NVIDIA Announces Parallel Nsight 1.5 & CUDA Toolkit 3.2
by Ryan Smith on September 14, 2010 9:00 AM ESTNot to be outdone by Intel’s IDF and AMD’s counter-meeting this week, NVIDIA’s GPU Computing group has their own announcement this week ahead of their GPU Technology Conference next week.
Next week NVIDIA will be releasing the first major update to their GPGPU programming toolchain since the Fermi-based Tesla series launched earlier this year. Specifically, they will be releasing Parallel Nsight 1.5, and version 3.2 of the CUDA Toolkit.
Parallel Nsight 1.5
As we’ve reiterated a number of times now, NVIDIA’s long-term goals require the company to expand their GPU market beyond video cards and in to the High Performance Computing (HPC) space, where the brute force applied by GPUs for gaming purposes can be applied to academic, industrial, and even consumer computing applications. The Fermi architecture was a big step towards this goal, providing a GPU much better suited for GPU computing than the previous GT200/G80 thanks in large part to the GPU’s unified address space, ECC support, and support for C++. With the Fermi architecture NVIDIA would have the hardware necessary to take the next step in to GPU computing.
However good hardware requires good software, and that’s where our discussion is going today. With support for higher level languages comes the need for better programming tools and better debugging tools. Furthermore NVIDIA ultimately wants to extend practical GPU programming to the more rank & file programmers, where Microsoft’s Visual Studio is by far and wide the IDE of choice for C and C++. Reaching these programmers would require extending CUDA programming to the IDE and toolsets they already use, and in the process expand the market by making development more accessible than it was with older toolsets.
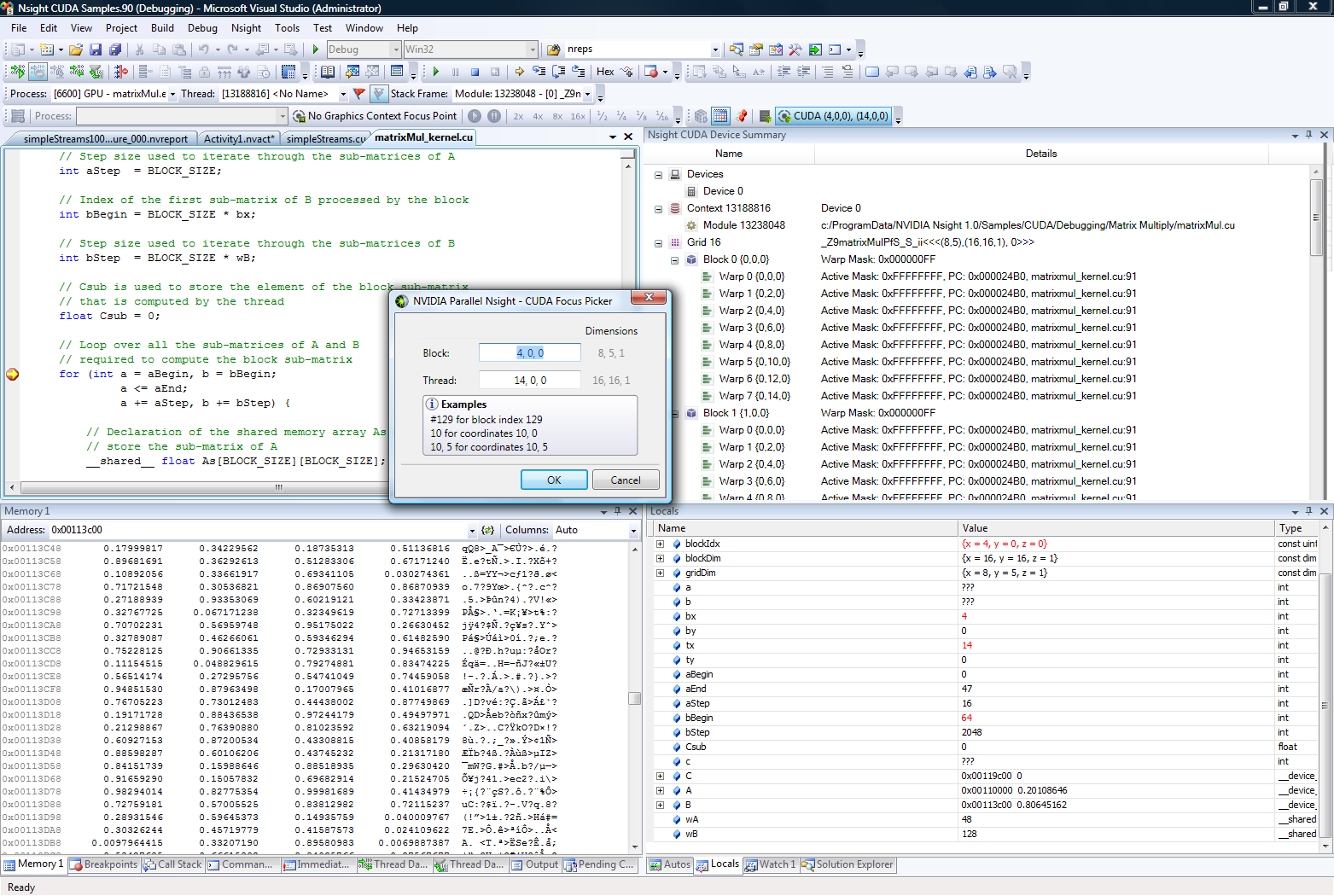
VS2008 with Parallel Nsight 1.0
In order to accomplish this goal, NVIDIA wrote a plugin for Visual Studio to enable the complete programming and debugging of CUDA and graphics code within Visual Studio – something that wasn’t previously possible – called Parallel Nsight. We first saw Parallel Nsight last year when Fermi was introduced under the name Nexus, and it finally shipped a few months ago along-side the first Fermi based Tesla cards. Since then roughly 8,000 developers have signed up to use the plugin.
