Intel X25-V in RAID-0: Faster than X25-M G2 for $250?
by Anand Lal Shimpi on March 29, 2010 8:59 PM ESTSequential Read/Write Speed
Using the 6-22-2008 build of Iometer I ran a 3 minute long 2MB sequential test over the entire span of the drive. The results reported are in average MB/s over the entire test length:

This starts out very interesting. Each SATA port on our X58 board is bound by a 3Gbps transfer limit, but run two in parallel and you can go much higher. Our pair of X25-Vs are actually faster than Crucial's RealSSD C300 on a 6Gbps controller! That's absolutely nuts.
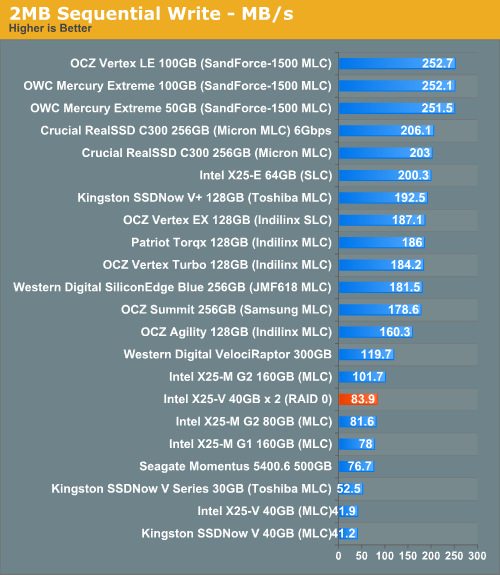
Sequential write speed also shows a near doubling of performance, unfortunately that only brings us up to ~84MB/s. It's not bad for most users but if you do a lot of heavy downloading or file copying, you'll still be behind an Indilinx, Crucial or SandForce drive.








87 Comments
View All Comments
BarneyBadass - Tuesday, March 30, 2010 - link
Anand,Thank you so much for such a well thought out, executed and documented report. I was so surprised, but then, perhaps I shouldn't have been.
So now the question has to be..... what happens with a pair of Crucial's RealSSD C300 in RAID 0?
It would be interesting to see if the same kind of scalar results observed using the 2 Intel X25-V in RAID-0 are observed with 2 of the Crucial's RealSSD C300 in RAID 0.
Over kill? perhaps. Heck, I could almost build a complete system for the cost of the 2 Crucial RealSSD C300 SSD's alone, but it's the whole performance thing I'm curious about.
Do you have any numbers on how Crucial's RealSSD C300 in RAID 0 work out on SATA-3 CTLRs or did I miss the whole thing and all the comparisons are of SSD's in raid 0?
TIA
GullLars - Tuesday, March 30, 2010 - link
C300 will scale almost perfectly from ICH10R, but 4KB random read IOPS will scale as a function of Queue Depth and not be noticably higher than single untill QD 7-8. Anything above the stripe size will recieve a noticable boost in random performance. This is true for all SSD (the QD the difference will stand out will differ by controller type and #channels).I have not yet seen RAID numbers for any SATA 3 motherboard controllers, so there i cannot comment, but from a RAID card or HBA like LSI 9000-series, you should get perfect scaling. In larger arrays IOPS may be bound by the RAID logic chip. For the LSI 9000-series, IOPS regardless of block size, read or write, random or sequential, tops out around 80.000 for integrated RAID-0. (wich will likely not be an issue outside servers)
GullLars - Tuesday, March 30, 2010 - link
This was a great test, and one that i've been nagging for a few months now. I'm a bit disappointed you stopped at 2 x25-V's and didn't do 3 and 4 also, the scaling would have blown your chart away, while still comming in at a price below a lot of the other entries.I would also love if you could do a test of 1-4 Kingston V+ G2 64GB RAID-0, as it seems as the sweet-spot for sequential oriented "value RAID".
I feel the need to comment your comment under the random write IOmeter screenshot:
"Random read performance didn't improve all that much for some reason. We're bottlenecked somewhere else obviously."
YES, you are bottlenecked, and ALL of the drives you have tested to date that support NCQ have also been so. You test at Queue Depth = 3, wich for random read will utilize MAX 3 FLASH CHANNELS. I almost feel the need to write this section in ALL CAPS, but will refrain from doing so to not be ignored.
The SSDs in your chart has anywhere between 4 and 16 flash channels. Indilinx Barefoot has 4, x25-V has 5, C300 has 8, x25-M has 10, and SF-1500 has 16. And i repeat: YOU ONLY TEST A FRACTION OF THESE, so there is no need to be confused when there is no scaling by adding more channels through RAID. 2 x25-V's in RAID-0 has the same ammount of channels as x25-M, but twice the (small block parallell, large block sequential) controller power.
For your benefit and clarification, i will now list the 4KB random read bandwidth the controllers i've mentioned above are capable of if you test them at the SATA NCQ spec (32 outstanding commands).
