The OCZ Vertex 3 Review (120GB)
by Anand Lal Shimpi on April 6, 2011 6:32 PM ESTAnandTech Storage Bench 2011
I didn't expect to have to debut this so soon, but I've been working on updated benchmarks for 2011. Last year we introduced our AnandTech Storage Bench, a suite of benchmarks that took traces of real OS/application usage and played them back in a repeatable manner. I assembled the traces myself out of frustration with the majority of what we have today in terms of SSD benchmarks.
Although the AnandTech Storage Bench tests did a good job of characterizing SSD performance, they weren't stressful enough. All of the tests performed less than 10GB of reads/writes and typically involved only 4GB of writes specifically. That's not even enough exceed the spare area on most SSDs. Most canned SSD benchmarks don't even come close to writing a single gigabyte of data, but that doesn't mean that simply writing 4GB is acceptable.
Originally I kept the benchmarks short enough that they wouldn't be a burden to run (~30 minutes) but long enough that they were representative of what a power user might do with their system.
Not too long ago I tweeted that I had created what I referred to as the Mother of All SSD Benchmarks (MOASB). Rather than only writing 4GB of data to the drive, this benchmark writes 106.32GB. It's the load you'd put on a drive after nearly two weeks of constant usage. And it takes a *long* time to run.
I'll be sharing the full details of the benchmark in some upcoming SSD articles but here are some details:
1) The MOASB, officially called AnandTech Storage Bench 2011 - Heavy Workload, mainly focuses on the times when your I/O activity is the highest. There is a lot of downloading and application installing that happens during the course of this test. My thinking was that it's during application installs, file copies, downloading and multitasking with all of this that you can really notice performance differences between drives.
2) I tried to cover as many bases as possible with the software I incorporated into this test. There's a lot of photo editing in Photoshop, HTML editing in Dreamweaver, web browsing, game playing/level loading (Starcraft II & WoW are both a part of the test) as well as general use stuff (application installing, virus scanning). I included a large amount of email downloading, document creation and editing as well. To top it all off I even use Visual Studio 2008 to build Chromium during the test.
Update: As promised, some more details about our Heavy Workload for 2011.
The test has 2,168,893 read operations and 1,783,447 write operations. The IO breakdown is as follows:
| AnandTech Storage Bench 2011 - Heavy Workload IO Breakdown | ||||
| IO Size | % of Total | |||
| 4KB | 28% | |||
| 16KB | 10% | |||
| 32KB | 10% | |||
| 64KB | 4% | |||
Only 42% of all operations are sequential, the rest range from pseudo to fully random (with most falling in the pseudo-random category). Average queue depth is 4.625 IOs, with 59% of operations taking place in an IO queue of 1.
Many of you have asked for a better way to really characterize performance. Simply looking at IOPS doesn't really say much. As a result I'm going to be presenting Storage Bench 2011 data in a slightly different way. We'll have performance represented as Average MB/s, with higher numbers being better. At the same time I'll be reporting how long the SSD was busy while running this test. These disk busy graphs will show you exactly how much time was shaved off by using a faster drive vs. a slower one during the course of this test. Finally, I will also break out performance into reads, writes and combined. The reason I do this is to help balance out the fact that this test is unusually write intensive, which can often hide the benefits of a drive with good read performance.
There's also a new light workload for 2011. This is a far more reasonable, typical every day use case benchmark. Lots of web browsing, photo editing (but with a greater focus on photo consumption), video playback as well as some application installs and gaming. This test isn't nearly as write intensive as the MOASB but it's still multiple times more write intensive than what we were running last year.
As always I don't believe that these two benchmarks alone are enough to characterize the performance of a drive, but hopefully along with the rest of our tests they will help provide a better idea.
The testbed for Storage Bench 2011 has changed as well. We're now using a Sandy Bridge platform with full 6Gbps support for these tests. All of the older tests are still run on our X58 platform.
