Server Clash: DELL's Quad Opteron DELL R815 vs HP's DL380 G7 and SGI's Altix UV10
by Johan De Gelas on September 9, 2010 7:30 AM EST- Posted in
- IT Computing
- AMD
- Intel
- Xeon
- Opteron
Response Times
At low 30% to 60% utilization, we cannot compare throughput. The throughput is more or less the same on all machines. Response times make the difference here. It is important to interprete the numbers carefully though.
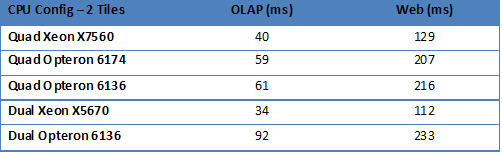
This might come as a surprise, but the dual Xeon X5670 inside the HP DL380 G7 comes out as the best (fastest) server here. The Xeon X5670 extracts more parallelism out of the code of one thread and clocks one core quite a bit higher than the other cores. Response times are measured per URL/query, thus single threaded performance is the determining factor until all cores are working as hard as they can.
We are working on about 30 virtual CPUs, or “worlds” in the eye of the ESX scheduler. The dual Xeon X5670 can offer 24 Hardware Execution Contexts (HECs), the quad Opteron 6174 can offer 48. However, the Opteron cannot leverage the HEC advantage enough in this scenario. The Xeon X7560 has more or less the same core, but a lower clock but it does not suffer from the small scheduling overhead that the Xeon 5670 suffers having less HECs than VMs running. So that is why the 2.26 Xeon 7560 offers only 10-15% higher response times.
So how important is this? Is the Xeon twice as fast as the Opteron? Not really. Remember that we measured this over low latency LAN. A typical web request send from Europe to the AnandTech server in North Carolina will take up to 400 ms. In that scenario the extra 100 ms difference between the Xeon and Opteron will start to fade.
The higher the load, the more the Opteron will narrow the gap as it starts to leverage the higher throughput.

The difference in user experience is hardly as dramatic as the numbers indicate. Whether you will care or not will also depend on the application. Some web requests can take up to 2 seconds (220 ms is only an average), so it really depends on how complex your application is. If you run at a light load and the heaviest requests are answered within half a second, nobody will notice if it is 300 or 180 ms. But if some of your requests take more than a second even under "normal" load, this difference will be noticeable.
So response time under "normal" load might not be as important as under heavy load, but the numbers above also show you that throughput is not everything. Single threaded performance is still important, and we definitely feel that the UltraSparc T2 approach is the wrong one for most business applications out there. A good balance between single-threaded and multi-core is still advisable for our web applications that get heavier as we build upon feature rich Content Management Systems.
Once we load the systems close their maximum, a totally different picture emerges. Below you can see the response times with much higher concurrencies and the four tiles of full vApus Mark II testing. Remember that the concurrencies are 10 times higher and the OLTP test is included.
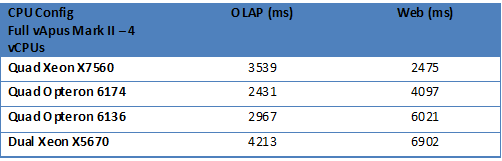
The quad Xeon wins in the web tests while the quad Opteron leads in the OLAP tests. The OLAP test is more bandwidth sensitive and that is one of the reasons that the quad Opteron configurations excel there.
The dual Xeon 5670 has only 24 HECs to offer and 72 worlds are constantly demanding CPU power. No wonder that the dual Xeon is completely swamped and as a result has the worst response times.








51 Comments
View All Comments
cgaspar - Friday, September 10, 2010 - link
The word you're looking for is "authentication". Is a simple spell check so much to ask?JohanAnandtech - Friday, September 10, 2010 - link
Fixed.ESetter - Friday, September 10, 2010 - link
Great article. I suggest to include some HPC benchmarks other than STREAM. For instance, DGEMM performance would be interesting (using MKL and ACML for Intel and AMD platforms).mattshwink - Friday, September 10, 2010 - link
One thing I would like to point out is that most of the customers I work with use VMWare in an enterprise scenario. Failover/HA is usually a large issue. As such we usually create (or at least recommend) VMWare clusters with 2 or 3 nodes. As such each node is limited to roughly 40% usage (memory/CPU) so that if a failure occurs there is minimal/0 service disruption. So we usually don't run highly loaded ESX hosts. So the 40% load numbers are the most interesting. Good article and lots to think about when deploying these systems....lorribot - Friday, September 10, 2010 - link
It would be nice to see some comparisons of blade systems in a similar vein to this article.Also you say that one system is better at say DBs whilst the the other is better at VMware, what about if you are running say a SQL database on a VMware platform? Which one would be best for that? How much does the application you are running in the VM affect the comparative performance figures you produce?
