OCZ Vertex 3 Pro Preview: The First SF-2500 SSD
by Anand Lal Shimpi on February 17, 2011 3:01 AM ESTThe Unmentionables: NAND Mortality Rate
When Intel introduced its X25-M based on 50nm NAND technology we presented this slide:
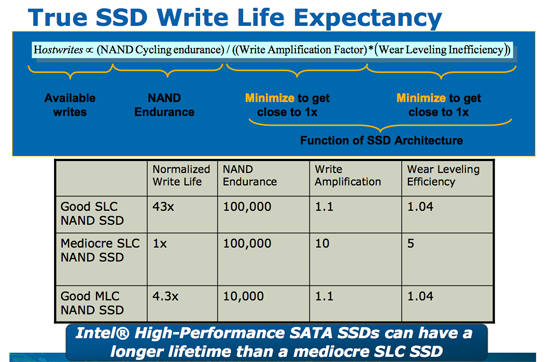
A 50nm MLC NAND cell can be programmed/erased 10,000 times before it's dead. The reality is good MLC NAND will probably last longer than that, but 10,000 program/erase cycles was the spec. Update: Just to clarify, once you exceed the program/erase cycles you don't lose your data, you just stop being able to write to the NAND. On standard MLC NAND your data should be intact for a full year after you hit the maximum number of p/e cycles.
When we transitioned to 34nm, the NAND makers forgot to mention one key fact. MLC NAND no longer lasts 10,000 cycles at 34nm - the number is now down to 5,000 program/erase cycles. The smaller you make these NAND structures, the harder it is to maintain their integrity over thousands of program/erase cycles. While I haven't seen datasheets for the new 25nm IMFT NAND, I've heard the consumer SSD grade stuff is expected to last somewhere between 3000 - 5000 cycles. This sounds like a very big problem.
Thankfully, it's not.
My personal desktop sees about 7GB of writes per day. That can be pretty typical for a power user and a bit high for a mainstream user but it's nothing insane.
Here's some math I did not too long ago:
| My SSD | |
| NAND Flash Capacity | 256 GB |
| Formatted Capacity in the OS | 238.15 GB |
| Available Space After OS and Apps | 185.55 GB |
| Spare Area | 17.85 GB |
If I never install another application and just go about my business, my drive has 203.4GB of space to spread out those 7GB of writes per day. That means in roughly 29 days my SSD, if it wear levels perfectly, I will have written to every single available flash block on my drive. Tack on another 7 days if the drive is smart enough to move my static data around to wear level even more properly. So we're at approximately 36 days before I exhaust one out of my ~10,000 write cycles. Multiply that out and it would take 360,000 days of using my machine for all of my NAND to wear out; once again, assuming perfect wear leveling. That's 986 years. Your NAND flash cells will actually lose their charge well before that time comes, in about 10 years.
Now that calculation is based on 50nm 10,000 p/e cycle NAND. What about 34nm NAND with only 5,000 program/erase cycles? Cut the time in half - 180,000 days. If we're talking about 25nm with only 3,000 p/e cycles the number drops to 108,000 days.
Now this assumes perfect wear leveling and no write amplification. Now the best SSDs don't average more than 10x for write amplification, in fact they're considerably less. But even if you are writing 10x to the NAND what you're writing to the host, even the worst 25nm compute NAND will last you well throughout your drive's warranty.
For a desktop user running a desktop (non-server) workload, the chances of your drive dying within its warranty period due to you wearing out all of the NAND are basically nothing. Note that this doesn't mean that your drive won't die for other reasons before then (e.g. poor manufacturing, controller/firmware issues, etc...), but you don't really have to worry about your NAND wearing out.
This is all in theory, but what about in practice?
Thankfully one of the unwritten policies at AnandTech is to actually use anything we recommend. If we're going to suggest you spend your money on something, we're going to use it ourselves. Not in testbeds, but in primary systems. Within the company we have 5 SandForce drives deployed in real, every day systems. The longest of which has been running, without TRIM, for the past eight months at between 90 and 100% of its capacity.
SandForce, like some other vendors, expose a method of actually measuring write amplification and remaining p/e cycles on their drives. Unfortunately the method of doing so for SandForce is undocumented and under strict NDA. I wish I could share how it's done, but all I'm allowed to share are the results.
Remember that write amplification is the ratio of NAND writes to host writes. On all non-SF architectures that number should be greater than 1 (e.g. you go to write 4KB but you end up writing 128KB). Due to SF's real time compression/dedupe engine, it's possible for SF drives to have write amplification below 1.
So how did our drives fare?
