NVIDIA's GeForce GTX 580: Fermi Refined
by Ryan Smith on November 9, 2010 9:00 AM ESTGF110: Fermi Learns Some New Tricks
We’ll start our in-depth look at the GTX 580 with a look at GF110, the new GPU at the heart of the card.
There have been rumors about GF110 for some time now, and while they ultimately weren’t very clear it was obvious NVIDIA would have to follow up GF100 with something else similar to it on 40nm to carry them through the rest of the processes’ lifecycle. So for some time now we’ve been speculating on what we might see with GF100’s follow-up part – an outright bigger chip was unlikely given GF100’s already large die size, but NVIDIA has a number of tricks they can use to optimize things.
Many of those tricks we’ve already seen in GF104, and had you asked us a month ago what we thought GF110 would be, we were expecting some kind of fusion of GF104 and GF100. Primarily our bet was on the 48 CUDA Core SM making its way over to a high-end part, bringing with it GF104’s higher theoretical performance and enhancements such as superscalar execution and additional special function and texture units for each SM. What we got wasn’t quite what we were imagining – GF110 is much more heavily rooted in GF100 than GF104, but that doesn’t mean NVIDIA hasn’t learned a trick or two.
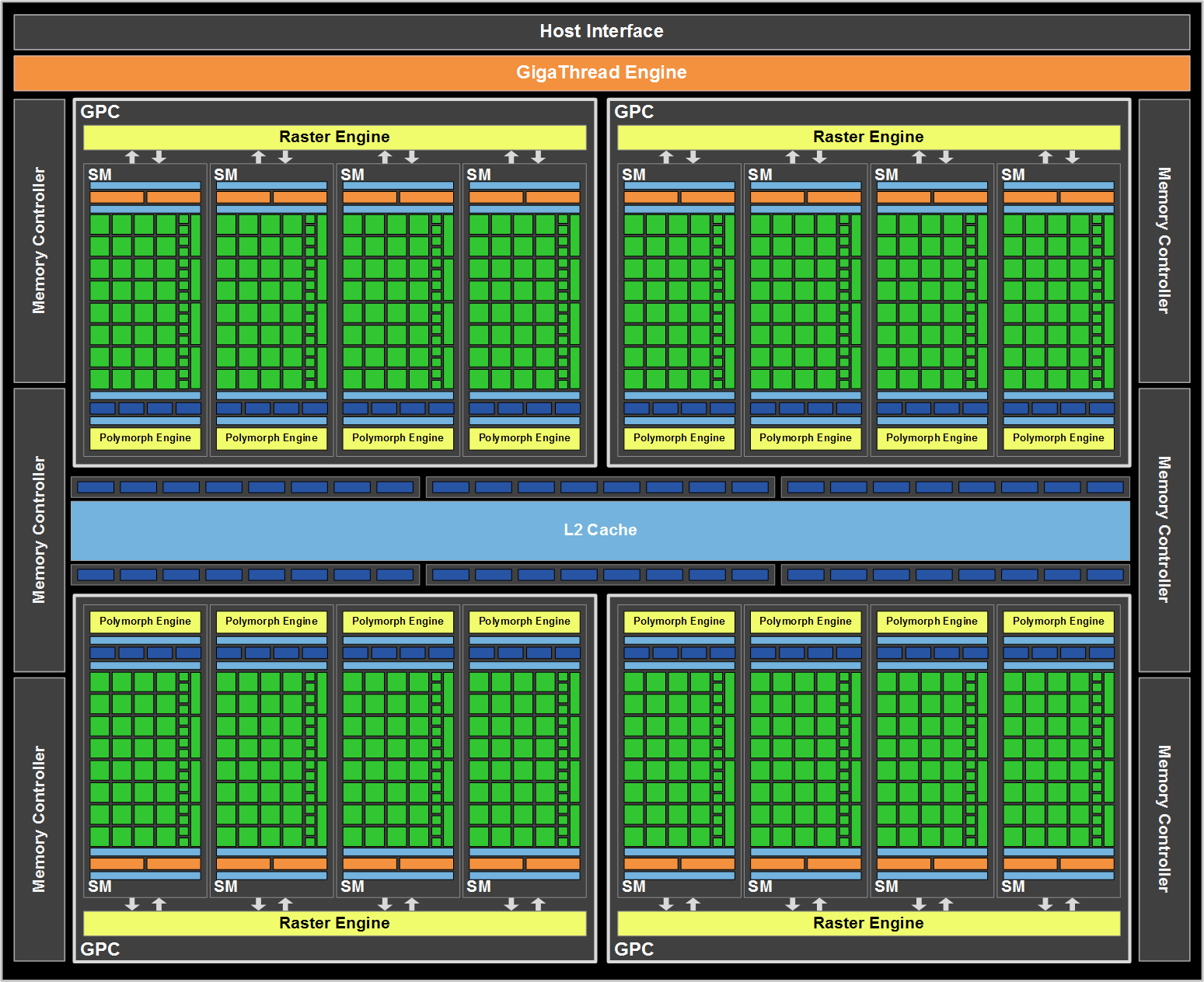
Fundamentally GF110 is the same architecture as GF100, especially when it comes to compute. 512 CUDA Cores are divided up among 4 GPCs, and in turn each GPC contains 1 raster engine and 4 SMs. At the SM level each SM contains 32 CUDA cores, 16 load/store units, 4 special function units, 4 texture units, 2 warp schedulers with 1 dispatch unit each, 1 Polymorph unit (containing NVIDIA’s tessellator) and then the 48KB+16KB L1 cache, registers, and other glue that brought an SM together. At this level NVIDIA relies on TLP to keep a GF110 SM occupied with work. Attached to this are the ROPs and L2 cache, with 768KB of L2 cache serving as the guardian between the SMs and the 6 64bit memory controllers. Ultimately GF110’s compute performance per clock remains unchanged from GF100 – at least if we had a GF100 part with all of its SMs enabled.