On Wednesday the 22nd NVIDIA will be releasing the first major update to Parallel Nsight with release 1.5 of the plugin. Headlining this launch is the inclusion of Visual Studio 2010 support, bringing Parallel Nsight up to date with Microsoft’s IDE. Previously Parallel Nsight only supported VS 2008, which left Parallel Nsight behind as companies and developers began switching to Visual Studio 2010.
On the backend of things, Parallel Nsight 1.5 will be expanding the debugging capabilities of the plugin, particularly on single-system scenarios. Because the GPU needs to maintain the compute or graphics context being debugged, the only way to do debugging was to have a second system or a virtualized system to work with – one system to actually run the code, and a second system to debug from. While this is still (and likely always will be) the preferred method of debugging, it was impractical for single developers and smaller shops that couldn’t dedicate a second machine to the task.
For those programmers, Parallel Nsight 1.5 will be adding support for debugging compute code within a single system when multiple GPUs are present. This allows one GPU to run the application, and then a second GPU to actually drive the computer’s display. In this case the GPUs don’t even need to match so long as it's an NVIDIA GPU, allowing developers to use a high-end GPU for programming purposes while using a lesser GPU to drive the display, effectively halving the amount of hardware required for debugging. However at this time this single-system debugging support only applies to compute; shader debugging still requires a second system.
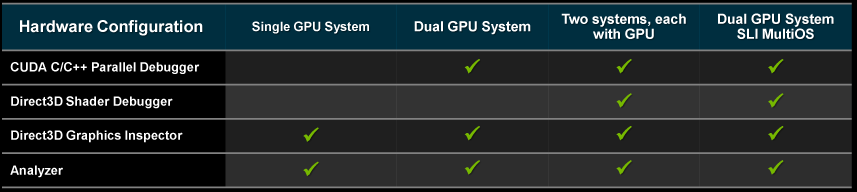
Parallel Nsight Debugging Configurations
The second big feature coming to Parallel Nsight 1.5 will be the addition of support for debugging code on a GPU running in Tesla Compute Cluster (TCC) mode. Since we don’t regularly cover Tesla news we haven’t had the opportunity to discuss TCC before, but in a nutshell TCC is a separate driver mode for Tesla cards that bypasses Windows’ control of a GPU through WDDM. WDDM, which was the new GPU driver model released with Windows Vista, was geared towards better integrating a GPU in to the OS by giving the OS more direct control of the GPU. The OS provided a virtual address space for video memory (including paging), recovery capabilities if the GPU hung, and enforced a coarse level of task scheduling on the GPU so that multiple processes could share a GPU without unnecessarily dragging a system down.
