ZFS - Building, Testing, and Benchmarking
by Matt Breitbach on October 5, 2010 4:33 PM EST- Posted in
- IT Computing
- Linux
- NAS
- Nexenta
- ZFS
ZFS Features
ZFS includes two exciting features that dramatically improve the performance of read operations. I’m talking about ARC and L2ARC. ARC stands for adaptive replacement cache. ARC is a very fast block level cache located in the server’s memory (RAM). The amount of ARC available in a server is usually all of the memory except for 1GB.
For example, our ZFS server with 12GB of RAM has 11GB dedicated to ARC, which means our ZFS server will be able to cache 11GB of the most accessed data. Any read requests for data in the cache can be served directly from the ARC memory cache instead of hitting the much slower hard drives. This creates a noticeable performance boost for data that is accessed frequently.
As a general rule, you want to install as much RAM into the server as you can to make the ARC as big as possible. At some point adding more memory becomes cost prohibitive, which is where the L2ARC becomes important. The L2ARC is the second level adaptive replacement cache. The L2ARC is often called “cache drives” in the ZFS systems.
These cache drives are physically MLC style SSD drives. These SSD drives are slower than system memory, but still much faster than hard drives. More importantly, the SSD drives are much cheaper than system memory. Most people compare the price of SSD drives with the price of hard drives, and this makes SSD drives seem expensive. Compared to system memory, MLC SSD drives are actually very inexpensive.
When cache drives are present in the ZFS pool, the cache drives will cache frequently accessed data that did not fit in ARC. When read requests come into the system, ZFS will attempt to serve those requests from the ARC. If the data is not in the ARC, ZFS will attempt to serve the requests from the L2ARC. Hard drives are only accessed when data does not exist in either the ARC or L2ARC. This means the hard drives receive far fewer requests, which is awesome given the fact that the hard drives are easily the slowest devices in the overall storage solution.
In our ZFS project, we added a pair of 160GB Intel X25-M MLC SSD drives for a total of 320GB of L2ARC. Between our ARC of 11GB and our L2ARC of 320GB, our ZFS solution can cache over 300GB of the most frequently accessed data! This hybrid solution offers considerably better performance for read requests because it reduces the number of accesses to the large, slow hard drives.
Things to Keep in Mind
There are a few things to remember. The cache drives don’t get mirrored. When you add cache drives, you cannot set them up as mirrored, but there is no need to since the content is already mirrored on the hard drives. The cache drives are just a cheap alternative to RAM for caching frequently access content.
Another thing to remember is you still need to use SLC SSD drives for the ZIL drives. ZIL stands for "ZFS Intent Log", and acts as an intermediary for write caching. Not having ZIL drives severely slows down write access. By adding the ZIL drives you significantly increase write speeds. This is still not as fast as a RAM based write cache on a RAID card, but it is much better than not having anything. Solaris ZFS Best Practices For Log Devices The SLC SSD drives used for ZIL drives dramatically improve the performance of write actions. The MLC SSD drives used as cache drives are used to improve read performance.
It is also important to remember that the L2ARC will require some memory to operate. A portion of the ARC will be used to index and manage the content located in the L2ARC. A general rule of thumb is that 1-2GB of ARC will be used for every 100GB of L2ARC. With a 300GB L2ARC, we will give up 3-6GB of ARC. This will leave us with 5-8GB of ARC memory to use to cache the most frequently accessed files.
Effective Caching to Virtualized Environments
At this point, you are probably wondering how effectively the two levels of caching will be able to cache the most frequently used data, especially when we are talking about 9TB of formatted RAID10 capacity. Will 11GB of ARC and 320GB L2ARC make a significant difference for overall performance? It will depend on what type of data is located on the storage array and how it is being accessed. If it contained 9TB of files that were all accessed in a completely random way, the caching would likely not be effective. However, we are planning to use the storage for virtual machine file systems and this will cache very effectively for our intended purpose.
When you plan to deploy hundreds of virtual machines, the first step is to build a base template that all of the virtual machines will start from. If you were planning to host a lot of Linux virtual machines, you would build the base template by installing Linux. When you get to the step where you would normally configure the server, you would shut off the virtual machine. At that point, you would have the base template ready. Each additional virtual machine would simply be chained off the base template. The virtualization technology will keep the changes specific to each virtual machine in its own child or differencing file.
