AMD Discloses Bobcat & Bulldozer Architectures at Hot Chips 2010
by Anand Lal Shimpi on August 24, 2010 1:33 AM ESTA Real Redesign
When we first met Phenom we were disappointed that it didn’t introduce the major architectural changes AMD needed to keep up with Intel. The front end and execution hardware remained largely unchanged from the K8, and as a result Intel pulled ahead significantly in performance per clock over the past few years. With Bulldozer, we finally got the redesign that we’ve been asking for.
If we look at Westmere, Intel has a 4-issue architecture that’s shared among two threads. At the front end, a single Bulldozer module is essentially the same. The fetch logic in Bulldozer can grab instructions from two threads and send it to the decoder. Note that either thread can occupy the full width of the front end if necessary.
The instruction fetcher pulls from a 64KB 2-way instruction cache, unchanged from the Phenom II.
The decoder is now 4-wide an increase from the 3-wide front end that AMD has had since the K7 all the way up to Phenom II. AMD can now fuse x86 branch instructions, similar to Intel’s macro-ops fusion to increase the effective width of the machine as well. At a high level, AMD’s front end has finally caught up to Intel, but here’s where AMD moves into the passing lane.
The 4-wide decode engine feeds three independent schedulers: two for the integer cores and one for the shared floating point hardware.
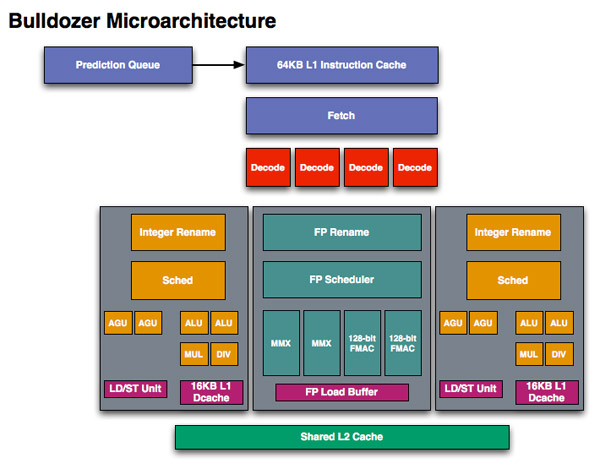
Bullddozer, 2 threads per module
Each integer scheduler is now unified. In the Phenom II and previous architectures AMD had individual schedulers for math and address operations, but with Bulldozer it’s all treated as one.
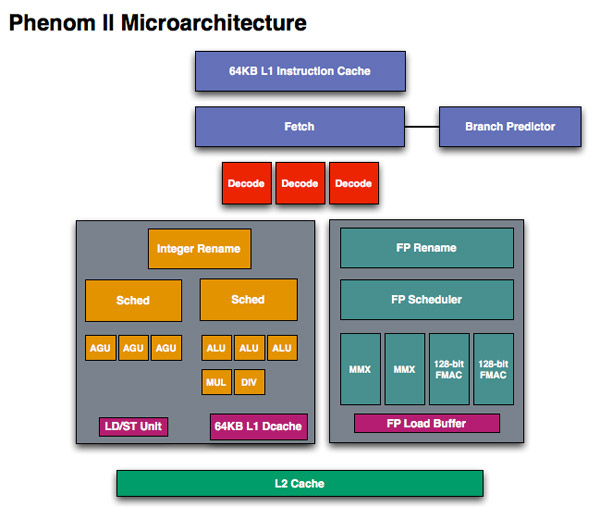
Phenom II, 1 thread per core
Each scheduler has four ports that feed a pair of ALUs and a pair of AGUs. This is down one ALU/AGU from Phenom II (it had 3 ALUs and 3 AGUs respectively and could do any mix of 3). AMD insists that the 3rd address generation unit wasn’t necessary in Phenom II and was only kept around for symmetry with the ALUs and to avoid redesigning that part of the chip - the integer execution core is something AMD has kept around since the K8. The 3rd ALU does have some performance benefits, and AMD canned it to reduce die size, but AMD mentioned that the 4-wide front end, fusion and other enhancements more than make up for this reduction. In other words, while there’s fewer single thread integer execution resources in Bulldozer than Phenom II, single threaded integer performance should still be higher.
Each integer core has its own 16KB L1 data cache. The L1 caches are segmented by thread so the shared FP core chooses which L1 cache to pull from depending on what thread it’s working on.
I asked AMD if the small L1 data cache was going to be a problem for performance, but it mentioned that in modern out of order machines it’s quite easy to hide the latency to L2 and thus this isn’t as big of an issue as you’d think. Given how aggressive AMD has been in the past with ramping up L1 cache sizes, this is a definite change of pace which further indicates how significant of a departure Bulldozer is from the norm at AMD.

