LG Optimus 2X & NVIDIA Tegra 2 Review: The First Dual-Core Smartphone
by Brian Klug & Anand Lal Shimpi on February 7, 2011 3:53 AM EST- Posted in
- Smartphones
- Tegra 2
- LG
- Optimus 2X
- Mobile
- NVIDIA
The GeForce ULV
Complementing the three major CPU architectures in the mobile applications processor market for 2011 there are three major GPUs you’ll see crop up in devices this year: Imagination Technologies’ PowerVR SGX Series5 and Series5XT, Qualcomm’s Adreno 205/220 and NVIDIA’s GeForce ULV. There are other players but these three are the ones that will show up in the most exciting devices this year.
ImgTec licenses its GPUs for use in a number of SoCs. Apple’s A4, TI’s OMAP 3 and 4 and Samsung’s Hummingbird all use ImgTec GPUs. The currently used high end from ImgTec is the PowerVR SGX 540, which features four unified shader pipelines capable of handling both pixel and vertex shader operations. The PowerVR SGX 543 is widely expected to be used in Apple’s 5th generation SoC.
The PowerVR SGX as well as Qualcomm’s Adreno GPUs both implement tile based deferred rendering architectures. In the early days of the PC GPU race deferred renderers were quite competitive. As geometry complexity in games increased, ATI and NVIDIA’s immediate mode rendering + hidden surface removal proved to be the better option. Given the lack of serious 3D gaming, much less geometry heavy titles on smartphones today the tile based approach makes a lot of sense. Tile based renderers conserve both power and memory bandwidth, two things that are in very short supply on smartphones. Remember from our CPU discussions that in many cases only a single 32-bit LPDDR2 memory channel has to feed two CPU cores as well as the GPU. By comparison, even PCs from 10 years ago had a 64-bit memory bus just for the CPU and a 128-bit memory bus for the GPU.
NVIDIA believes that the future of GPUs on smartphones is no different than the future of PC GPUs: immediate mode renderers. As a result, the GeForce ULV GPU in NVIDIA’s Tegra 2 looks very similar to a desktop GPU—just a lot smaller, and a lot lower power. It’s also worth pointing out that until we get PC-like content on smartphones, NVIDIA’s approach to ultra mobile GPU architectures may not always make the most sense for power efficiency.
(Note that some of what follows below is borrowed from our earlier coverage of NVIDIA's Tegra 2):
At a high level NVIDIA is calling the GeForce ULV an 8-core GPU, however its not a unified shader GPU. Each core is an ALU but half of them are used for vertex shaders and the other half are for pixel shaders. You can expect the GeForce ULV line to take a similar evolutionary path to desktop GeForce in the future (meaning it’ll eventually be a unified shader architecture).
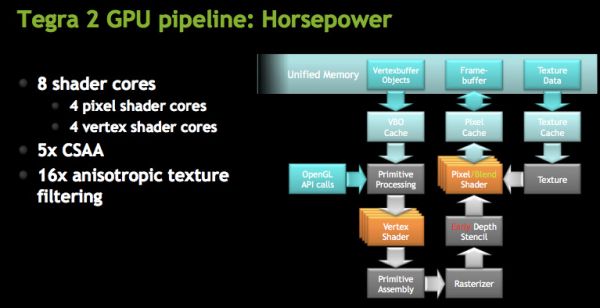
The four vertex shader cores/ALUs can do a total of 4 MADDs per clock, the same is true for the four pixel shader ALUs (4 MADDs per clock).
The GeForce ULV in NVIDIA’s Tegra 2 runs at a minimum of 100MHz but it can scale up to 400MHz depending on the SoC version:
| NVIDIA Tegra 2 | ||||||
| SoC | Part Number | CPU Clock | GPU Clock | Availability | ||
| NVIDIA Tegra 2 | T20 | 1GHz | 333MHz | Now | ||
| NVIDIA Tegra 2 | AP20H | 1GHz | 300MHz | Now | ||
| NVIDIA Tegra 2 3D | T25 | 1.2GHz | 400MHz | Q2 2011 | ||
| NVIDIA Tegra 2 3D | AP25 | 1.2GHz | 400MHz | Q2 2011 | ||
The AP20H runs at up to 300MHz, while the tablet version runs at a faster 333MHz.
Architecturally, the GeForce ULV borrows several technologies that only recently debuted on desktop GPUs. GeForce ULV has a pixel cache, a feature that wasn’t introduced in GeForce on the desktop until Fermi. This is purely an efficiency play as saving any trips to main memory reduces power consumption considerably (firing up external interfaces always burns watts quicker than having data on die).