When the virtualization solution is configured this way, the base template will be cached quite effectively in the ARC (main system memory). This means the main operating system files and cPanel files should deliver near RAM-disk performance levels. The L2ARC will be able to effectively cache the most frequently used content that is not shared by all of the virtual machines, such as the content of the files and folders in the most popular websites or MySQL databases. The least frequently accessed content will be pulled from the hard drives, but even that should show solid performance since it will be RAID10 across 18 drives and none of the frequently accessed read requests will need to burden the RAID10 volume since they are already served from ARC or L2ARC.
Testing the L2ARC
We thought it would be fun to actually test the L2ARC and build a chart of the performance as a function of time. To test and graph usefulness of L2ARC, we set up an iSCSI share on the ZFS server and then ran Iometer from our test blade in our blade center. We ran these tests over gigabit Ethernet.
Iometer Test Details:
25GB working set
4k blocks
100% random
100% read
load 32 (constant)
four hour test
Every ten minutes during the test, we grabbed the “Last performance” values (IOPS, MB/sec) from Iometer and wrote them down to build a performance chart. Our goal was to be able to graph the performance as a function of time so we could illustrate the usefulness of the L2ARC.
We ran the same test using the Promise M610i (16 1TB WD RE3 drives in RAID10) box to get a comparison graph. The Promise box is not a ZFS style solution and does not have any L2ARC style caching feature. We expected the ZFS box to outperform the Promise box, and we expected the ZFS box to increase performance as a function of time because the L2ARC would become more populated the longer the test ran.
The Promise box consistently delivered 2200 to 2300 IOPS every time we checked performance during the entire 4 hour test. The ZFS box started by delivering 2532 IOPS at 10 minutes into the test and delivered 20873 IOPS by the end of the test.
Here is the chart of the ZFS box performance results:
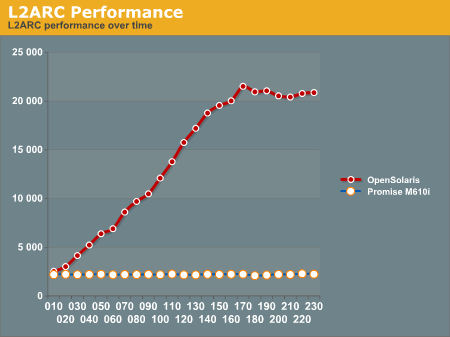
Initially, the two SAN boxes deliver similar performance, with the Promise box at 2200 IOPS and the ZFS box at 2500 IOPS. The ZFS box with a L2ARC is able to magnify its performance by a factor of ten once the L2ARC is completely populated!
Notice that ZFS limits how quickly the L2ARC is populated to reduce wear on the cache drives. It takes a few hours to populate the L2ARC and achieve maximum performance. That seems like a long time when running benchmarks, but it is actually a very short period of time in the life cycle of a typical SAN box.








102 Comments
View All Comments
Exelius - Wednesday, October 6, 2010 - link
I think you identified the strong issue between SATA and SAS drives, but there's no real reason you can't do both: in fact, this is common practice. I don't know what the distribution for AT is so I may be wrong, but often a relatively small amount of your data is accountable for a large portion of your random writes. Why not store that data permanently on the SSDs?For everything else, the cost per gb difference between SATA and SAS is too much to ignore. Once you start talking about adding SAS drives to this, you're moving out of the same class as the Promise device. I've used the Promise vTrak M series (and actually, the M610i specifically) and it's about the cheapest iSCSI SAN device you can get while still being a "real" iSCSI device. It's also about at least a 5 year old product and is growing long in the tooth; I don't know that it's appropriate to compare it with a brand new, performance tuned monster.
But once you introduce SAS into the equation, the chassis itself becomes a much smaller percentage of cost. You go from $140 a drive to close to $400. You also start competing with EqualLogic, HP, etc. and given the need you expressed to add more RAM and CPU, there's definitely some stiff competition from higher-end, more modern products than the M610i.
