ZFS - Building, Testing, and Benchmarking
by Matt Breitbach on October 5, 2010 4:33 PM EST- Posted in
- IT Computing
- Linux
- NAS
- Nexenta
- ZFS
ZFS Features
ZFS includes two exciting features that dramatically improve the performance of read operations. I’m talking about ARC and L2ARC. ARC stands for adaptive replacement cache. ARC is a very fast block level cache located in the server’s memory (RAM). The amount of ARC available in a server is usually all of the memory except for 1GB.
For example, our ZFS server with 12GB of RAM has 11GB dedicated to ARC, which means our ZFS server will be able to cache 11GB of the most accessed data. Any read requests for data in the cache can be served directly from the ARC memory cache instead of hitting the much slower hard drives. This creates a noticeable performance boost for data that is accessed frequently.
As a general rule, you want to install as much RAM into the server as you can to make the ARC as big as possible. At some point adding more memory becomes cost prohibitive, which is where the L2ARC becomes important. The L2ARC is the second level adaptive replacement cache. The L2ARC is often called “cache drives” in the ZFS systems.
These cache drives are physically MLC style SSD drives. These SSD drives are slower than system memory, but still much faster than hard drives. More importantly, the SSD drives are much cheaper than system memory. Most people compare the price of SSD drives with the price of hard drives, and this makes SSD drives seem expensive. Compared to system memory, MLC SSD drives are actually very inexpensive.
When cache drives are present in the ZFS pool, the cache drives will cache frequently accessed data that did not fit in ARC. When read requests come into the system, ZFS will attempt to serve those requests from the ARC. If the data is not in the ARC, ZFS will attempt to serve the requests from the L2ARC. Hard drives are only accessed when data does not exist in either the ARC or L2ARC. This means the hard drives receive far fewer requests, which is awesome given the fact that the hard drives are easily the slowest devices in the overall storage solution.
In our ZFS project, we added a pair of 160GB Intel X25-M MLC SSD drives for a total of 320GB of L2ARC. Between our ARC of 11GB and our L2ARC of 320GB, our ZFS solution can cache over 300GB of the most frequently accessed data! This hybrid solution offers considerably better performance for read requests because it reduces the number of accesses to the large, slow hard drives.
Things to Keep in Mind
There are a few things to remember. The cache drives don’t get mirrored. When you add cache drives, you cannot set them up as mirrored, but there is no need to since the content is already mirrored on the hard drives. The cache drives are just a cheap alternative to RAM for caching frequently access content.
Another thing to remember is you still need to use SLC SSD drives for the ZIL drives. ZIL stands for "ZFS Intent Log", and acts as an intermediary for write caching. Not having ZIL drives severely slows down write access. By adding the ZIL drives you significantly increase write speeds. This is still not as fast as a RAM based write cache on a RAID card, but it is much better than not having anything. Solaris ZFS Best Practices For Log Devices The SLC SSD drives used for ZIL drives dramatically improve the performance of write actions. The MLC SSD drives used as cache drives are used to improve read performance.
It is also important to remember that the L2ARC will require some memory to operate. A portion of the ARC will be used to index and manage the content located in the L2ARC. A general rule of thumb is that 1-2GB of ARC will be used for every 100GB of L2ARC. With a 300GB L2ARC, we will give up 3-6GB of ARC. This will leave us with 5-8GB of ARC memory to use to cache the most frequently accessed files.
Effective Caching to Virtualized Environments
At this point, you are probably wondering how effectively the two levels of caching will be able to cache the most frequently used data, especially when we are talking about 9TB of formatted RAID10 capacity. Will 11GB of ARC and 320GB L2ARC make a significant difference for overall performance? It will depend on what type of data is located on the storage array and how it is being accessed. If it contained 9TB of files that were all accessed in a completely random way, the caching would likely not be effective. However, we are planning to use the storage for virtual machine file systems and this will cache very effectively for our intended purpose.
When you plan to deploy hundreds of virtual machines, the first step is to build a base template that all of the virtual machines will start from. If you were planning to host a lot of Linux virtual machines, you would build the base template by installing Linux. When you get to the step where you would normally configure the server, you would shut off the virtual machine. At that point, you would have the base template ready. Each additional virtual machine would simply be chained off the base template. The virtualization technology will keep the changes specific to each virtual machine in its own child or differencing file.
When the virtualization solution is configured this way, the base template will be cached quite effectively in the ARC (main system memory). This means the main operating system files and cPanel files should deliver near RAM-disk performance levels. The L2ARC will be able to effectively cache the most frequently used content that is not shared by all of the virtual machines, such as the content of the files and folders in the most popular websites or MySQL databases. The least frequently accessed content will be pulled from the hard drives, but even that should show solid performance since it will be RAID10 across 18 drives and none of the frequently accessed read requests will need to burden the RAID10 volume since they are already served from ARC or L2ARC.
Testing the L2ARC
We thought it would be fun to actually test the L2ARC and build a chart of the performance as a function of time. To test and graph usefulness of L2ARC, we set up an iSCSI share on the ZFS server and then ran Iometer from our test blade in our blade center. We ran these tests over gigabit Ethernet.
Iometer Test Details:
25GB working set
4k blocks
100% random
100% read
load 32 (constant)
four hour test
Every ten minutes during the test, we grabbed the “Last performance” values (IOPS, MB/sec) from Iometer and wrote them down to build a performance chart. Our goal was to be able to graph the performance as a function of time so we could illustrate the usefulness of the L2ARC.