On the graphics side however, NVIDIA has been hard at work. They did not port over GF104’s shader design, but they did port over GF104’s texture hardware. Previously with GF100, each unit could compute 1 texture address and fetch 4 32bit/INT8 texture samples per clock, 2 64bit/FP16 texture samples per clock, or 1 128bit/FP32 texture sample per clock. GF104’s texture units improved this to 4 samples/clock for 32bit and 64bit, and it’s these texture units that have been brought over for GF110. GF110 can now do 64bit/FP16 filtering at full speed versus half-speed on GF100, and this is the first of the two major steps NVIDIA took to increase GF110’s performance over GF100’s performance on a clock-for-clock basis.
| NVIDIA Texture Filtering Speed (Per Texture Unit) | |||||
| GF110 | GF104 | GF100 | |||
| 32bit (INT8) | 4 Texels/Clock | 4 Texels/Clock | 4 Texels/Clock | ||
| 64bit (FP16) | 4 Texels/Clock | 4 Texels/Clock | 2 Texels/Clock | ||
| 128bit (FP32) | 1 Texel/Clock | 1 Texel/Clock | 1 Texel/Clock | ||
Like most optimizations, the impact of this one is going to be felt more on newer games than older games. Games that make heavy use of 64bit/FP16 texturing stand to gain the most, while older games that rarely (if at all) used 64bit texturing will gain the least. Also note that while 64bit/FP16 texturing has been sped up, 64bit/FP16 rendering has not – the ROPs still need 2 cycles to digest 64bit/FP16 pixels, and 4 cycles to digest 128bit/FP32 pixels.
It’s also worth noting that this means that NVIDIA’s texture:compute ratio schism remains. Compared to GF100, GF104 doubled up on texture units while only increasing the shader count by 50%; the final result was that per SM 32 texels were processed to 96 instructions computed (seeing as how the shader clock is 2x the base clock), giving us 1:3 ratio. GF100 and GF110 on the other hand retain the 1:4 (16:64) ratio. Ultimately at equal clocks GF104 and GF110 widely differ in shading, but with 64 texture units total in both designs, both have equal texturing performance.
Moving on, GF110’s second trick is brand-new to GF110, and it goes hand-in-hand with NVIDIA’s focus on tessellation: improved Z-culling. As a quick refresher, Z-culling is a method of improving GPU performance by throwing out pixels that will never be seen early in the rendering process. By comparing the depth and transparency of a new pixel to existing pixels in the Z-buffer, it’s possible to determine whether that pixel will be seen or not; pixels that fall behind other opaque objects are discarded rather than rendered any further, saving on compute and memory resources. GPUs have had this feature for ages, and after a spurt of development early last decade under branded names such as HyperZ (AMD) and Lightspeed Memory Architecture (NVIDIA), Z-culling hasn’t been promoted in great detail since then.

Z-Culling In Action: Not Rendering What You Can't See
For GF110 this is changing somewhat as Z-culling is once again being brought back to the surface, although not with the zeal of past efforts. NVIDIA has improved the efficiency of the Z-cull units in their raster engine, allowing them to retire additional pixels that were not caught in the previous iteration of their Z-cull unit. Without getting too deep into details, internal rasterizing and Z-culling take place in groups of pixels called tiles; we don’t believe NVIDIA has reduced the size of their tiles (which Beyond3D estimates at 4x2); instead we believe NVIDIA has done something to better reject individual pixels within a tile. NVIDIA hasn’t come forth with too many details beyond the fact that their new Z-cull unit supports “finer resolution occluder tracking”, so this will have to remain a mystery for another day.
In any case, the importance of this improvement is that it’s particularly weighted towards small triangles, which are fairly rare in traditional rendering setups but can be extremely common with heavily tessellated images. Or in other words, improving their Z-cull unit primarily serves to improve their tessellation performance by allowing NVIDIA to better reject pixels on small triangles. This should offer some benefit even in games with fewer, larger triangles, but as framed by NVIDIA the benefit is likely less pronounced.