I guess at the end of the day, while the performance numbers are impressive compared to the M610i, I don't know that the M610i is the device I would use if I was interested in performance. The Promise M610i's strength is price and capacity. Given that the M610i is INFINITELY easier to set up and maintain, that has to factor in to the cost as well. The M610i is often used as a staging target for disk-disk-tape backups; it actually has some throughput issues in a number of scenarios so it's not appropriate for all situations. It just depends on where your needs and bottlenecks are.
I'd rather have seen a comparison with a device such as an EqualLogic or StorageWorks array; because once you upgrade the ZFS box, add labor and support costs into the equation, they do become more appealing in the $10k range (and the fact that you can rather easily add more spindles to an existing array.)
Mattbreitbach - Wednesday, October 6, 2010 - link
You make some strong points.1 - our storage system is not used at Anandtech in any way - I am involved in an entirely separate entity who's only affiliation with Anandtech is that we've written an article reviewing our hardware in our environment. As such, I have no idea what Anandtech's storage needs look like. In our environment we use fixed size VHD's for our VM storage currently. As such there is no real way to put small writes on SSD's and static content on slower spindles. We need to maintain performance across the entire data set.
2 - The Vtrak M610i is about 3 years old from what I can gather from their press releases. We purchased our first Vtrak M610i at about that time. http://www.promise.com/news_room/news.aspx?m=615&a...
While it may be getting a bit older, it is still available for purchase, and is still a relatively inexpensive way to build a high-capacity SAN device. The reason that it was compared in this article is because that is what we are currently using and replacing. While the controller and chassis is different from our ZFS monster, the drives in the chassis are identical, and the price points are very similar.
3 - We would have loved to compare it to a current generation Equalogic unit, but we did not have one on hand to test. If we ever happen to get one we will definately run the numbers against it.
4 - The Promise system has a lot going for it in the ease of setup and use department, and I am currently working on an article that goes in depth on that. Promise also has several new products available that lower the price point (VessRAID) and expand the options that you have available. I hope to get one of those units to test and possibly deploy in the near future also. They also have an enterprise-grade head end (Vtrak S3000) that looks promising also.
Overall, this article was mainly about the ZFS system, what is possible, and how it performed against our current infrastructure. I am hopeful that we can expand what we have on hand to test with and provide broader comparisons in the future, but there is only so far a budget will stretch for getting hardware to simply test.
Exelius - Thursday, October 7, 2010 - link
I know it's at least 4 years old -- I purchased one at least that long ago. But point taken; I haven't kept up with Promise beyond the vTrak M after getting a budget to higher-end units (I still used the vTrak Ms for cheap storage.)And if your data set is large enough to require this many spindles, you might benefit from optimizing it a bit on the front-end... for example, build your VMs to split the VHDs so the high-write data is stored elsewhere. No idea if this would be of benefit for your environment (that's what test labs are for) but it's a strategy most shops with high-volume, high-transaction datasets have to periodically look at as the performance gulf between big, cheap drives and small, fast ones keeps increasing.
Given the size of your environment, EqualLogic or StorageWorks would probably be willing to let you use a demo unit for a little while. Don't know that they wouldn't make you sign an NDA regarding the benchmarks, but you'd at least be able to do it internally... Plus, IMO, there's a massive benefit to having an enterprise support contract when you have a controller failure (which I'm actually surprised hasn't been an issue with the single controller design of the Promise M610)
All told; still a good article -- you generally don't see stuff this thorough posted on the Internet. There are just so many possibilities in this space that it's hard not to nitpick. :)
JonBendtsen - Thursday, October 7, 2010 - link
I think it could be interesting to see performance benchmarks without the L2ARC to see how much value it really has.binarycrusader - Thursday, October 7, 2010 - link
Management of the drive LEDs for faulty drives, etc. is available with the right hardware; it's unfortunate that's it's not well supported on a wide variety of systems, but it does exist.As for SMTP notification (and other kinds) of faulty hardware, etc. that should be available depending on the build of OpenSolaris you're using and whether fault management aware drivers are available for your hardware. See 'man fmadm', 'man fmd' and 'man smtp-notify' for more information.
