AMD's Radeon HD 6970 & Radeon HD 6950: Paving The Future For AMD
by Ryan Smith on December 15, 2010 12:01 AM ESTVLIW4: Finding the Balance Between TLP, ILP, and Everything Else
To properly frame why AMD went with a VLIW4 design we’d have to first explain why AMD went with a VLIW5 design. And to do that we’d have to go back even further to the days of DirectX 9, and thus that is where we will start.
Back in the days of yore, when shading was new and pixel and vertex shaders were still separate entities, AMD (née ATI) settled on a VLIW5 design for their vertex shaders. Based on their data this was deemed the ideal configuration for a vertex shader block, as it allowed them to process a 4 component dot product (e.g. w, x, y, z) and a scalar component (e.g. lighting) at the same time.
Fast forward to 2007 and the introduction of AMD’s Radeon HD 2000 series (R600), where AMD introduced their first unified architecture for the PC. AMD went with a VLIW5 design once more, as even though the product was their first DX10 product it still made sense to build something that could optimally handle DX9 vertex shaders. This was also well before GPGPU had a significant impact on the market, as AMD had at best toyed around with the idea late in the X1K series’ lifetime (and well after R600 was started).

Now let us jump to 2008, when Cayman’s predecessors were being drawn up. GPGPU computing is still fairly new – NVIDIA is at the forefront of a market that only amounts to a few million dollars at best – and DX10 games are still relatively rare. With 2+ years to bring up a GPU, AMD has to be looking forward at where things will be in 2010. Their predictions are that GPGPU computing will finally become important, and that DX9 games will fade in importance to DX10/11 games. It’s time to reevaluate VLIW5.
This brings us to the present day and the launch of Cayman. GPGPU computing is taking off, and DX10 & DX11 alongside Windows 7 are gaining momentum while DX9 is well past its peak. AMD’s own internal database of games tells them an interesting story: the average slot utilization is 3.4 – on average a 5th streaming processor is going unused in games. VLIW5, which made so much sense for DX9 vertex shaders is now becoming too wide, while scalar and narrow workloads are increasing in number. The stage is set for a narrower Streaming Processor Unit; enter VLIW4.
As you may recall from a number of our discussions on AMD’s core architecture, AMD’s architecture is heavily invested in Instruction Level Parallelism, that is having instructions in a single thread that have no dependencies on each other that can be executed in parallel. With VLIW5 the best case scenario is that 5 instructions can be scheduled together on every SPU every clock, a scenario that rarely happens. We’ve already touched on how in games AMD is seeing an average of 3.4, which is actually pretty good but still is under 80% efficient. Ultimately extracting ILP from a workload is hard, leading to a wide delta between the best and worst case scenarios.
Meanwhile all of this is in stark contrast to Thread Level Parallelism (TLP), which looks for threads that can be run at the same time without having any interdependencies. This is where NVIDIA has focused their energies at the high-end, as GF100/GF100 are both scalar architectures that rely on TLP to achieve efficient operation.
Ultimately the realization is that AMD’s VLIW5 architecture is not the best architecture going forward. Up until now it has made sense at a high efficiency gaming-oriented design, and even today in a gaming part like the 6800 series it’s still a reasonable choice. But AMD needs a new architecture for the future, not only as something that’s going to better fit their 3.4 shader average, but something that is better designed for compute workloads. AMD’s choice is an overhauled version of their existing architecture. Overall it’s built on a solid foundation, but VLIW5 is too wide to meet their future goals.
The solution is to shrink their VLIW5 SPU to a VLIW4 SPU. Specifically, the solution is to remove the t-unit, the architecture’s 5th SP and largest SP that’s capable of both regular INT/FP operations as well as being responsible for transcendental operations. In the case of regular INT/FP operations this means an SPU is reduced from being able to process 5 operations at once to 4. While in the case of transcendentals an SPU now ties together 3 SPs to process 1 transcendental in the same period of time, representing a much more severe reduction in theoretical performance as an SPU can only process 1 transcendental + 1 INT/FP per clock as opposed to 1 transcendental + 4 INT/FP operations (or any variations).