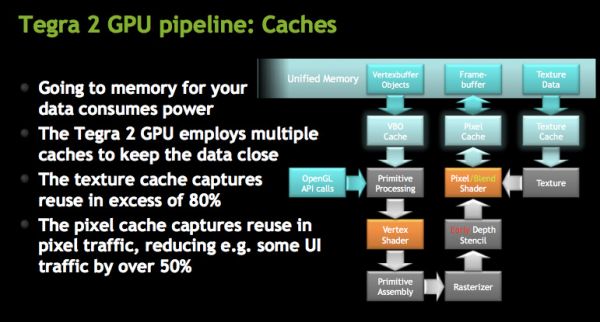
NVIDIA also moved the register files closer to the math units, again in the pursuit of low power consumption. GeForce ULV is also extremely clock gated although it’s not something we’re able to quantify.
NVIDIA did reduce the number of pipeline stages compared to its desktop GPUs by a factor of 2.5 to keep power consumption down.
The GeForce ULV supports Early Z culling, a feature first introduced on the desktop with G80. While G80 could throw away around 64 pixels per clock, early Z on GeForce ULV can throw away 4 pixels per clock. While early Z isn’t the equivalent of a tile based renderer, it can close the efficiency gap between immediate mode renderers and TBRs.
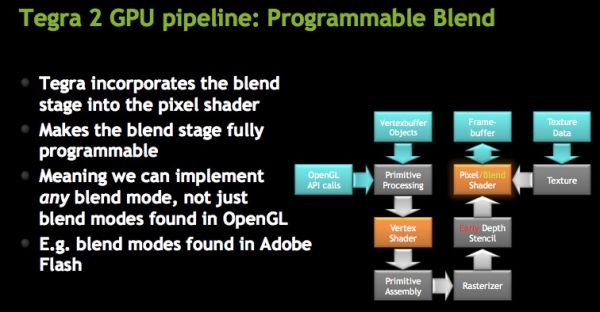
The ROPs are integrated into the pixel shader, making what NVIDIA calls a programmable blend unit. GeForce ULV uses the same ALUs for ROPs as it does for pixel shaders. This hardware reuse saves die size although it adds control complexity to the design. The hardware can perform one texture fetch and one ROP operation per clock.
While GeForce ULV supports texture compression, it doesn’t support frame buffer compression.
Both AA and AF are supported by GeForce ULV. NVIDIA supports 5X coverage sample AA (same CSAA as we have on the desktop) and up to 16X anisotropic filtering.
The performance comparison is far more difficult to quantify in the ultra mobile space than among desktop GPUs. There are some very good 3D games out for Android and iOS, unfortunately none of them have built in benchmarks. There are even those that would make for good performance tests however OEM agreements and politics prevent them from being used as such. At the other end of the spectrum we have a lot of absolutely horrible 3D benchmarks, or games with benchmarks that aren’t representative of current or future game performance. In between the two extremes we have some benchmark suites (e.g. GLBenchmark) that aren’t representative of current or future GPU performance, but they also aren’t completely useless. Unfortunately today we’ll have to rely on a mixture of all of these to paint a picture of how NVIDIA’s GeForce ULV stacks up to the competition.
Just as is the case in the PC GPU space, game and driver optimizations play as large of a role in performance as the GPU architecture itself. NVIDIA believes that its experience with game developers will ultimately give it the edge in the performance race. It’s far too early to tell as most of NVIDIA’s partners aren’t even playing in the smartphone space yet. However if PC and console titles make their way to smartphones, NVIDIA’s experience and developer relationships may prove to be a tremendous ally.








75 Comments
View All Comments
GoodRevrnd - Tuesday, February 8, 2011 - link
TV link would be awesome, but why would you need the phone to bridge the TV and network??aegisofrime - Monday, February 7, 2011 - link
May I suggest x264 encoding as a test of the CPU power? There's a version of x264 available for ARM chips, along with NEON optimizations. Should be interesting!Shadowmaster625 - Monday, February 7, 2011 - link
What is the point in having a high performance video processor when you cannot do the two things that actually make use of it? Those two things are: 1. Watch any movie in your collection without transcoding? (FAIL) 2. Play games. No actual buttons = FAIL. If you think otherwise then you dont actually play games. Just stick with facebook flash trash.TareX - Wednesday, February 9, 2011 - link
The only reason I'd pay for a dual core phone is smooth flash-enabled web browsing, not gaming.zorxd - Monday, February 7, 2011 - link
Stock Android has it too. There is also E for EDGE and G for GPRS.Exophase - Monday, February 7, 2011 - link
Hey Anand/Brian,There are some issues I've found with some information in this article:
1) You mention that Cortex-A8 is available in a multicore configuration. I'm pretty sure there's no such thing; you might be thinking of ARM11MPCore.
2) The floating point latencies table is just way off for NEON. You can find latencies here:
http://infocenter.arm.com/help/index.jsp?topic=/co...
