AMD Discloses Bobcat & Bulldozer Architectures at Hot Chips 2010
by Anand Lal Shimpi on August 24, 2010 1:33 AM ESTA Real Redesign
When we first met Phenom we were disappointed that it didn’t introduce the major architectural changes AMD needed to keep up with Intel. The front end and execution hardware remained largely unchanged from the K8, and as a result Intel pulled ahead significantly in performance per clock over the past few years. With Bulldozer, we finally got the redesign that we’ve been asking for.
If we look at Westmere, Intel has a 4-issue architecture that’s shared among two threads. At the front end, a single Bulldozer module is essentially the same. The fetch logic in Bulldozer can grab instructions from two threads and send it to the decoder. Note that either thread can occupy the full width of the front end if necessary.
The instruction fetcher pulls from a 64KB 2-way instruction cache, unchanged from the Phenom II.
The decoder is now 4-wide an increase from the 3-wide front end that AMD has had since the K7 all the way up to Phenom II. AMD can now fuse x86 branch instructions, similar to Intel’s macro-ops fusion to increase the effective width of the machine as well. At a high level, AMD’s front end has finally caught up to Intel, but here’s where AMD moves into the passing lane.
The 4-wide decode engine feeds three independent schedulers: two for the integer cores and one for the shared floating point hardware.
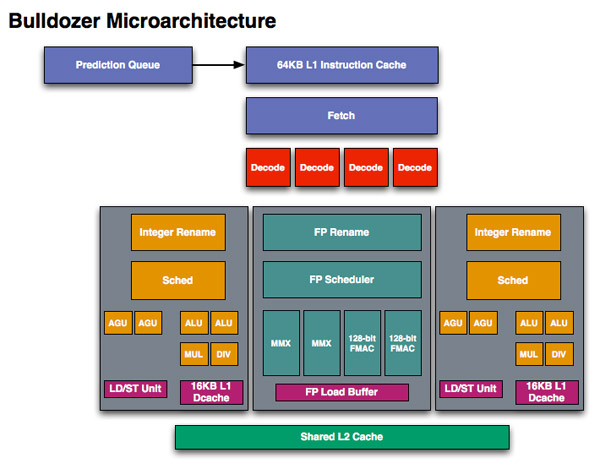
Bullddozer, 2 threads per module
Each integer scheduler is now unified. In the Phenom II and previous architectures AMD had individual schedulers for math and address operations, but with Bulldozer it’s all treated as one.
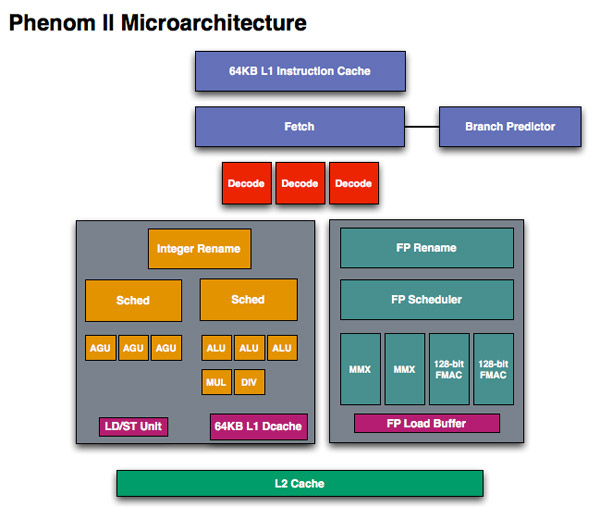
Phenom II, 1 thread per core
Each scheduler has four ports that feed a pair of ALUs and a pair of AGUs. This is down one ALU/AGU from Phenom II (it had 3 ALUs and 3 AGUs respectively and could do any mix of 3). AMD insists that the 3rd address generation unit wasn’t necessary in Phenom II and was only kept around for symmetry with the ALUs and to avoid redesigning that part of the chip - the integer execution core is something AMD has kept around since the K8. The 3rd ALU does have some performance benefits, and AMD canned it to reduce die size, but AMD mentioned that the 4-wide front end, fusion and other enhancements more than make up for this reduction. In other words, while there’s fewer single thread integer execution resources in Bulldozer than Phenom II, single threaded integer performance should still be higher.