Compared to the old XPDM, WDDM was a big step up for GPU usage on Windows, but only for graphical purposes. With Windows’ iron-fisted control over the GPU and a focus on task scheduling for responsiveness over performance, it wasn’t ideal for GPGPU purposes. Case in point, with a WDDM driver NVIDIA was finding it took 30μs for a kernel to be launched, but if they had Windows treat the GPU as a generic device by using a Windows Driver Model (WDM) driver, that launch time dropped to 2.5μs. This coupled with the fact that a WDM driver is necessary to use Tesla cards in a Windows Remote Desktop Protocol environment (as any Folding @Home junkie can tell you, RDP sessions can’t access the GPU through WDDM) resulted in the birth of TCC mode.
Previously GPUs running in TCC modecould run applications, but the system functioned somewhat in a black box manner. In order to debug that code the GPU would need to be running with a regular WDDM driver, which had a performance impact and also meant it wasn’t possible to do this debugging in conjunction with an RDP session. With Parallel Nsight 1.5, it’s now possible to debug code on a GPU running in TCC mode, finally allowing developers to debug code against the same driver that the production version of the program would be running on.
The third major addition is support for profiling DirectCompute code when it’s used in conjunction with Direct3D. This is primarily a feature for game developers, who previously did not have an effective way to profile the performance of DirectCompute code in their games. DirectCompute has been underutilized in games so far, so perhaps this will expand its use.
Last but not least, Parallel Nsight 1.5 is also adding support for the new 3.2 version of the CUDA Toolkit
CUDA Toolkit 3.2
The CUDA toolkit is the agglomeration of all of NVIDIA’s programming tools: compilers, drivers, and libraries. Version 3.0 of the toolkit added support for the Fermi architecture and its unique features like C++, and version 3.2 will be the first major expansion of the toolkit since then.
A big focus for 3.2 is going to be on libraries. Libraries are a critical component for efficient GPU and CPU programming, as they provide hand-optimized implementations of common functions. Generally speaking, if you can hand something off to a library you can speed up that portion of the task significantly, and if the library can find a way to do something faster than before then it will also speed things up. For 3.2 NVIDIA is adding libraries for sparse matricies (CUSPARSE), H.264 encoding, and random number generation (CURAND), while also improving the performance of the existing math libraries such as the FFT and BLAS libraries.
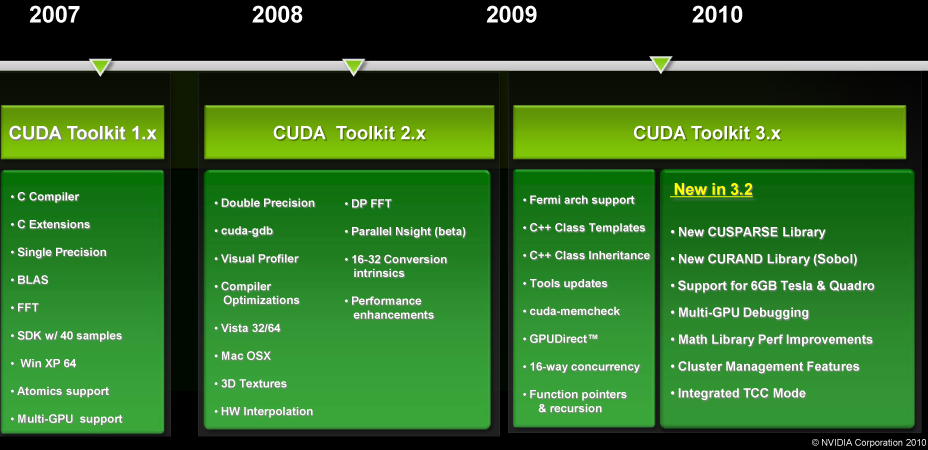
The other big change will be the full realization of the 64bit address space of Fermi family Tesla cards. The hardware has been capable of addressing better than 32bits (4GB) of memory, but the software had not fully caught up. With the impending release of 2Gb GDDR5 RAM, 24 chip 6GB Tesla cards will be made possible, requiring the software to catch up. As of version 3.2 the toolkit (and Parallel Nsight) will be able to address these cards.