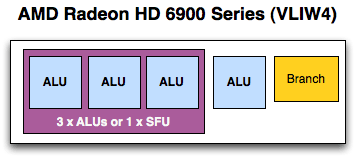
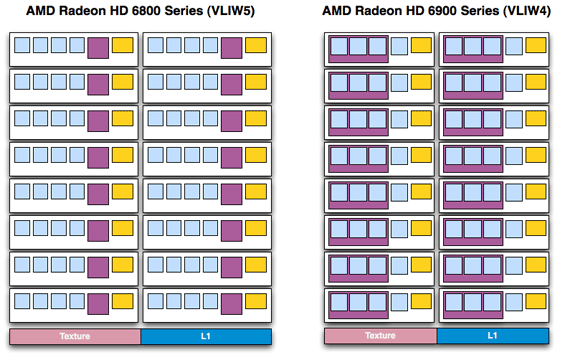
There are a number of advantages to this change. As far as compute is concerned, the biggest advantage is that much of the space previously allocated to the t-unit can now be scrounged up to build more SIMDs. Cypress had 20 SIMDs while Cayman has 24; on average Cayman’s shader block is 10% more efficient per mm2 than Cypress’s , taking in to account the fact that Cayman’s SPs are a bit larger than Cypress’ to pick up the workload the t-unit would handle. The SIMDs are further tied to a number of attributes: the number of texture units, the number of threads that can be in flight at once, and the number of FP64 operations that can be completed per clock. The latter is particularly important for AMD’s compute efforts, as they can now retire FP64 FMA/MUL operations at 1/4th their FP32 rate, in the case of a full Cayman up to 384/clock. Technically speaking they’re no faster per SPU, but with this layout change they have more SPUs to work with, improving their performance.
Fewer SPs per SIMD = More Space For More SIMDs
There are even ancillary benefits within the individual SPUs. While the SP count changed the register file did not, leading to less pressure on each SPU’s registers as now only 4 SPs vie for register space. Even scheduling is easier as there are fewer SPs to schedule and the fact that they’re all alike means the scheduler no longer has to take into consideration the difference between the w/x/y/z units and the t-unit.
Meanwhile in terms of gaming the benefits are similar. Games that were already failing to fully utilize the VLIW5 design now have additional SIMDs to take advantage of, and as rendering is still an embarrassingly parallel operation as far as threading is concerned, it’s very easy to further divide the rendering workload in to more threads to take advantage of this change. The extra SIMDs mean that Cayman has additional texturing horsepower over Cypress, and the overall compute:texture ratio has been reduced, a beneficial situation for any games that are texture/filtering bound more than they’re compute bound.
Of course any architectural change involves tradeoffs, so it’s not a pure improvement. For gaming the tradeoff is that Cayman isn’t going to be well suited to VLIW5-style vertex shaders; generally speaking games using such shaders already run incredibly fast, but if they’re even GPU-bound in the first place they’re not going to gain much from Cayman. The other big tradeoff is when transcendental operations are paired with vector operations, as Cypress could handle both in one clock while Cayman will take two. It’s AMD’s belief that these operations are rare enough that the loss of performance in this one situation is worth it for the gain in performance everywhere else.
It’s worth noting that AMD still considers VLIW4 to be a risky/experimental design, or at least this is their rationale for going with it first on Cayman while sticking to VLIW5 elsewhere. At this point we’d imagine the real experiment to already be over, as AMD would already be well in the middle of designing Cayman’s 28nm successor, so they undoubtedly know if they’ll be using VLIW4 in the future.
Finally, the switch to a new VLIW architecture means the AMD driver team has to do some relearning. While VLIW4 is quite similar to VLIW5 it’s not by any means identical, which is both good and bad for performance purposes. The bad news is that it means many of AMD’s VLIW5-centric shader compiler tricks are no longer valid; at the start shader compiler performance is going to be worse while AMD learns how to better program a VLIW4 design. The good news is that in time they’re going to learn how to better program a VLIW4 design, meaning there’s the potential for sizable performance increases throughout the lifetime of the 6900 series. That doesn’t mean they’re guaranteed, but we certainly expect at least some improvement in shader performance as the months wear on.
On that note these VLIW changes do mean that some code is going to have to be rewritten to better deal with the reduction of VLIW width. AMD’s shader compiler goes through a number of steps to try to optimize code, but if kernels were written specifically to organize instructions to go through AMD’s shaders in a 5-wide fashion, then there’s only so much AMD’s compiler can do. Of course code doesn’t have to be written that way, but it is the best way to maximize ILP and hence shader performance.