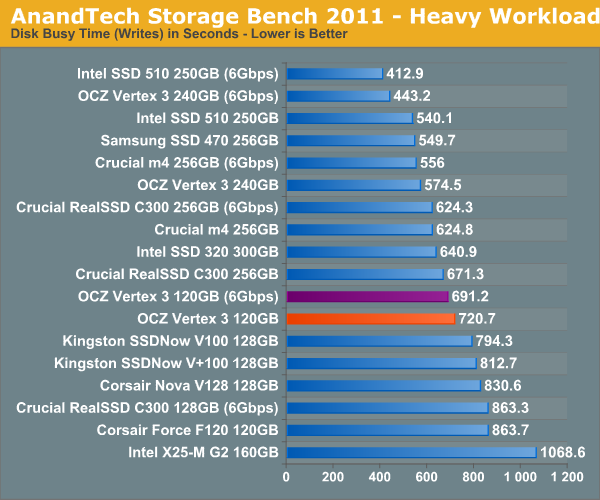
AnandTech Storage Bench 2011 - Heavy Workload
We'll start out by looking at average data rate throughout our new heavy workload test:
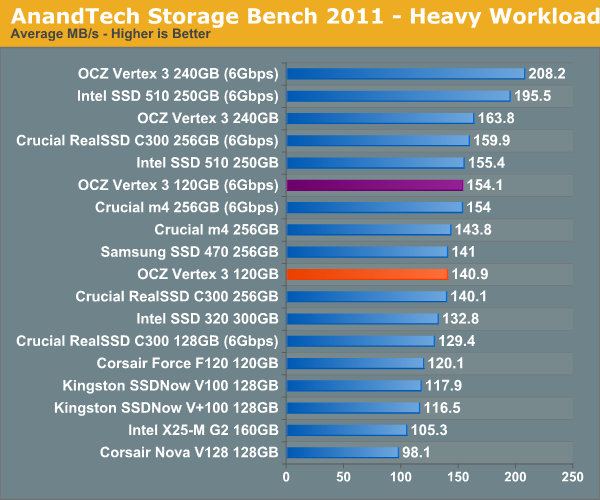
In our heavy test for 2011 the 120GB Vertex 3 is noticeably slower than the 240GB sample we tested a couple of months ago. Fewer available die are the primary explanation. We're still waiting on samples of the 120GB Intel SSD 320 and the Crucial m4 but it's looking like this round will be more competitive than we originally thought.
The breakdown of reads vs. writes tells us more of what's going on:
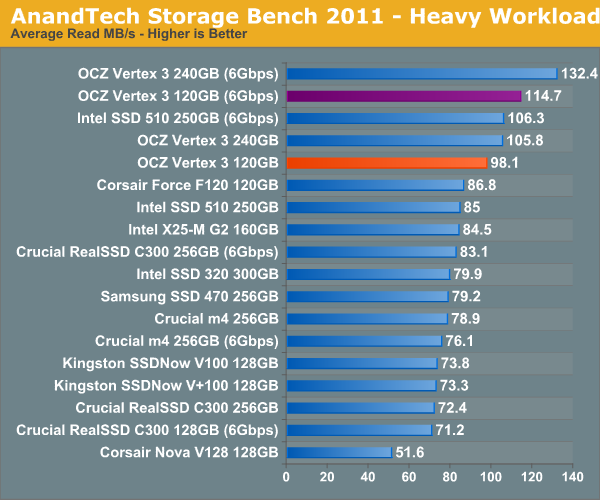
Surprisingly enough it's not read speed that holds the 120GB Vertex 3 back, it's ultimately the lower (incompressible) write speed:
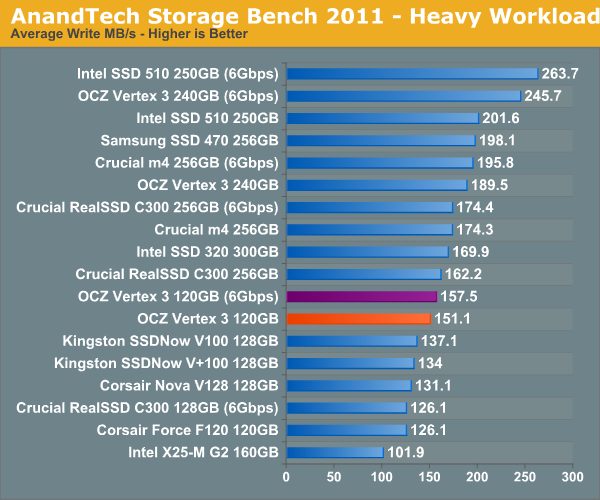
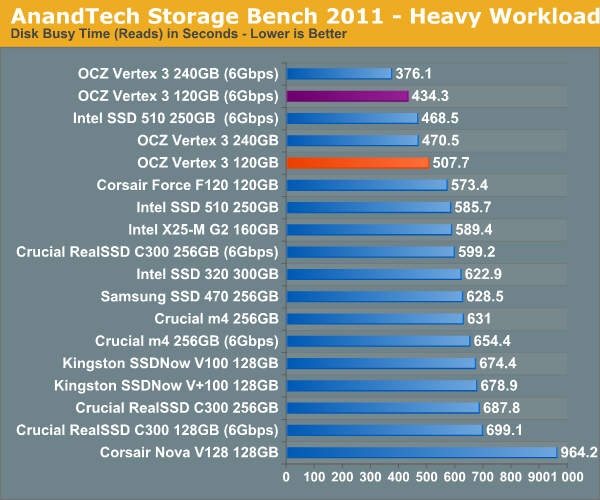
The next three charts just represent the same data, but in a different manner. Instead of looking at average data rate, we're looking at how long the disk was busy for during this entire test. Note that disk busy time excludes any and all idles, this is just how long the SSD was busy doing something:









153 Comments
View All Comments
kmmatney - Thursday, April 7, 2011 - link
The answer is pretty easy, I think. Anand's own storage bench is a great test of real world performance, especially the "typical workload"http://www.anandtech.com/show/4256/the-ocz-vertex-...
The bottom line: Version 3 is better than Verion 2, although not by an amazing amount
sunbear - Thursday, April 7, 2011 - link
