AMD's Radeon HD 6970 & Radeon HD 6950: Paving The Future For AMD
by Ryan Smith on December 15, 2010 12:01 AM ESTCayman: The New Dawn of AMD GPU Computing
We’ve already covered how the shift from VLIW5 to VLIW4 is beneficial for AMD’s computing efforts: narrower SPUs are easier to fully utilize, FP64 performance improves to 1/4th FP32 performance, and the space savings give AMD room to lay down additional SIMDs to improve performance. But if Cayman is meant to be a serious effort by AMD to relaunch themselves in to the GPU computing market and to grab a piece of NVIDIA’s pie, it takes more than just new shaders to accomplish the task. Accordingly, AMD has been hard at work to round out the capabilities of their latest GPU to make it a threat for NVIDIA’s Fermi architecture.
AMD’s headline compute feature is called asynchronous dispatch, a long word that actually does a pretty good job of describing what it does. To touch back on Fermi for a moment, with Fermi NVIDIA introduced support for parallel kernels, giving Fermi the ability to execute multiple kernels at once. AMD in turn is following NVIDIA’s approach of executing multiple kernels at once, but is going to take it one step further.
The limit of NVIDIA’s design is that while Fermi can execute multiple kernels at once, each one must come from the same CPU thread. Independent threads/applications for example cannot issue their own kernels and have them execute in parallel, rather the GPU must context switch between them. With asynchronous dispatch AMD is going to allow independent threads/applications to issue kernels that execute in parallel. On paper at least, this would give AMD’s hardware a significant advantage in this scenario (context switching is expensive), one that would likely eclipse any overall performance advantages NVIDIA had.
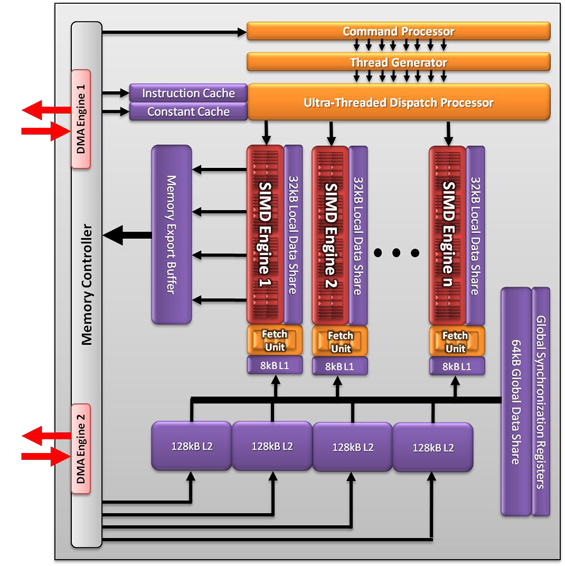
Fundamentally asynchronous dispatch is achieved by having the GPU hide some information about its real state from applications and kernels, in essence leading to virtualization of GPU resources. As far as each kernel is concerned it’s running in its own GPU, with its own command queue and own virtual address space. This places more work on the GPU and drivers to manage this shared execution, but the payoff is that it’s better than context switching.
For the time being the catch for asynchronous dispatch is that it requires API support. As DirectCompute is a fixed standard this just isn’t happening – at least not with DirectCompute 11. Asynchronous dispatch will be exposed under OpenCL in the form of an extension.
Meanwhile the rest of AMD’s improvements are focusing on memory and cache performance. While the fundamental architecture is not changing, there are several minor changes here to improve compute performance. The Local Data Store attached to each SIMD is now able to bypass the cache hierarchy and Global Data Store by having memory fetches read directly in to the LDS. Meanwhile Cayman is getting a 2nd DMA engine, improving memory reads & writes by allowing Cayman to execute two at once in each direction.
Finally, read ops from shaders are being sped up a bit. Compared to Cypress, Cayman can coalesce them in to fewer operations.
As today’s launch is primarily about the Radeon HD 6900 series AMD isn’t going too much in depth on the compute side of things, so everything here is a fairly high level overview of the architecture. Once AMD has Firestream cards ready to go with Cayman in them, there will likely be more to talk about.








168 Comments
View All Comments
fausto412 - Wednesday, December 15, 2010 - link
6970 just 4 to 6 fps faster in Bad Company 2 than my 5870? WTF!not worth the upgrade. what a lame ass successor.
Kibbles - Wednesday, December 15, 2010 - link
It's 7% faster at 1920 and 9% faster at 2560. BC2 obviously doesn't need the extra GPU power at 1680.I wouldn't call it weak, but this card certainly isn't the clear winner that the 5870 was.
fausto412 - Wednesday, December 15, 2010 - link
its weak if i was expecting a response to the gtx580 to upgrade to.may as well stay with my 5870.
ClownPuncher - Wednesday, December 15, 2010 - link
For now... But who really bases their purchase on one game anymore? It looks like 10.12 or 11.1 drivers will help performance a good amount.fausto412 - Wednesday, December 15, 2010 - link
I base my performance on 1 game...because it is a very taxing game and my #1 game right now.MeanBruce - Wednesday, December 15, 2010 - link
Yup, dude I heard the AMD 7000 series might make an early appearance next July, with the die shrink @28nm you might want to wait and pick up a 7970!fausto412 - Wednesday, December 15, 2010 - link
that's what i'm considering now. need to upgrade for 30% more performance than 5870 for it to make sense.Stuka87 - Wednesday, December 15, 2010 - link
The game is CPU limited at lower resolutions. BC2 is known for being more CPU bound than GPU bound.But I was hoping for a larger jump over the previous cards :/
fausto412 - Wednesday, December 15, 2010 - link
I understand BFBC2 is more cpu bound. But in this testing Anandtech did they use a TOP TOP TOP of the line cpu so that rules that out as a bottleneck.Belard - Wednesday, December 15, 2010 - link
Yeah... at least the model numbers didn't make things confusing!In some benchmarks, the 6950 is faster than your 5870... but it would have made far more sense to call these 6850/6870 or even 6830/6850..
AMD screwed up with the new names...