Everything You Always Wanted to Know About SDRAM (Memory): But Were Afraid to Ask
by Rajinder Gill on August 15, 2010 10:59 PM ESTWhat do you mean you've never heard of Adaptive Page Management (APM) Technology? Well, that must be because Intel Marketing doesn't seem to feel the need to bring it up.
Simply put, Intel's APM determines, based on the potential implications of pending memory transactions, whether closing open pages, or allowing them to remain open longer may be beneficial to overall memory performance. In response, the memory controller may (or may not) elect to issue commands to close pages, depending on the programmed operation.
Figure 10 provides the general flow of events required to manage such a process. In our explanation we intend to introduce you to all known register settings needed to adjust the functional control policy, but first we need to detail the necessary actions, and purpose, of the design elements that make up such a mechanism. A better understanding of the underlying logic will pay dividends as you attempt to dial in measurable performance improvements through experimentation.
Per Figure 11, the Transaction Queue stores memory transactions generated by the processor. Unlike a typical First-In-First-Out (FIFO) queue with a tail, into which memory transaction may be pushed, and a head, from which memory transactions may be popped, this transaction queue is a plurality of storage elements allowing single memory transactions to be removed from the list and dispatched toward the memory in a different ordering than when originally added to the queue.
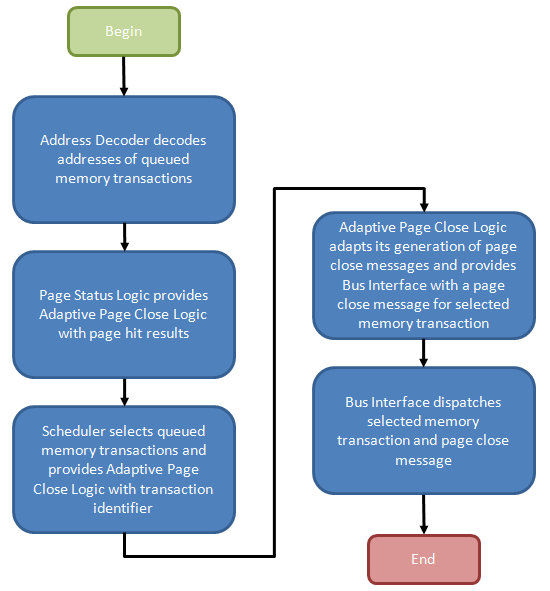
Command re-ordering can improve perceived memory performance by grouping together reads/writes to a common physical page in memory, saving the time that would otherwise be needed to later re-open the same page, should a concurrent access to the same bank force it to close early. After all, the minimum delay between sequential accesses to the same open page is equal to the CAS Latency (CL or tCAS) of the device. Accessing a bank (opening a page) increases the latency of the post-interleaved operation by the Row-Column (or Command) Delay (tRCD), approximately doubling the effective data access time.
One should also appreciate that there are varying degrees of freedom when shuffling transactions in time. Like in the case of a read and write to the same memory location: the memory controller would be disallowed from moving the dependent read either ahead of or behind the associated write as the ordering must be implicitly maintained or coherency will be lost.
The Address Decoder partially decodes the memory transactions stored in the Transaction Queue as needed to determine the bank and page selected by each queued request. From there, the Bank Select messages control the multiplexers used to input the contents of a Bank Register to a comparator used to check if the selected page was also the most recently opened page for that bank (as such, each Bank Register is large enough to store n bits where each bank comprises 2n pages). A match results in the creation of a Page-Hit Result message.
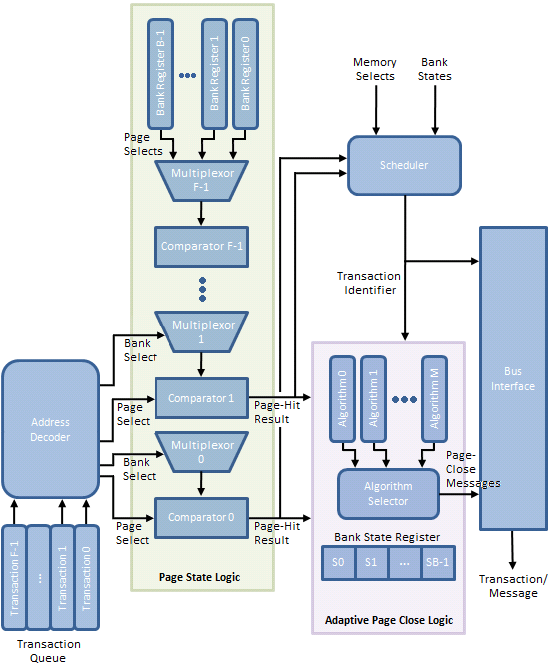
Triggered by the Page State Logic, the Scheduler fetches pre-identified queued memory transactions for re-ordering based on the Memory Selects (both bank and page) and the associated Page-Hit Results. An array of Bank State Registers track actions performed upon each bank by storing a state-word indicating, among other things, whether the Adaptive Page Close Logic decided to close the bank in response to a previous memory transaction to the same bank.