"3) Finally, are you willing to commit, publicly and within a reasonable period of time, to exchanging any already purchased product for a different configuration should our readers be unhappy with what they've got?"The problem is that it is not straight forward for a customer to know "what they've got" without opening up the SSD and voiding their warranty. OCZ provides the "OCZ Toolbox" that tells you whether your SSD contains 32Gb or 64Gb NAND chips but they don't currently provide any too; to determine whether you have the dreaded Hynix flash or the superior IMFT flash.
I asked in the OCZ forum and their response was to do a secure erase and run the AS SSD benchmark. I have no idea what numbers from the AS SSD benchmark would indicate Hynix versus IMFT.
cptcolo - Friday, April 8, 2011 - link
Hats off to both Anand and OCZ for fixing the Vertex 2 issue. I am really impressed by both Anand and Alex Mei. Anand thanks fo rbeing proactive and presenting OCZ with the problem, and thanks to Alex Mei and Ryan for taking care of the problem 100% (via the change in name and SKUs). You are both true alturists.B0GiE - Friday, April 8, 2011 - link
I just cancelled my order of the 120Gb OCZ Vertex. It says on Scan webpage that it is 550mbs Read and 500mbs Write.Due to this review i'm not sure i believe it. I will wait for further reviews before I purchase a new SSD.
I am interested in game load times for the Vertex 3 such as Black Ops but Anandtech does not show any???
gietrzy - Friday, April 8, 2011 - link
I've just cancelled 120GB Vertex 3 drive. I have no time to investigate whether or not my drive performs as promised.I also have a Vertex 2 60 GB I think "E" version - how do I check if it's faulty.
My scenario is #2 at this page http://www.anandtech.com/show/4256/the-ocz-vertex-...