Each integer core has its own 16KB L1 data cache. The L1 caches are segmented by thread so the shared FP core chooses which L1 cache to pull from depending on what thread it’s working on.
I asked AMD if the small L1 data cache was going to be a problem for performance, but it mentioned that in modern out of order machines it’s quite easy to hide the latency to L2 and thus this isn’t as big of an issue as you’d think. Given how aggressive AMD has been in the past with ramping up L1 cache sizes, this is a definite change of pace which further indicates how significant of a departure Bulldozer is from the norm at AMD.

While there are two integer schedulers in a single Bulldozer module (one for each thread), there’s only one FP scheduler. There’s some hardware duplication at the FP scheduler to allow two threads to share the execution resources behind it. While each integer core behaves like an independent core, the FP resources work as they would in a SMT (Hyper Threading) system.
The FP scheduler has four ports to its FPUs. There are two 128-bit FMAC pipes and two 128-bit packed integer pipes. Like Sandy Bridge, AMD’s Bulldozer will support SSE all the way up to 4.2 as well as Intel’s new AVX instructions. The 256-bit AVX ops will be handled by the two 128-bit FMAC units in each Bulldozer module.
Each Bulldozer module has its own private L2 cache shared by both integer cores and the FP execution hardware.








76 Comments
View All Comments
Dustin Sklavos - Tuesday, August 24, 2010 - link
If you're encoding using Adobe software, ditch AMD until Bulldozer. Adobe's software makes heavy use of SSE 4.1 instructions, which current AMD chips lack, and the extra two cores don't pick up the slack compared to a fast i7.flyck - Tuesday, August 24, 2010 - link
From the design of Bulldozer's FPU it is cleared that AMD want Multi Threaded FPU to run on OpenCL.Not sure what you mean with that? (it is true they want to abuse that in the future with fusion) but at this moment i see: Sandybridge 2hreads -> one FPU, Bulldozer 2 threads -> one FPU
BitJunkie - Tuesday, August 24, 2010 - link
I think he's picking up on the point that this general purpose design is going to favour integer operations over floating point. Looking at this architecture from the perspective of someone wanting to perform a lot of floating point matrix calculus then the performance improvement of each "core" is going to be proportionally less than for integer calcs.So what he's saying is that quite clearly AMD believe that general purpose CPUs are just that and have designed for a well defined balance of FP and Interger operations i.e. If you want more FLOPS go talk to the GPU?
stalker27 - Tuesday, August 24, 2010 - link
"And if Bulldozer comes any later, it will be up against the die shrink of SandyBridge, Ivy Bridge. Things dont look so good in here."Basically, you've contradicted yourself right here:
"Most of us dont need SUPER FAST computer."
True, and true.... Ivy will probably be faster than Bulldozer (speculatively) as is Nehalem to Stars, but most people, i.e. the "cash cow" won't buy these expensive products. Instead they will focus on mid to low end computers which by their performance is more then/or enough for their needs.
So things might not look good in reviews and bench tops, but in the stores and on people's bank balances they will look pretty good.
jabber - Tuesday, August 24, 2010 - link
Hooray!I'm glad at last some folks are waking up to the fact that having the fastest or most expensive CPU means absolutely jack!
All the latest fastest CPU stuff just means a little bit more internet traffic for tech review sites.
The rest of the world doesnt give a damn.
All the real world is interested in is the best CPU for the buck in a $400 PC box to run W7 and Office on. AMD needs to get a proper marketing dept to start telling folks that.
All AMD has to do is produce good performing chips for a good price. It dosent need a CPU to beat the best of Intel.