The 3.2 version of the toolkit largely goes hand-in-hand with Parallel Nsight 1.5, however at the moment it’s lagging behind Parallel Nsight by a bit. The release candidate of the toolkit will be ready shortly (likely at or before the Parallel Nsight 1.5 release) but the final version will not be ready until November.

All of these items will be on display next week, when NVIDIA hosts their annual GPU Technology Conference. We’ll be there for the later part of the conference to get a pulse on the state of GPGPU usage in consumer applications and to do some reconnaissance for future GPGPU articles, so stay tuned for our reporter’s notebook from GTC next week.








22 Comments
View All Comments
Sahrin - Tuesday, September 14, 2010 - link
I think that OpenCL is the future, but based on nVidia's past I don't think for one second *they* (more specifically, Jen-Hsun Huang) believe that the market desires a less-expensive and competitive open platform.taltamir - Tuesday, September 14, 2010 - link
CUDA is literally the ability to run C code on an nvidia GPU (and fortran)... I see no reason for it to die.There is absolutely no reason for nvidia to do things via openCL, and there is nothing wrong with nvidia doing things via CUDA.
don't like it, don't run your scientific processing on CUDA...
Crimson001 - Tuesday, September 14, 2010 - link
Just because they're adding to CUDA doesn't mean they've forgotten OpenCL. Most of what OpenCL is, is Cuda being toned down so it can work on ATI cards.You know as soon as the Khronos group gets around to updating OpenCL NVidia will be more than ready as their cards will already support it, and they'll have 90% of the driver code/utilities already written. They've supported OpenCL since its inception and have had drivers for it as soon as was possible.
Its great to see CUDA being updated. Because progress on CUDA will eventually mean more progress on OpenCL as the 'must have' features trickle down.
mindbomb - Tuesday, September 14, 2010 - link
they included directcompute.opencl is basically dead though. It's too difficult to use.
B3an - Wednesday, September 15, 2010 - link
Kids like you need to die already.CUDA as far superior, more capable, and has better tools than OpenCL.
Theres things it can do right NOW that OpenCL simply cant. Are these people that use it meant to give up on what they do because they're not using something thats "open"? WTF kind of logic is that? Are Microsoft meant to stop developing Windows and DirectX because they are not as open as Linux and OpenGL? Are people not meant to have a choice and choose which is best for them?
All these people like you commenting here are so stupid i actually feel sorry for you.
And open does not always = better. It has advantages, but many open standards take far too long to be updated because of all the parties involved. A good example is Flash vs most other web tech/languages. Flash gets updates every year with new features and will always be way ahead of HTML because of this, the last time HTML was updated before version 5.0 was in the late 90's. I'm sure it wont be this bad with OpenCL but it wont catch up to CUDA, or atleast for many years.
7Enigma - Tuesday, September 14, 2010 - link
Guys I know you are writing these articles like mad (and we greatly appreciate them), but the last 2 days has been awful. I don't mind mispellings, but when I have to reread a sentence more than once it gets tiring (or in the case of this beauty, " in large part to the GPU’s ability to the GPU’s unified address space, ECC support, and support for C++", not even grasp what you are trying to say).Please just do a once over if possible to make them a bit more reader-friendly.
catavalon21 - Tuesday, September 14, 2010 - link
" I don't mind mispellings..."You're sure you really want to go there?
dingetje - Wednesday, September 15, 2010 - link
opencl should have (at least) been mentioned in this articleaaron92 - Wednesday, September 15, 2010 - link
"Not to outdone..."Not too outdone or Not to be outdone?
MrSpadge - Wednesday, September 15, 2010 - link
Any chance we could eventually use WDM drivers for our regular desktop GPUs? For example GPU-Grid has serious performance problems udner Vista and Win 7 thanks to WDDM drivers. And since soon all CPUs are going to bring some integrated GPU along it would only be logical to use the discrete GPU for crunching (and switching to games if needed) and the smallest GPU in the PC to drive the desktop.MrS