Finally, based on the policy instantiated by the Algorithm Selector, a Page-Close Message either is or is not generated based on the same Page-Hit Results, Bank State Registers, and Bank/Page Selects in an effort to increase the number of subsequent page-hit accesses and/or decrease the number of page-miss accesses.
An immediate and tangible gain is achieved for every successfully re-ordered transaction as a page-hit access is more efficient than a page-empty, or at worst, a page-miss. This is always the case with Core i7 and is one of this architecture's well known shinning points. Switch off Adaptive Page Management (disable Adaptive Page Closing in BIOS) and this is where the process ends. The page may stay open for some finite time or it may be closed right away; we're not sure as there's really no way to know without some inside help.
The Adaptive Page Close Logic must now decide whether to collect all winnings, and close the page, or let it ride, and leave it open just a while longer. While another page-hit access may yield further gains, "guessing" wrong will cause a costly page-miss access in place what would have been just a page-empty access. If only there were some way the system could measure the effectiveness of previous close decisions and then adjust policy to fit...
Surprise! The Page Manager - made up of the Page State Logic, Adaptive Page Close Logic, and Scheduler - does exactly this. How this effectiveness is measured, and how the result of that evaluation is used to adapt the decision-making process is our next topic of discussion.








46 Comments
View All Comments
JarredWalton - Monday, August 16, 2010 - link
Oh, it's missing a lot more than just voltage information. :-) There are rebates on most memory kits right now, for instance. Still, I felt it was useful to highlight where the current "best deals" tend to fall.I personally wouldn't touch the ultra-expensive $150+ stuff, but up to $115 has potential at least. For a lower voltage kit, G.Skill has an ECO line rated at DDR3-1600 7-8-7-24-2N and 1.35V for $103. Worth a look at least....
JarredWalton - Monday, August 16, 2010 - link
Note: I screwed up my table above. DDR3 is two bits per clock, so the base clocks are all twice what I listed, which means latency for CAS is half what I listed. Sorry. Got things confused with GDDR5. :-) The relative latency is still the same, of course, which is the main point.JarredWalton - Monday, August 16, 2010 - link
Side note number two: And of course, CAS Latency isn't the be-all, end-all. According to benchmarks by Raja, DDR3-2000 at 6-9-6 timings often trails RAM at 7-8-7, as the tRCD difference becomes more pronounced in some cases.Rajinder Gill - Monday, August 16, 2010 - link
Sorry I should have said 7-7-8 vs 6-9-8. This happens when the number of random access requests are high (fewer back to back reads). Benchmarks like WinRar and Super Pi (synthetic) are mainly the ones that show this.-Raja
Drag0nFire - Friday, August 20, 2010 - link
I've had great experience with the ECO line. Put the 2x2 kit you mentioned in two computers so far, and it's been great. Feels like a steal to get such high speed and low voltage at such a great price.kalniel - Monday, August 16, 2010 - link
Thanks for taking the time to write the article - the cycle time-line figures are very helpful, but I'm struggling to understand it correctly.Take fig. 5. There doesn't seem to be a Read to Precharge Delay. If we follow the recommendation of CL+tBurst = tRCP + tRP then won't there be a delay of 4T after the Data Read Burst before the RAS Precharge starts, giving a Row Cycle Time of 26 rather than 24?
kjboughton - Monday, August 16, 2010 - link
tRTP may very well be 4T but the minimum RAS Active Time (tRAS) is 18T. The precharge is precluded from occuring until this period has expired making the clock at T + 18 the first opportunity to precharge the bank. Add to this the RAS Precharge (tRP) and you have the Row Cycle Time (tRC = tRAS + tRP) - the minimum time any single row MUST remain open before it can be closed (and before another page in the same bank can be accessed).Does this help?
kalniel - Monday, August 16, 2010 - link
I thought the Read to Precharge Delay was there precisely to ensure you waited the minimum RAS active time before precharging the bank. Are you saying that the tRTP doesn't apply if you've already finished tRCD+CL+tBurst within tRAS so can start precharging as soon as minimum RAS active time is achieved?In other words, tRTP doesn't have a bearing on a single burst per page, but is there to help synchronise auto-precharge reads within the same page?
My ignorance may be beyond redemption!
kjboughton - Monday, August 16, 2010 - link
Read to Precharge Delay (tRTP) is the minimum wait time from a READ (column access) to bank PRECHARGE.RAS Active Time (tRAS) is the minimum wait time from an ACTIVATE (row access) to bank PRECHARGE.
Both times must be satisfied before the bank can be precharged. Perhaps I wasn't quite clear enough on this point. I hope this clears things up.
kalniel - Monday, August 16, 2010 - link
I think I've got it now, thanks. My brain saw the relevant diagram and screamed 'Cthulu' instead.