The real world lost interest in CPU performance the minute dual cores arrived and they could finally run IE/Office and a couple of mainframe sessions without it grinding to a halt.
I bet Intel gives out more review samples of its top CPU than it sells.
JPForums - Tuesday, August 24, 2010 - link
"All the real world is interested in is the best CPU for the buck in a $400 PC box to run W7 and Office on. AMD needs to get a proper marketing dept to start telling folks that.""The real world lost interest in CPU performance the minute dual cores arrived and they could finally run IE/Office and a couple of mainframe sessions without it grinding to a halt."
Apparently us Engineers aren't part of "The rest of the world".
Try running products from the likes of Mentor Graphics, Cadence, and Synopsis for reasonably large designs. Check out what a difference each new CPU makes in PROe (assuming sufficient GPU horsepower). Run some large Matlab simulations, Visual studio compilations, and Xilinx builds. You don't even have to get out of college before you run into many of these scenarios.
Trust me when I say that we care about the next greatest thing.
An extra $1000 dollars on a CPU is easily justified when companies are billing $100+ per Engineering hour (not to be confused with take home pay).
BitJunkie - Tuesday, August 24, 2010 - link
Exactly so: An example would be a 24hr calculation to perform a detailed 3D finite element analysis. This is not unusual using highly spec'd Xeon work stations from your vendor of choice.It might take 5 to 10 days to set up a model including testing of different aspects: Mesh density, discretisation errors, boundary effects, parametric studies. The set up time with numerous supporting pre-analysis runs is what really costs. Anything we can do to reduce this is worth while.
The above would be the typical process BEFORE considering a batch-job on a HPC cluster if we wanted to look at a series of load cases etc.
Time is money.
mapesdhs - Tuesday, August 24, 2010 - link
I know a number of movie studios who love every extra bit of
CPU muscle they can get their hands on. Rendering really
hammers current hardware. One place has more than 7000
XEON cores, but it's never enough. Short of writing specialised
sw to exploit shared-memory machines that use i7 XEONs (which
has its own costs), the demand for ever higher processing
speed will always persist. Visual effects complexity constantly
increases as artists push the boundaries of what is possible.
And this is just one example market segment. As BitJunkie
suggests, these issues surface everywhere.
Another good example: the new Cosmos machine in the UK
which contains 128 x 6-core i7 XEON (Nehalem EX) with
2TB RAM (ie. 768 cores total). This is a _single system_,
not a cluster (SGI Altix UV). Nothing less is good enough for
running modern cosmological simulations. There will be
much effort by those using the system on achieving good
efficiency with 512+ cores; atm many HPC tasks don't scale
well beyond 32 to 64 cores. Point being, improving the
performance of a single core is just as important as general
core scaling for such complex tasks. SGI's goal is to produce
a next-gen UV system which will scale to 262144 cores in
a single shared-memory system (32768 x 8-core CPUs).
You can never have enough computing power. :D
Ian.
stalker27 - Wednesday, August 25, 2010 - link
You're 1% of the market... for you, Intel and AMD have reserved cherry-picked chips that they can charge you 1K for but at the same time offer you that needed speed. How's that?BTW, he said real world, not rest of the world. That makes you somewhat of an illusion. But don't take it the bad way... more like most of us would dream working in an environment full of hot setups, big projects and big bux, unlike in the real world where you have to mop the floor after debugging for 8 hours straight... if they don't force you to work extra two hours without pay, never-mind that before you start the workday you have to go to various bureaucratic public clerk offices to deal with stuff that was supposed to be taken care by secretaries... which got fired for no apparent reason some time ago.
So stop moaning... you have it good, even as 1%.
Makaveli - Tuesday, August 24, 2010 - link
lol if AMD and intel followed your logic we would all still be running Pentium 2 and socket A Athlons silly boy.You make yourself look like an ass when you make a generalized statement like that, as if you are speaking for the rest of the world.
As that other guy pointed out some of us do more than just office work on our pc's!