Ultimately, users looking for a polished storage system with graphical management tools, etc. are encouraged to look at Oracle's Sun Open Storage servers which address many of the complaints listed in the article. Yes, I'm aware you're trying to build your own systems here, but it should be obvious why all of the nice tools aren't given away for free.
pburdine - Friday, October 8, 2010 - link
I haven't installed OpenSolaris yet, but when I am using Solaris 10 with ZFS, it does come with a website manager to manage may of the Sun/Oracle Applications. Did you try https://localhost:6789?murdmath - Friday, October 8, 2010 - link
Great Article. Very informative. I am excited for you review of the Promise M610i SAN.Mat
Brutalizer - Monday, October 11, 2010 - link
First of all, there is only ONE single reason to use ZFS: it protects your data whereas other storage solutions might corrupt your data (including enterprise storage solutions)!See here how common file systems such as Ext3, JFS, XFS, ReiserFS, NTFS, etc might corrupt your data:
http://www.zdnet.com/blog/storage/how-microsoft-pu...
All the rest of the ZFS features such as snapshots, easy administration, etc are just icing on the cake. If ZFS had only protection of data and no other features, I would still use ZFS..
See here how Raid-5 does not protect your data. In fact, Raid-6 is not better and also may corrupt your precious data. Google "data corruption raid-6"
http://www.baarf.com/
See here how ZFS does protect your data:
http://www.zdnet.com/blog/storage/zfs-data-integri...
http://queue.acm.org/detail.cfm?id=1317400
There is a reason ZFS eats CPU (does checksumming and protects your data), whereas all the other filesystems does not protect your data (rudimentary checksumming).
ZFS has end-to-end checksumming! That means, ZFS will compare the data in RAM with the data on disk - are they equal? All other storage solutions does not do that - they only check data within a realm. But when data passes a realm it may corrupt (RAM down to disk controller down to disk). There may be bugs in hardware or software within a realm. And data are never compared "the data XYZ in RAM, is it still XYZ on disk?" - this check are never ever made (unless you use ZFS).
Regarding dedup. If you get slow performance of dedup, it is only because dedup requires huge amounts of RAM. You need something like 2GB RAM for each TB disk. If you have less RAM, dedup will be sloooow. If you have much RAM, dedup will be fast.
Another advantage of ZFS (there are many) is that ZFS is OS agnostic! You can insert your zfs raid into another OS or computer without any problems! Try that with a hardware raid - impossible.
Another advantage of ZFS is there are no "fsck"! Instead you do "zfs scrub" every week, while your raid is alive and running. fsck requires you to shutdown the raid to validate it.
Hardware raid is just a cpu with some software running on it. It is better to move that software to the CPU where you have many cores and GB of RAM and you can easily patch it. In the future, hardware raid will die. Software raid like ZFS will rule.
Regarding BTRFS, if you read the mail lists, you see that people loose data all the time with BTRFS. In the future it might be good, but it will take at least another 5 years until we reach that stage. Then ZFS have developed even further.
solori - Friday, October 22, 2010 - link
Regarding ZFS and ubiquity: ZFS is only version compatible. As ZFS' capabilities are updated, the blanket statement that "any ZFS-speaking OS can mount a ZFS volume" just isn't going to ring true. In fact, many distributions porting ZFS are still behind in ZFS version.As in most "backward compatible" entities, newer versions of ZFS will almost always be compatible with older versions, but the older version will not be able to mount a more recent version. Therefore, you could have a Mac port that can't read a BSD port for instance.
Also, since ZFS is modular, one OS vendor could included a "highly proprietary" inline encryption or compression algorithm that is not (or not strictly) open in nature. This leads to subsequent OS-based divergence if they fail to include the necessary libraries that are not a part of ZFS itself.
However, and for the most part, ZFS should be regarded as version compatible regardless of the OS. Another great reason to use JBOD or discrete disk setups: complete portability of storage pools.
Hrel - Monday, October 11, 2010 - link
Why is ZFS not the only file system in use today? I completely forgot about this until this article. I remember first reading about it and thinking "this'll probably be in everything in a couple years" so I put it out of my mind. I am upset this is not the file system everything uses.