VLIW5:
- 4 32-bit FP MAD
- Or 2 64-bit FP MUL or ADD
- Or 1 64-bit FP MAD
- Or 4 24-bit Int MUL or ADD
- Plus 1 transcendental or 1 32-bit FP MAD
VLIW4:
- 4 32-bit FP MAD/MUL/ADD
- Or 2 64-bit FP ADD
- Or 1 64-bit FP MAD/FMA/MUL
- Or 4 24-bit INT MAD/MUL/ADD
- Or 4 32-bit INT ADD/Bitwise
- Or 1 32-bit MAD/MUL
- Or 1 64-bit ADD
- Or 1 transcendental plus 1 32-bit FP MAD








168 Comments
View All Comments
cyrusfox - Wednesday, December 15, 2010 - link
You should totally be able to do a 4X1 display, 2 DP and 2 DVI, as long as one of those DP dells also has a DVI input. That would get rid of the need for your usb-vga adapter.gimmeagdlaugh - Wednesday, December 15, 2010 - link
Not sure why AMD 6970 has green bar,while NV 580 has red bar...?
medi01 - Wednesday, December 15, 2010 - link
Also wondering. Did nVidia marketing guys called again?Ryan Smith - Wednesday, December 15, 2010 - link
I normally use green for new products. That's all there is to it.JimmiG - Wednesday, December 15, 2010 - link
Still don't like the idea of Powertune. Games with a high power load are the ones that fully utilize many parts of the GPU at the same time, while less power hungry games only utilize parts of it. So technically, the specifications are *wrong* as printed in the table on page one.The 6970 does *not* have 1536 stream processors at 880 MHz. Sure, it may have 1536 stream processors, and it may run at up to 880 MHz.. But not at the same time!
So if you fully utilize all 1536 processors, maybe it's a 700 MHz GPU.. or to put it another way, if you want the GPU to run at 880 MHz, you may only utilize, say 1200 stream processors.
cyrusfox - Wednesday, December 15, 2010 - link
I think Anand did a pretty good job of explaining at how it reasonably power throttles the card. Also as 3rd party board vendors will probably make work-arounds for people who abhor getting anything but the best performance(even at the cost of efficiency). I really don't think this is much of an issue, but a good development that is probably being driven by Fusion for Ontario, Zacate, and llano. Also only Metro 2033 triggered any reduction(850Mhz from 880Mhz). So your statement of a crippled GPU only holds for Furmark, nothing got handicapped to 700Mhz. Games are trying to efficiently use all the GPU has to offer, so I don't believe we will see many games at all trigger the use of powertune throttling.JimmiG - Wednesday, December 15, 2010 - link
Perhaps, but there's no telling what kind of load future DX11 games, combined with faster CPUs will put on the GPU. Programs like Furmark don't do anything unusual, they don't increase GPU clocks or voltages or anything like that - they just tell the GPU - "Draw this on the screen as fast as you can".It's the same dilemma overclockers face - Do I keep this higher overclock that causes the system to crash with stress tests but works fine with games and benchmarks? Or do I back down a few steps to guarantee 100% stability. IMO, no overclock is valid unless the system can last through the most rigorous stress tests without crashes, errors or thermal protection kicking in.
Also, having a card that throttles with games available today tells me that it's running way to close to the thermal limit. Overclocking in this case would have to be defined as simply disabling the protection to make the GPU always work at the advertised speed.
It's a lazy solution, what they should have done is go back to the drawing board until the GPU hits the desired performance target while staying within the thermal envelope. Prescott showed that you can't just keep adding stuff without any considerations for thermals or power usage.
AnnihilatorX - Wednesday, December 15, 2010 - link
Didn't you see you can increase the throttle threshold by 20% in Catalyst Control Centre. This means 300W until it throttles, which in a sense disables the PowerTune.Mr Perfect - Thursday, December 16, 2010 - link
On page eight Ryan mentions that Metro 2033 DID get throttled to 700MHz. The 850MHz number was reached by averaging the amount of time Metro was at 880MHz with the time it ran at 700MHz.Which is a prime example of why I hate averages in reviews. If you have a significantly better "best case", you can get away with a particularly bad "worst case" and end up smelling like roses.
fausto412 - Wednesday, December 15, 2010 - link
CPU's have been doing this for a while...and you are allowed to turn the feature off. AMD is giving you a range to go over.It will cut down on RMA's, Extend Reliability.