I also have lots of 1080p avchd videos and even more raw files from my camera so I think I will wait for Intel 510 120 GB review and buy Intel.
One thing's for sure: I will never buy OCZ again.
Thanks Anand, thanks guys!
mattcpa - Friday, April 8, 2011 - link
I ordered the 120GB Vertex 3 from Computers4Sure on the morning before you published this review... :(I also picked up an HDD Optical Bay to put my MBPro 750GB HDD there and plan to put the 120GB in the 6gbps SATA.
I use the Macbook Pro 15" 2.2 SBP for laptop DJ work along with handbraking movies and such; sprinkle in some random gaming.
Hopefully for these processes, it appears this drive will still be near the top of the pack in terms of performance, as I feel I perform many read functions daily rather than performing constant writes. If someone has an opinion, let me know if I am wrong...
Affectionate-Bed-980 - Friday, April 8, 2011 - link
Come on. You HAVE to compare against last generation's Vertex 2. It's selling for $169 at Newegg, and you don't even bench against that. Sigh. Like it's fine if you miss out on some of the other ways say the Kingston, but to skip on the Vertex 2 is a major /facepalm.Shark321 - Friday, April 8, 2011 - link
Yes, Vertex 2 and Agility 2 benchmarks compared to Vertex 3 would be really helpful here.db808 - Friday, April 8, 2011 - link
Hi Anand,First, let me join in with the others in complementing you on your excellent article.
I saw some interesting data hidden in the information describing the IO access patterns of your new IO benchmarks. I was very surprised that the IO size was so small, and that you mentioned that a majority of the IO was sequential.
Some of this can be explained by the multi-threaded nature of the tests. Two applications, each doing sequential IO, running against each other, result in interleaved IOs going to the disk, with a result that is very non-sequential. Some of this may be explained by the application runtime actually requesting 4kb IO, and Windows not having time to do "read aheads".
Windows does have the capability to do larger-IO than was requested by the application (opportunistic IOs), as well as read-ahead and write behinds(that are often coalesced into larger IOs) ... but SSDs may actually be so fast, that the Windows IO optimization algorithms don't have enough time to "think".
You also pointed out that SSD IO performance increases very quickly has the IO size increases above 4kb. It appears that most of the modern controllers parallel stripe the IO across multiple channels, wear-leveling notwithstanding. So an 8kb IO is 2 parallel 4kb IO, for example (ignoring SandForce compression behavior).
The simplest way to cajole the large share of 4kb IO's to 8kb or larger sizes is to simply increase the NTFS cluster size. This has been a performance optimization techniques used with high performance storage arrays for many years. Many Unix systems actually default to 8kb or larger block sizes, and EMC internally uses a 32kb block size as examples.
There is a small negative tradeoff ... some additional slack space at the end of every file. The average slack space per file is 1/2 the cluster size, or 2kb for the default 4kb cluster. Increasing the cluster to 8kb, increases the slack space to 4kb per file ... for a 64kb cluster, it would be 32kb slack per file. The JAM Software "Treesize" utility will actually compute the total slack space for you. With TreeSize Pro, you can even do "what if" analysis and see the impact of changing the cluster size on total slack space.
In summary, slack space overhead only represent a few percentage points of the disk capacity. For example, on my business laptop, by C: drive has about 262K files, and my total wasted space is ~ 644 MB. Increasing the cluster size to 8kb would roughly double my wasted space ... an additional 644MB. Not much.
On my hard-disk based systems that are also memory rich, I regularly run NTFS cluster sizes of 8kb and 16kb ... 64kb for temp file systems. I am pro-actively trading a few percentage points of disk space for higher performance levels. The cost of a few GB of extra overhead on a 1TB disk is a no brainer.
But SSDs are a lot more expensive, and space is a lot tighter. I use a SSD as a boot disk on one PC, and I've filled it about 1/2 full, with the OS, applications, page, hibernate, and temps. Performance is great, and the 40%-ish free space is a form of over-provisioning.
