as opposed to putting in more graphics units. With NVIDIA and now AMD doing compute-optimized GPUs, clearly the time is quickly approaching if it’s not already here.
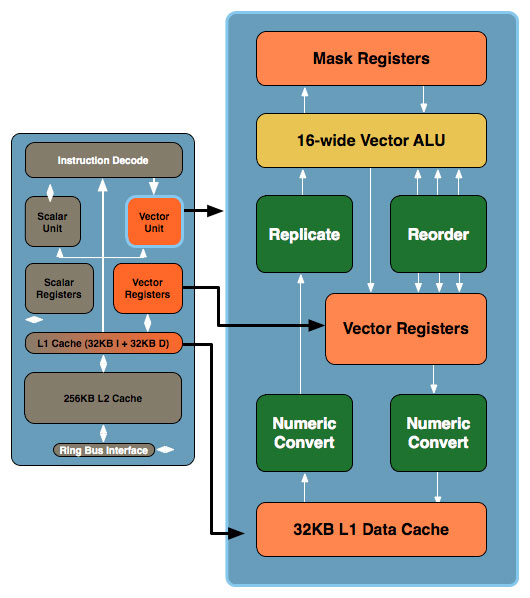
Larrabee As It Was: Scalar + 16-Wide Vector
I can’t help but to also make a comparison to Intel’s aborted Larrabee Prime architecture here. There are some very interesting similarities between Larrabee and GCN, primarily in the dual vector/scalar design and in the use of a 16-wide vector ALU. Processing 16 elements at once is an incredibly common occurrence in GPUs – it even shows up in Fermi which processes half a warp (16 threads) a clock. There are still a million differences between all of these architectures, but there’s definitely a degree of convergence occurring. Previously NVIDIA and AMD converged around VLIW in the days of the graphical GPU, and now we’re converging at a new point for the compute GPU.
Finally, while we’ve talked about the GCN architecture in great detail we haven’t talked about how to program it. Of course there’s OpenCL, but with GCN there’s going to be so much more. Next week we will be taking a look at AMD’s Fusion System Architecture, a high-level abstraction layer that will make GPU programming even more CPU-like, an advancement necessary to bring forth the kind of heterogeneous computing AMD is shooting for. We will also be taking a look at Microsoft’s C++ Accelerated Massive Parallelism (AMP), a C++ extension to bridge the gap between current and future architectures by allowing developers to program for GPUs in C++ even if the GPU doesn’t fully support the C++ feature set.
It’s clear that 2011 is shaping up to be a big year for GPUs, and we’re not even half-way through. So stay tuned, there’s much more to come.








83 Comments
View All Comments
Targon - Sunday, June 19, 2011 - link
AMD wants to put an end to the GPU in the chipset, but no one expects dedicated CPU and GPU to go away. Now, the code that would take advantage of the APU would probably work with a full AMD CPU/AMD GPU combination, so the software side of things would not need a lot of change to support both configurations.khimera2000 - Sunday, June 19, 2011 - link
Agree, dedicated cards will not go away, however intergrated cards like the past will.I think we see Eye to Eye on this. AMD wants to take full advantage of all its hardware, It looks like the way there trying to do it is by combining the CPU and Intergrated GPU into one package, after which they want to set it up so infromation that goes into that package dosent have to leave to be processed, like sending it out to ram from the CPU only to be read by the GPU.
Still want to see how this will work across PCI-E. I can already see future reviews and comparisons on how effetive GPU acceleration is on there intergrated aproach VS discreet cards. AND Buying those discreet cards :D
By the time these parts comes out my desktop will be right in the middle of its upgrade cycle :D
Targon - Monday, June 20, 2011 - link
AMD needs to push for the HTX slot again for discrete video, where there is a direct HyperTransport link between the CPU and whatever is plugged into that slot. PCI-Express is decent, but HTX would and should blow the doors off PCI-Express.rnssr71 - Friday, June 17, 2011 - link
i wish this coming next year especially in Trinity but at lest they are heading in the right direction:) also, to those wondering about improvements in gaming ability, look what amd did with cayman vs cypress- the improved efficiency and noticeably improved performance on the same manufacturing. http://www.anandtech.com/bench/Product/294?vs=331GCN this is going to improve efficiency even farther and they are cutting the transistor size roughly in half.
nlr_2000 - Saturday, June 18, 2011 - link
"Unfortunately, those of you expecting any additional graphics information will have to sight tight for the time being." sight = sitEnerJi - Saturday, June 18, 2011 - link
I wonder if this architecture would be a particularly good fit for a next-generation Xbox (due around 2013)? Any thoughts on this?GaMEChld - Saturday, June 18, 2011 - link
2013? I heard 2015, unless they recently changed dates to counter Nintendo. Anyways, I'm not so sure what benefits a console will realize from this, since full blown PC's barely get to utilize much of the technology we currently have access to. Multi-threading, 64-bit support, advanced cpu instructions are all available yet barely utilized features.Also, consoles are designed to be cost effective and relatively cheap, so usually modified older generation architecture is used. For example, the new Wii uses Radeon 4700 class graphics, which sounds old but is roughly twice as powerful as the X360 (Radeon X1900) or PS3 (GF7000) graphics.
DanNeely - Saturday, June 18, 2011 - link
That's true of the Wii because Nintendo doesn't subsidize the console, but MS and Sony have gone after higher end GPUs for their last launches. The XBox 360 launched using a GPU similar to that of the ATI 1900, a bare month and a half after the card hit the market.The PS3 used a GF7800 derivative and launched roughly 1 year after the GF7800 did. The GF7900 was nVidias top of the line card at the time, but it was only a marginal improvement over the 7800.swaaye - Saturday, June 18, 2011 - link
PS3 actually launched about when G80 came out, which obviously made RSX look awfully retro when you saw 7900GTX SLI being beaten in reviews by a single board. ;) But G80 surely was never an option for a console due to size and power.Xenos has less than half of the pixel fillrate of X1900. X1900 also has 48 pixel shader units + 8 vertex shaders so it might have an advantage over Xenos 48 unified units, especially when clock speed and the access to a large RAM pool over a 256-bit bus are taken into account.
GaMEChld - Sunday, June 19, 2011 - link
But we must also bear in mind that X360 and PS3 may have chosen high on the scale because of the concurrent shift to 720p/1080p resolution instead of the old 480p standard. At this point in time, the 1080p resolution is standardized, so greatly escalating GPU horsepower will show diminishing gains, since people aren't really going to be gaming on higher resolutions than the new standard tv resolution.What I mean is, if a Radeon 5000 Series could maximize all graphics quality at 1080p, why would a console manufacturer bother with more power?
For example, you wouldn't buy a GTX590 or Radeon 6990 just to game on a 1080p monitor, would you?
The only exception I can think of for this TV resolution argument is 3DTV gaming, in which case I am not well versed in the added GPU overhead required to render a 3D game.