The worst write amplification we saw was around 0.6x. Actually, most of the drives we've deployed in house came in at 0.6x. In this particular drive the user (who happened to be me) wrote 1900GB to the drive (roughly 7.7GB per day over 8 months) and the SF-1200 controller in turn threw away 800GB and only wrote 1100GB to the flash. This includes garbage collection and all of the internal management stuff the controller does.

Over this period of time I used only 10 cycles of flash (it was a 120GB drive) out of a minimum of 3000 available p/e cycles. In eight months I only used 1/300th of the lifespan of the drive.
The other drives we had deployed internally are even healthier. It turns out I'm a bit of a write hog.
Paired with a decent SSD controller, write lifespan is a non-issue. Note that I only fold Intel, Crucial/Micron/Marvell and SandForce into this category. Write amplification goes up by up to an order of magnitude with the cheaper controllers. Characterizing this is what I've been spending much of the past six months doing. I'm still not ready to present my findings but as long as you stick with one of these aforementioned controllers you'll be safe, at least as far as NAND wear is concerned.








144 Comments
View All Comments
jwilliams4200 - Friday, February 18, 2011 - link
In that case, it would be helpful to print two after-TRIM benchmarks: (1) immediately after TRIM and (2) steady-state after-TRIM (i.e., TRIM, let the drive sit idle for long enough for GC to complete, then benchmark again)jcompagner - Thursday, February 17, 2011 - link
what i never understood or maybe i should read a bit more the previous articles, is that how come that a SSD can write many times faster then it can read?It seems to me that read is way easier to do then write...
vol7ron - Friday, February 18, 2011 - link
I originally thought that, but SSDs first write to the controller, which organizes the data for storing it to the disk. The major point is that the data can go anywhere in the array of NAND nodes and the list of the next available node in the stack is available almost immediately, whereas a read requires a hash lookup of where the data is stored, which means the seek could take longer to accomplish.I, as well, am not certain that's true, but that's my best guess.
AnnihilatorX - Saturday, February 19, 2011 - link
Only for Sandforce controllers.Sandforce compresses the incoming data at real time. If the incoming data is highly compressible, in a very extreme example, writting a 500MB blank text file, will be instantaneous. So you see 500MB/ms or something ridiculous.
It is also possible for write speeds to exceed read in burst when small amount of data is written to DRAM on other controllers
Soul_Master - Thursday, February 17, 2011 - link
For zero impact from source performance, I suggest to copy data from RAM drive to your test hard disk.Anand Lal Shimpi - Thursday, February 17, 2011 - link
That's a great suggestion. I ran out of time before I left the country but I'll be playing with it some more upon my return :)Take care,
Anand
MrBrownSound - Thursday, February 17, 2011 - link
I think the intel x25m was a pretty good control group to send the data from. I would auctally like to see the changes when sending the data through the RAM; that would be interesting.Hacp - Thursday, February 17, 2011 - link
Anand,You still direct your readers to your Vertex2 article but OCZ has changed its performance on those drives. Your results are no longer valid and it would be dishonest to link the old Vertex2 performance numbers in this new article when they do not reflect the new slower performance of the Vertex2 today.
Anand Lal Shimpi - Thursday, February 17, 2011 - link
I've seen the discussion and based on what I've seen it sounds like very poor decision making on OCZ's behalf. Unfortunately my 25nm drive didn't arrive before I left for MWC. I hope to have it by the time I get back next week and I'll run through the gamut of tests, updating as necessary. I also plan on speaking with OCZ about this. Let me get back to the office and I'll begin working on it :)As far as old Vertex 2 numbers go, I didn't actually use a Vertex 2 here (I don't believe any older numbers snuck in here). The Corsair Force F120 is the SF-1200 representative of choice in this test.
Take care,
Anand
Quindor - Thursday, February 17, 2011 - link
Good to hear that you are addressing the problems surrounding the Vertex 2 drives. There aren't many websites out there which deliver well thought through reviews and bechmarks such as Anandtech does, although some are getting better.I did some benchmarks on my own and with the new 25nm NAND the new 180GB OCZ Vertex2 can actually be slower then my more then a year old 120GB OCZ Vertex1.
If anyone is interested. They can find an overview of the benchmarks performed on the following page. https://picasaweb.google.com/quindor/Benchmarks#
Still, I would love to see an in depth comparsion as you are famous for. ;)
For my personal usage scenario (my own ESXi server), the speed decrease will be of minimal effect because running multiple template cloned guests, the dedup and compression should be able to do their work just fine. ;)