My performance was so good, I had not yet experimented with increasing my cluster size, because I was not able to quantify what the IO size profile looked like. Your IO size statistics from your IO storage benchmark was very enlightening as it shows the (unexpected) large amount of small IO.
On Sandforce-based SSDs, the controller would compress away all the slack space at the end a file, since Windows pads the last cluster in a file with zeros. So with a larger cluster size, your file system would look fuller under Windows, but all the extra slack space would be compressed on the SSD ... with little detriment to the over-provisioning headroom.
I know you are exceedingly busy, but it would be extremely interesting to be able to re-run your controlled test environment with the Anand IO Storage 2011 tests on systems that were built with different cluster sizes. I suspect that using a larger cluster size would improve performance on all SSDs, with SSDs with weaker performance showing the most relative gain. From what I have read, increasing the cluster size beyond 16kb (for Sandforce controllers) will have diminishing (but still positive) returns.
Increasing a Windows 7 boot disk's cluster size from 4kb to 16 kb would increase the wasted space about 4-fold. On my system that would be less than 3GB. It could be a worthwhile trade for performance.
Another reason to explore larger cluster sizes is the fact that the new 28nm Flash chips typically have page sizes of 8kb, not the smaller 4kb used in the 32/34 nm Flash chips. When Windows does 4kb IO on these new 28nm Flash SSDs, it is actually doing sub-page IO, causing the controller to perform a read/modify/write function, and increasing the write amplification effect. The impact would be similar to doing 2kb IO on the SSDs with 4kb page sizes.
If you assume that the typical compression factor is 2:1 for Sandforce controllers, a 16kb NTFS cluster would often be compressed to fit in a single 8kb page ... sounds like a sweet spot.
Using a larger cluster size, also decrease the amount of work needed to append to a file, as fewer clusters need to be allocated. The cluster size also defines the lower limit of contiguousness. This could be important on SSDs, since we normally don't run defrag utilities on SSDs, so we know that fragmentation will only get worse over time.
I will point out that using larger cluster sizes may increase memory usage for the kernel buffer pool, and/or reduce the effective number of buffers for a buffer pool of a given size. I only recommend increasing cluster sizes on systems in a "memory rich" environment.
Again, thank you for your excellent report. Exploring the impact of larger cluster sizes, especially on 28nm based SSDs could add an additional dimension to your analysis. 8kb and larger cluster sizes could further improve real-world SSD performance, and mask some of the performance drop from using the 28nm chips.
db
mpx999 - Sunday, April 10, 2011 - link
That's a big limitation for number of total I/Os. Eg. in 300MB/s SATA-II you'd be limited to ~37.5k IOPS with 8kB transfers, less than some SSDs are capable of, while the limit with 4kB clusters is 2 times higher, which is still beyond current SSDs for random transfers.4kB clusters are a perfect match for x86 processors that use hardware 4kB page size, as each page size is one block on disk. This is especially important for pagefile reads, which tend to be random by nature, rather than pagefile writes that are mostly sequential dumps of memory content. Some Unix systems may use 8kB disc block sizes because it's a default page size for SPARC and Itanium processors. For Power and ARM 4kB is the default but also 64kB can be used. So I'd advice against using large (larger than hw. page size) block sizes on a system/boot partition.
8kB disk block sizes can be useful on partitions dedicated for SQL Server as default database blocks are 8kB for SQL Server, so it's doing 8kB transfers anyway. Oracle supports multiple page sizes and their advice is:
http://www.dba-oracle.com/t_multiple_blocksizes_su...
"Oracle recommends smaller Oracle Database block sizes (2 KB or 4 KB) for online transaction processing (OLTP) or mixed workload environments and larger block sizes (8 KB, 16 KB, or 32 KB) for decision support system (DSS) workload environments."
32kB cluster sizes are a default value on flash cards for digital cameras, as sequential writes of large prictures are done on them.
BTW. The slow speed of both Hynix and Intel 25nm versions of Vertex 2 may be because it's aging controller cannot deal with 8kB flash pages.