We ran the same test using the Promise M610i (16 1TB WD RE3 drives in RAID10) box to get a comparison graph. The Promise box is not a ZFS style solution and does not have any L2ARC style caching feature. We expected the ZFS box to outperform the Promise box, and we expected the ZFS box to increase performance as a function of time because the L2ARC would become more populated the longer the test ran.
The Promise box consistently delivered 2200 to 2300 IOPS every time we checked performance during the entire 4 hour test. The ZFS box started by delivering 2532 IOPS at 10 minutes into the test and delivered 20873 IOPS by the end of the test.
Here is the chart of the ZFS box performance results:
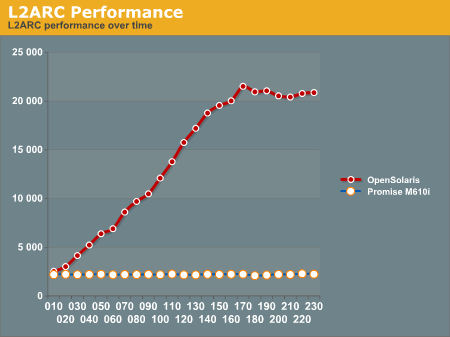
Initially, the two SAN boxes deliver similar performance, with the Promise box at 2200 IOPS and the ZFS box at 2500 IOPS. The ZFS box with a L2ARC is able to magnify its performance by a factor of ten once the L2ARC is completely populated!
Notice that ZFS limits how quickly the L2ARC is populated to reduce wear on the cache drives. It takes a few hours to populate the L2ARC and achieve maximum performance. That seems like a long time when running benchmarks, but it is actually a very short period of time in the life cycle of a typical SAN box.








102 Comments
View All Comments
MGSsancho - Tuesday, October 5, 2010 - link
I haven't tried this myself yet but how about using 8kb blocks and using jumbo frames on your network? possibly lower through padding to fill the 9mb packet in exchange for lower latency? I have no idea as this is just a theory. dudes in the #opensolaris irc chan have always recommended 128K or 64K depending on the data.solori - Wednesday, October 20, 2010 - link
One easy way to check this would be to export the pool from OpenSolaris and directly import it to NexentaStor and re-test. I think you'll find that the differences - as your benchmarks describe - are more linked to write caching at the disk level than partition alignment.NexentaStor is focused on data integrity, and tunes for that very conservatively. Since SATA disks are used in your system, NexentaStor will typically disable disk write cache (write hit) and OpenSolaris may typically disable device cache flush operations (write benefit). These two feature differences can provide the benchmark differences you're seeing.
Also, some "workstation" tuning includes the disabling of ZIL (performance benefit). This is possible - but not recommended - in NexentaStor but has the side effect of risking application data integrity. Disabling the ZIL (in the absence of SLOG) will result in synchronous writes being committed only with transaction group commits - similar performance to having a very fast SLOG (lots of ARC space helpful too).
fmatthew5876 - Tuesday, October 5, 2010 - link
I'd be very interested to see how FreeBSD ZFS benchmark results would compare to Nexenta and Open Solaris.mbreitba - Tuesday, October 5, 2010 - link
We have benchmarked FreeNAS's implimentation of ZFS on the same hardware, and the performance was abysmal. We've considered looking into the latest releases of FreeBSD but have not completed any of that testing yet.jms703 - Tuesday, October 5, 2010 - link
Have you benchmarked FreeBSD 8.1? There were a huge number of performance fixes in 8.1.Also, when was this article written? OpenSolaris was killed by Sun on August 13th, 2010.
mbreitba - Tuesday, October 5, 2010 - link
There was a lot of work on this article just prior to the official announcement. The development of the Illumos foundation and subsequent OpenIndiana has been so rapidly paced that we wanted to get this article out the door before diving in to OpenIndiana and any other OpenSolaris derivatives. We will probably add more content talking about the demise of OpenSolaris and the Open Source alternatives that have started popping up at a later date.MGSsancho - Tuesday, October 5, 2010 - link
Not to mention that projects like illumos are currently not recommended for production, Currently only meant as a base for other distros (OpenIndiana.) Then there is Solaris 11 due soon. I'll try out the express version when its released.cdillon - Tuesday, October 5, 2010 - link
FreeNAS 0.7.x is still using FreeBSD 7.x, and the ZFS code is a bit dated. FreeBSD 8.x has newer ZFS code (v15). Hopefully very soon FreeBSD 9.x will have the latest ZFS code (v24).piroroadkill - Tuesday, October 5, 2010 - link
This is relevant to my interests, and I've been toying with the idea of setting up a ZFS based server for a while.It's nice to see the features it can use when you have the hardware for it.
cgaspar - Tuesday, October 5, 2010 - link
You say that all writes go to a log in ZFS. That's just not true. Only synchronous writes below a certain size go into the log (either built into the pool, or a dedicated log device). All writes are held in memory in a transaction group, and that transaction group is written to the main pool at least every 10 seconds by default (in OpenSolaris - it used to be 30 seconds, and still is in Solaris 10 U9). That's tunable, and commits will happen more frequently if required, based on available ARC and data churn rate. Note that _all_ writes go into the transaction group - the log is only ever used if the box crashes after a synchronous write and before the txg commits.Now for the caution - you have chosen SSDs for your SLOG that don't have a backup power source for their on board caches. If you suffer power loss, you may lose data. Several SLC SSDs have recently been released that have a supercapacitor or other power source sufficient to write cache data to flash on power loss, but the current Intel like up doesn't have it. I believe the next generation Intel SSDs will.