spinning rust - Saturday, September 11, 2010 - link
is it really a question, anyone who has used both DRAC and ILO knows who wins. everyone at my current company has a tear come to their eyes when we remember ILO. over 4 years of supporting Proliants vs 1 year of Dell, i've had more hw problems with Dell. i've never before seen firmware brick a server, but they did it with a 2850, the answer, new motherboard. yay!pablo906 - Saturday, September 11, 2010 - link
This article should be renamed servers clash, finding alternatives to the Intel architecture. Yes it's slightly overpriced but it's extremely well put together. Only in the last few months has the 12c Opteron become an option. It's surprising you can build Dell 815's with four 71xx series and 10GB Nics for under a down payment on a house. This was not the case recently. It's a good article but it's clearly aimed to show that you can have great AMD alternatives for a bit more. The most interesting part of the article was how well AMD competed against a much more expensive 7500 series Xeon server. I enjoyed the article it was informative but the showdown style format was simply wrong for the content. Servers aren't commodity computers like desktops. They are aimed at a different type of user and I don't think that showdowns of vastly dissimilar hardware, from different price points and performance points, serve to inform IT Pros of anything they didn't already know. Spend more money for more power and spend it wisely......echtogammut - Saturday, September 11, 2010 - link
First off, I am glad that Anandtech is reviewing server systems, however I came away with more questions than answers after reading this article.First off, please test comparable systems. Your system specs were all over the board and there were way to many variables that can effect performance for any relevant data to be extracted from your tests.
Second, HP, SGI and Dell will configure your system to spec... i.e. use 4GB dimms, drives, etcetera if you call them. However something that should be noted is that HP memory must be replaced with HP memory, something that is an important in making a purchase. HP, puts a "thermal sensor" on their dimms, that forces you to buy their overpriced memory (also the reason they will use 1GB dimms, unless you spec otherwise).
Third, if this is going to be a comparison, between three manufactures offerings, compare those offerings. I came away feeling I should buy an IBM system (which wasn't even "reviewed")
Lastly read the critiques others have written here, most a very valid.
JohanAnandtech - Monday, September 13, 2010 - link
"First off, please test comparable systems."I can not agree with this. I have noticed too many times that sysadmins make the decision to go for a certain system too early, relying too much on past experiences. The choice for "quad socket rack" or "dual socket blade" should not be made because you are used to deal with these servers or because your partner pushes you in that direction.
Just imagine that the quad Xeon 7500 would have done very well in the power department. Too many people would never consider them because they are not used to buy higher end systems. So they would populate a rack full of blades and lose the RAS, scalability and performance advantages.
I am not saying that this gutfeeling is wrong most of the time, but I am advocating to keep an open mind. So the comparison of very different servers that can all do the job is definitely relevant.
pablo906 - Saturday, September 11, 2010 - link
These VMWare benchmarks are worthless. I've been digesting this for a long long time and just had a light bulb moment when re-reading the review. You run highly loaded Hypervisors. NOONE does this in the Enterprise space. To make sure I'm not crazy I just called several other IT folks who work in large (read 500+ users minimum most in the thousands) and they all run at <50% load on each server to allow for failure. I personally run my servers at 60% load and prefer running more servers to distribute I/O than running less servers to consolidate heavily. With 3-5 servers I can really fine tune the storage subsystem to remove I/O bottlenecks from both the interface and disk subsystem. I understand that testing server hardware is difficult especially from a Virtualization standpoint, and I can't readily offer up better solutions to what you're trying to accomplish all I can say is that there need to be more hypervisors tested and some thought about workloads would go a long way. Testing a standard business on Windows setup would be informative. This would be an SQL Server, an Exchange Server, a Share Point server, two DC's, and 100 users. I think every server I've ever seen tested here is complete overkill for that workload but that's an extremely common workload. A remote environment such as TS or Citrix is another very common use of virtualization. The OS craps out long before hardware does when running many users concurrently in a remote environment. Spinning up many relatively weak VM's is perfect for this kind of workload. High performance Oracle environments are exactly what's being virtualized in the Server world yet it's one of your premier benchmarks. I've never seen a production high load Oracle environment that wasn't running on some kind of physical cluster with fancy storage. Just my 2 cents.