In the end these are probably the most aggressive changes NVIDIA could make in such a short period of time. Considering the GF110 project really only kicked off in earnest in February, NVIDIA only had around half a year to tinker with the design before it had to be taped out. As GPUs get larger and more complex, the amount of tweaking that can get done inside such a short window is going to continue to shrink – and this is a far cry from the days where we used to get major GPU refreshes inside of a year.








160 Comments
View All Comments
chizow - Tuesday, November 9, 2010 - link
There's 2 ways they can go with the GTX 570, either more disabled SM than just 1 (2-3) and similar clockspeed to the GTX 580, or fewer disabled SM but much lower clockspeed. Both would help to reduce TDP but with more disabled SM that would also help Nvidia unload the rest of their chip yield. I have a feeling they'll disable 2-3 SM with higher clocks similar to the 580 so that the 470 is still slightly slower than the 480.I'm thinking along the same lines as you though for the GTX 560, it'll most likely be the full-fledged GF104 we've been waiting for with all 384SP enabled, probably slightly higher clockspeeds and not much more than that, but definitely a faster card than the original GF104.
vectorm12 - Tuesday, November 9, 2010 - link
I'd really love to see the raw crunching power of the 480/580 vs. 5870/6870.I've found ighashgpu to be a great too to determine that and it can be found at http://www.golubev.com/
Please consider it for future tests as it's very well optimized for both CUDA and Stream
spigzone - Tuesday, November 9, 2010 - link
The performance advantage of a single GPU vs CF or SLI is steadily diminishing and approaching a point of near irrelevancy.6870 CF beats out the 580 in nearly every parameter, often substantially on performance benchmarks, and per current newegg prices, comes in at $80 cheaper.
But I think the real sweet spot would be a 6850 CF setup with AMD Overdrive applied 850Mz clocks, which any 6850 can achieve at stock voltages with minimal thermal/power/noise costs (and minimal 'tinkering'), and from the few 6850 CF benchmarks that showed up would match or even beat the GTX580 on most game benchmarks and come in at $200 CHEAPER.
That's an elbow from the sky in my book.
smookyolo - Tuesday, November 9, 2010 - link
You seem to be forgetting the minimum framerates... those are so much more important than average/maximum.Sihastru - Tuesday, November 9, 2010 - link
Agreed, CF scales very badly when it comes to minumum framerates. It is even below the minimum framerates of one of the cards in the CF setup. It is very anoying when you're doing 120FPS in a game and from time to time your framerates drop to an unplayable and very noticable 20FPS.chizow - Tuesday, November 9, 2010 - link
Nice job on the review as usual Ryan,Would've liked to have seen some expanded results however, but somewhat understandable given your limited access to hardware atm. It sounds like you plan on having some SLI results soon.
I would've really liked to have seen clock-for-clock comparisons though to the original GTX 480 though to isolate the impact of the refinements between GF100 and GF110. To be honest, taking away the ~10% difference in clockspeeds, what we're left with seems to be ~6-10% from those missing 6% functional units (32 SM and 4 TMUs).
I would've also liked to have seen some preliminary overclocking results with the GF110 to see how much the chip revision and cooling refinements increased clockspeed overhead, if at all. Contrary to somewhat popular belief, the GTX 480 did overclock quite well, and while that also increased heat and noise it'll be hard for someone with an overclocked 480 to trade it in for a 580 if it doesn't clock much better than the 480.
I know you typically have follow-up articles once the board partners send you more samples, so hopefully you consider these aspects in your next review, thanks!
PS: On page 4, I believe this should be a supposed GTX 570 mentioned in this excerpt and not GTX 470: "At 244W TDP the card draws too much for 6+6, but you can count on an eventual GTX 470 to fill that niche."
mapesdhs - Tuesday, November 9, 2010 - link
"I would've also liked to have seen some preliminary overclocking results ..."
Though obviously not a true oc'ing revelation, I note with interest there's already
a factory oc'd 580 listed on seller sites (Palit Sonic), with an 835 core and 1670
shader. The pricing is peculiar though, with one site pricing it the same as most
reference cards, another site pricing it 30 UKP higher. Of course though, none
of them show it as being in stock yet. :D
Anyway, thanks for the writeup! At least the competition for the consumer finally
looks to be entering a more sensible phase, though it's a shame the naming
schemes are probably going to fool some buyers.
Ian.
Ryan Smith - Wednesday, November 10, 2010 - link
You're going to have to wait until I have some more cards for some meaningful overclocking results. However clock-for-clock comparisons I can do.http://www.anandtech.com/show/4012/nvidias-geforce...
JimmiG - Tuesday, November 9, 2010 - link
Well technically, this is not a 512-SP card at 772 MHz. This is because if you ever find a way to put all 512 processors at 100% load, the throttling mechanism will kick in.That's like saying you managed to overclock your CPU to 4.7 GHz.. sure, it might POST, but as soon as you try to *do* anything, it instantly crashes.
Ryan Smith - Tuesday, November 9, 2010 - link
Based on the performance of a number of games and compute applications, I am confident that power throttling is not kicking in for anything besides FurMark and OCCT.