OWC Mercury Extreme Pro 6G SSD Review (120GB)
by Anand Lal Shimpi on May 5, 2011 1:45 AM ESTAnandTech Storage Bench 2011 - Light Workload
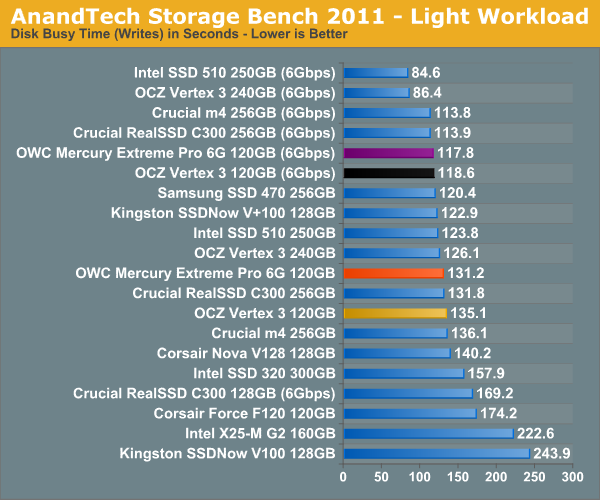
Our new light workload actually has more write operations than read operations. The split is as follows: 372,630 reads and 459,709 writes. The relatively close read/write ratio does better mimic a typical light workload (although even lighter workloads would be far more read centric).
The I/O breakdown is similar to the heavy workload at small IOs, however you'll notice that there are far fewer large IO transfers:
| AnandTech Storage Bench 2011 - Light Workload IO Breakdown | ||||
| IO Size | % of Total | |||
| 4KB | 27% | |||
| 16KB | 8% | |||
| 32KB | 6% | |||
| 64KB | 5% | |||
Despite the reduction in large IOs, over 60% of all operations are perfectly sequential. Average queue depth is a lighter 2.2029 IOs.












44 Comments
View All Comments
Anand Lal Shimpi - Thursday, May 5, 2011 - link
Those drivers were only used on the X58 platform, I use Intel's RST10 on the SNB platform for all of the newer tests/results. :)Take care,
Anand
iwod - Thursday, May 5, 2011 - link
I lost count of many times i post this series. Anyway people continue to worship 4K Random Read Write now have seen the truth. Seq Read Write is much more important then u think.Since the test are basically two identical pieces of Hardware, but one with Random Write Cap, the results shows real world doesn't show any advantage. We need more Seq performance!
Interestingly we aren't limited by the controller or NAND itself. But the connection method, SATA 6Gbps. We need to start using PCI-Express 4x slot, as Intel has shown in the leaked roadmap. Going to PCI-E 3.0 would give us 4GB/s with 4x slot. That should be plenty of room for improvement. ONFI 3.0 next year should allow us to reach 2GB+ Seq Read Write easily.
krumme - Thursday, May 5, 2011 - link
I think Anand heard to much to Intel voice in this ssd story4k random madness was Intel g2 business
And all went in the wrong direction
Anand was - and is - the ssd review site
Anand Lal Shimpi - Thursday, May 5, 2011 - link
The fact of the matter is that both random and sequential performance is important. It's Amdahl's law at its best - if you simply increase the sequential read/write speed of these drives without touching random performance, you'll eventually be limited by random performance. Today I don't believe we are limited by random performance but it's still something that has to keep improving in order for us to continue to see overall gains across the board.Take care,
Anand
Hrel - Thursday, May 5, 2011 - link
Damn! 200 dollars too expensive for the 120GB. Stopped reading.snuuggles - Thursday, May 5, 2011 - link
Good lord, every single article that discusses OWC seems to include some sort of odd-ball tangent or half-baked excuse for some crazy s**t they are pulling.Hey, I know they have the fastest stuff around, but there's just something so lame about these guys, I have to say on principle: "never, ever, will I buy from OWC"
nish0323 - Thursday, August 11, 2011 - link
What crazy s**t are they pulling? I've got 5 drives from them, all SSDs, all perform great. The 6G ones have a 5-year warranty, 2 longer than all other SSD manufacturers right now.neotiger - Thursday, May 5, 2011 - link
A lot of people and hosting companies use consumer SSD for server workload such as MySQL and Solr.Can you benchmark these SSD's performances on server workload?
Anand Lal Shimpi - Thursday, May 5, 2011 - link
It's on our roadmap to do just that... :)Take care,
Anand
rasmussb - Saturday, May 7, 2011 - link
Perhaps you have answered this elsewhere, or it will be answered in your future tests. If so, please forgive me.As you point out, the drive performance is based in large part upon the compressibility of the source data. Relatively incompressible data results in slower speeds. What happens when you put a pair (or more) of these in a RAID 0 array? Since units of data are alternating between drives, how does the SF compression work then? Does previously compressible data get less compressible because any given drive is only getting, at best (2-drive array) half of the original data?
Conversely, does incompressible data happen to get more compressible when you're splitting it amongst two or more drives in an array?
Server workload on a single drive versus in say a RAID 5 array would be an interesting comparison. I'm sure your tech savvy minds are already over this in your roadmap. I'm just asking in the event it isn't.