It's the same in Cortex-A9. The table is a little hard to read; you have to look at the result and writeback stages to determine the latency (it's easier to read the A9 version). Here's the breakdown:
FADD/FSUB/FMUL: 5 cycles
FMAC: 9 cycles (note that this is because the result of the FMUL pipeline is then threaded through the FADD pipeline)
The table also implies Cortex-A9 adds divide and sqrt instructions to NEON. In actuality, both support reciprocal approximation instructions in SIMD and full versions in scalar. The approximation instructions have both initial approximation with ~9 bits of precision and Newton Rhapson step instructions. The step instructions function like FMACs and have similar latencies. This kind of begs the question of where the A9 NEON DIV and SQRT numbers came from.
The other issue I have with these numbers is that it only mentions latency and not throughput. The main issue is that the non-pipelined Cortex-A8 FPU has throughput almost as bad as its latency, while all of the other implementations have single cycle throughput for 2x 64-bit operations. Maybe throughput is what you mean by "minimum latency", however this would imply that Cortex-A9 VFP can't issue every cycle, which isn't the case.
3) It's obvious from the GLBenchmark 2.0 Pro screenshot that there are some serious color limitations from Tegra 2 (look at the woman's face). This is probably due to using 16-bit. IMG has a major advantage in this area since it renders at full 32-bit (or better) precision internally and can dither the result to 16-bit to the framebuffer, which looks surprisingly similar in quality to non-dithered 32-bit. This makes a 16-bit vs 16-bit framebuffer comparison between the two very unbalanced - it's far more fair to just do both at 32-bit, but it doesn't look like the benchmark has any option for it. Furthermore, Tegra 2 is limited to 16-bit (optionally non-linear) depth buffers, while IMG utilizes 32-bit floating point depth internally. This is always going to be a disadvantage for Tegra 2 and is definitely worth mentioning in any comparison.
Finally I feel like ranting a little bit about your use of the Android Linpack test. Anyone with a little common sense can tell that a native implementation of Linpack on these devices will yield several dozen times more than 40MFLOPS (should be closer to 1-4 FLOP/CPU cycle). What you see here is a blatant example of Dalvik's extreme inability to perform with floating point code that extends well beyond an inability to perform SIMD vectorization.
metafor - Monday, February 7, 2011 - link
According to the developer of Linpack on Android:http://www.greenecomputing.com/category/android/
It is mostly FP64 calculations done on Dalvik. While this may not be the fastest way to go about doing linear algebra, it is a fairly good representation of relative FP64 performance (which only exist in VFP).
And let's face it, few app developers are going to dig into Android's NDK and write NEON optimized code.
Exophase - Monday, February 7, 2011 - link
Then let's ask this instead: who really cares about FP64 performance on a smartphone? I'd also argue that it is not even a good representation of relative FP64 performance since that's being obscured so much by the quality of the JITed code. Hence why you see Scorpion and A9 perform a little over twice as fast as A8 (per-clock) instead of several times faster. VFP is still in-order on Cortex-A9, competent scheduling matters.Maybe a lot of developers won't write NEON code on Android, but where it's written it could very well matter. For one thing, in Android itself. And theoretically one day Dalvik could actually be generating NEON competently.. so some synthetic tests of NEON could be a good look at what could be.
metafor - Monday, February 7, 2011 - link
Well, few people really :)Linpack as it currently exists on Android probably doesn't tell very much at all. But if you're just going to slap together an FP heavy app (pocket scientific computing anyone?) and aren't a professional programmer, this likely represents the result you see.
I wouldn't mind seeing SpecFP ported natively to Android and running NEON. But alas, we'd need someone to roll up their sleeves and do that.
I did do a native compile of Linpack using gcc to test on my Evo, though. It's still not SIMD code, of course, but native results using VFP were around the 70-80MFLOPS mark. Of course, it's scheduling for the A8's FPU and not Scorpion's.
Anand Lal Shimpi - Monday, February 7, 2011 - link
Thanks for your comment :)1) You're very right, I was thinking about the ARM11 - fixed :)
2) Make that 2 for 2. You're right on the NEON values, I mistakenly grabbed the values from the cycles column and not the result column. The DIV/SQRT columns were also incorrect, I removed them from the article.
I mentioned the lack of pipelining in the A8 FPU earlier in the article but I reiterated it underneath the table to hammer the point home. I agree that the lack of pipelining is the major reason for the A8's poor FP performance.
3) Those screenshots were actually taken on IMG hardware. IMG has some pretty serious rendering issues running GLBenchmark 2.0.
4) I'm not happy with the current state of Android benchmarks - Linpack included. Right now we're simply including everything we can get our hands on, but over the next 24 months I think you'll see us narrow the list and introduce more benchmarks that are representative of real world performance as well as contribute to meaningful architecture analysis.
Take care,
Anand