Indilinx Barefoot (MLC): 16K IOPS = 64MB/s
Intel x25-V: 30K IOPS = 120MB/s
C300: 50K IOPS = 200MB/s
Intel x25-M: 40K IOPS = 160MB/s
SF-1500: 35K IOPS = 140MB/s
As a sidenote, most of these SSDs scale about 20MB/s pr outstanding IO with a flattening curve at the end. Indilinx Barefoot is the exception wich scales linearly to 60MB/s at QD 5 and then flattens completely.
A RAID-0 of 2 x25-V will do 60K 4KB random read IOPS @ QD 32 = 240MB/s. I have IOmeter raw data of 4 x25-V's in RAID-0 from ICH10R performing 120K 4KB random read IOPS @ QD 32 = 480MB/s.
4 Kingston V+ G2 RAID-0 is anticipated to come in at 15-20K IOPS 4KB random read = 60-80MB/s (@QD 4-5), 6K 4KB random write IOPS = 24MB/s (acceptable), 600+ MB/s sequential read (will max out ICH10R), and about 400-450 MB/s sequential write (possibly a bit lower after degrading).
With this in mind, I again ask for a listing of IOPS @ QD 32 besides or below the test at QD 3 to show the _AVALIBLE PERFORMANCE_ and not only the "anticipated realistic IOPS performance".
Also, it would be appreciated if you list wich stripe size you used. Generally on Intel SSDs, the smaller stripe the better the real life result. This is also reflected in PCmark Vantage.
rundll - Tuesday, March 30, 2010 - link
Lars, could you kindly elaborate this:"if you test them at the SATA NCQ spec (32 outstanding commands)."
How one can tweak this queue depth?
And then one comment on the fact that TRIM doesn't work through RAID.
Maybe a good choice for RAID is Kingston SSDNow V Series (2nd Gen) 128GB SSD (or perhaps 64GB would work similarly?). That's because it appears to recover from a heavy pounding in no time without TRIM. Allyn M. with PCper says like this after testing the Kingston:
"the JMicron controller behaved like all other drives, but where it differed is what happened after the test was stopped. While most other drives will stick at the lower IOPS value until either sequentially written, TRIMmed, or Secure Erased, the JMicron controller would take the soonest available idle time to quickly and aggressively perform internal garbage collection. I could stop my tool, give the drive a minute or so to catch its breath. Upon restarting the tool, this drive would start right back up at it's pre-fragmented IOPS value.
Because of this super-fast IOPS restoring action, and along with the negligible drop in sequential transfer speeds from a 'clean' to 'dirty' drive, it was impossible to evaluate if this drive properly implemented ATA TRIM. Don't take this as a bad thing, as any drive that can bring itself back to full speed without TRIM is fine by me, even if that 'full speed performance' is not the greatest."
GullLars - Tuesday, March 30, 2010 - link
"Lars, could you kindly elaborate this:"if you test them at the SATA NCQ spec (32 outstanding commands)."
How one can tweak this queue depth?"
Anand does his testing in IOmeter. IOmeter has a parameter called # of outstanding IO's. This is the queue depth (QD). You tweak it by changing 1 number from 3 (as anand has) to 32.
The Kingston V+ G2 (JMF618) 64GB is IMO a drive worth considering RAIDing if you care a great deal about sequential performance. It has the highest bandwidth/$ of any SSD (except the 32GB version). 200/110 MB/s read/write pr SATA port makes it fairly easy to scale bandwidth cheaply, while still getting sufficient IOPS. I say 64GB and not 128GB, since you don't get any scaling of read bandwidth from 64GB to 128GB while the price almost doubles, and write bandwidth only scales moderatly. If you have a higher budget and need high seq write bandwidth, the 128GB is worth looking at if you have few ports availible.
JMF618 does about 4000-5000 4KB random read IOPS and roughly 1500 random write.
That this controller seems to be resilient to degradation matters little when you only have 1500 random write IOPS in the first place. x25-V has 10.000, C300 and SF-1500 has roughly 40.000. None of these will degrade below 1500 IOPS no matter how hard you abuse them, and will typically only degrade 10-25% in realistic scenarios. If you increase spare area this is lowered.
I have RAIDed SSDs since aug 2008, and i know people who have RAIDed larger setups since early 2009, and there are seldom problems with degrading, almost never with normal usage patterns. The degrading happens when you benchmark, or have intensive periods of random writes (VMware, database update, etc).
galvelan - Wednesday, March 31, 2010 - link
@GullLarsHave a question for you regarding advice you gave another regarding stripe size for a raid setup. I frequent the other forum you do as well but would like to know what your knowledge is of write amplification is. At the other forum Ourasi wrote that he found 16-32kb best, just like you mentioned. But the others said that is not good for performance and would destroy the SSD's quicker due to write amplification of having to do multiple writes with the write block being larger than the stripe size selected. I believe the sense of what you and Ourasi said in the other forum, but how does that effect the write amplification? Can you explain more on that?