While there are two integer schedulers in a single Bulldozer module (one for each thread), there’s only one FP scheduler. There’s some hardware duplication at the FP scheduler to allow two threads to share the execution resources behind it. While each integer core behaves like an independent core, the FP resources work as they would in a SMT (Hyper Threading) system.
The FP scheduler has four ports to its FPUs. There are two 128-bit FMAC pipes and two 128-bit packed integer pipes. Like Sandy Bridge, AMD’s Bulldozer will support SSE all the way up to 4.2 as well as Intel’s new AVX instructions. The 256-bit AVX ops will be handled by the two 128-bit FMAC units in each Bulldozer module.
Each Bulldozer module has its own private L2 cache shared by both integer cores and the FP execution hardware.








76 Comments
View All Comments
Zoomer - Wednesday, August 25, 2010 - link
Basically you'll need 2x the power for much less than 2x performance increase. Modern branch predictors can have very good hit rates ~90%+. It simply made more sense to use the second int unit for another thread.However, if you need the absolutely best single threaded int performance at all costs, imho, what you suggest wouldn't be bad. In fact,
Edison5do - Tuesday, August 24, 2010 - link
Finally besides the price competition, we will be able to see some tech competition, we have to raise our praise for AMD not to reject the ATI btand because New and HiTech CPU´s, should be paired with HiQuality, nice priced, Radeon GPU´s.I really dont think People are ready to see "AMD" Brand as a Head-toHead Competitor to "INTEL" Brand, by this i mean that they should rely on ATI for being well accepted by the public for more time before they even star thinking about that.
angrysand - Tuesday, August 24, 2010 - link
they may have had the on die memory controller, but Atom basically created the netbook market. AMD is just improving on what Intel help create (and that remains to be seen).I had to see AMD go because I like having resonable performance for reasonable price. But they had better get their act together and put out faster CPU's.
ABR - Wednesday, August 25, 2010 - link
Atom did not create the netbook market, some convergence of wireless data and increasing use of the web by non-computer folk did. The first "netbook" products were the Crusoe-based mini-notebooks starting in 2001. Unfortunately for Transmeta, interest in the high-portability / long battery life model was low, only a couple of models even came out, and they ended up having to compete with Intel for scraps of the low-end laptop market. They lost, and Intel only finally caught up with their technology later with the Atom, when, coincidentally or not, the market was finally ready.Nehemoth - Tuesday, August 24, 2010 - link
Why Bodcat will be manufactured in the 40nm process instead of 32nm is cause the GPU?.Why will be manufactured on TSMC instead of GlobalFoundries?.
I supposed that this could be a problem with GF not being ready in 32nm but can we see a switch from TSMC to GlobalFoundries after Bulldozer begin to be manufacture?.
iwod - Wednesday, August 25, 2010 - link
TSMC has much higher 40nm capacity then GF's 32nm. Bobcat is going to be a low end product which will hopefully generate high volume of sales. TSMC in this case will be a much better fit then GF.moozoo - Wednesday, August 25, 2010 - link
I wonder how hard it would be to make a version has two Floating point cores and one integer core.Will AMD have a product to match Intel MIC's (Larrabee) .
(http://www.anandtech.com/show/3749/intel-mic-22nm-...
YuryMalich - Wednesday, August 25, 2010 - link
Hi,There is a mistake on page 5 on this picture http://images.anandtech.com/reviews/cpu/amd/hotchi...
There were drawn two 128-bit FMAC units on Phenom II Microarchitecture.
But K10 processor doesn't have FMAC units at all! It has 1 FMUL and one FADD and one FMISC(FLOAD) units.
The FMAC (multiple-add) units are new in Bulldozer microarchitecture.
Jack Sparow - Wednesday, August 25, 2010 - link
"Ivo August 25, 2010How many threads everyone processor (“Interlagos”, “Valencia” and “Zambezi”) can do simultaneously per core compare with Phenom II processor?
Reply
John Fruehe August 25, 2010
One thread per core."
This quote is from AMD blogs home. :)
silverblue - Wednesday, August 25, 2010 - link
I think I touched on this before once on a THQ news article - John Fruehe is being confusing. The correct definition of a complete Bulldozer core is a module, which is a monolithic dual-integer core package also consisting of other shared resources - the top image on page 4 of this article is a great guide. So, a four module (or quad core as we currently term them) Bulldozer will handle eight threads concurrently as those four cores possess eight integer cores.As such, I don't see non-SMT Bulldozer cores ever coming out.