P.S. I replied to another comment you made but anands comment system didnt take it dont know why so trying again. ;-)
GullLars - Thursday, April 1, 2010 - link
There is no impact on write amplification from the striping. It can be explained pretty simply.SSDs can only write a page at a time (though some can do a partial page write), and page size is 4KB on current SSDs. As long as the stripe size is above 4KB, you don't have writes that leaves space unusable.
With a 16KB stripe size, you will write 4 pages on each SSD alternating and in sequential LBAs, so it's like writing sequential 16KB blocks on all SSDs, and as the file size becomes larger than {stripe size}*{# of SSDs} you will start increasing the Queue Depth, but it's still sequential.
Since all newer SSDs use dynamic wear leveling with LBA->physical block abstraction, you won't run into problems with trying to overwrite valid data if there are free pages.
The positive side of using a small stripe is a good boost in files/blocks between the stripe size and about 1MB. You will see this very clearly in ATTO as the read and write speeds doubles (or more) when you pass the stripe size. F.ex. 2R0 x25-M with 16KB stripe jumps from ~230 MB/s at 16KB to ~520MB/s at 32KB (QD4). This has a tangable effect on OS and app performance.
galvelan - Friday, April 2, 2010 - link
Thanks GullLars!!!I will try out the 16k stripe. I have 3 40gb intel v SSD's on the a ICH10R. Would 16k be okay for this setup?
By the way could you explain to me why they are confusing the write amplification as being a problem with these type of stripe sizes. You and Ourasi's explanations make perfect sense to me. Some actually even believed Ourasi and had questioned themselves. Maybe a problem of these synthetic benchmarks compared to real world usage as Ourasi mentioned?
Here is from the forum..
http://www.xtremesystems.org/forums/showthread.php...
Something Ourasi said
"At the moment I'm on 16kb stripe, and have been for a while now, and it is blisteringly fast in real world, not only in benches. There is not much performance difference between 16kb - 32kb - 64kb, but the smaller sizes edges ahead. As long as there is no measurable negative impact using these small stripes, I will continue using them. The X25-M is a perfect companion for those small stripes, some SSD's might not be. Intel was right about this in my opinion. But I must add: This is with my ICH9R, and I fully understand that these stripes might perform pretty bad on some controllers, and that's why I encourage people to test for them selves..."
Response to his comment
"There are like 10 times more people saying that their testing showed 128 or more to be the best. Who do you think tested properly? Things like this will never be 100% one sided. "
What bothered me was this comment later which had me ask you the question earlier..
"Most SSD's have a native block size of 32KB when erasing. Some have 64KB. This is the space that has to be trimmed or "re-zeroed" before a write. If you write 1,024KB to a RAID-0 pair with 64KB blocks, with a 32KB stripe size, it will be 32 writes, requiring 64 erases. With 128KB stripes, it will be 32 writes, 32 erases. You'll effectively see a 30-50% difference in writes. This does not affect reads quite as much, but it's still usually double-digits. Also, with double the erase cycles, you will cut the lifespan of the drive in half."
I am interested in testing some stripe sizes now.. but i think i will use something more real world. Do you think Vantage HDD would be good test for stripe sizes since it uses real world applications. I dont like the synthetic benches
GullLars - Friday, April 2, 2010 - link
Regarding the "Most SSD's have a native block size of 32KB when erasing......" quote, this is purely false.Most SSDs have 4KB pages and 512KB erase-blocks. Anyways, as long as you have LBA->Physical block abstraction, dynamic wear leveling, and garbage collection, you can forget about erase-blocks and only think of pages.
This is true for Intels SSDs, and most newer SSD (2009 and newer).
These SSDs have "pools" of pre-erased blocks wich are written to, so you don't have to erase evertime you write. The garbage collection is responsible for cleaning dirty or partially dirty erase-blocks and combine them to pure valid blocks in new locations, and the old blocks then enter the "clean" pool.
Most SSDs are capable of writing faster than their garbage collection can clean, and therefore you get a lower "sustained" write speed than the max speed, it will however return back to max when the GC has had some time to replenish the clean pool. Some SSDs will sacrafice write amplification (by using more aggressive GC) to increase sustained sequential write.
Intel on the other hand has focused on maximizing the random write performance in a way that also minimizes write amplification, and this either means high temporary and really low sustained write, or like intel has done, fairly low sequential write that does not degrade much. (this has to do with write placement, wear leveling, and garbage collection)
This technique is what allows the x25-V to have random write equal to sequential write (or close to. 40MB/s random write, 45MB/s sequential write). x25-M could probably also get a random:seq write ratio close to 1:1, but the controller doesn't have enough computational power to deliver that high random write using intels technique.
WC Annihilus - Friday, April 2, 2010 - link
I've done some testing on stripe sizes with the 3x X25-V's found in this thread:http://www.xtremesystems.org/forums/showthread.php...
I have done 128k, 32k, and 16k so far. By the looks of it, 16k and 32k are neck and neck. 64k results will be going up in a couple hours.