NVIDIA’s GeForce GTX 480 and GTX 470: 6 Months Late, Was It Worth the Wait?
by Ryan Smith on March 26, 2010 7:00 PM EST- Posted in
- GPUs
Compute
Update 3/30/2010: After hearing word after the launch that NVIDIA has artificially capped the GTX 400 series' double precision (FP64) performance, we asked NVIDIA for confirmation. NVIDIA has confirmed it - the GTX 400 series' FP64 performance is capped at 1/8th (12.5%) of its FP32 performance, as opposed to what the hardware natively can do of 1/2 (50%) FP32. This is a market segmentation choice - Tesla of course will not be handicapped in this manner. All of our compute benchmarks are FP32 based, so they remain unaffected by this cap.
Continuing at our look at compute performance, we’re moving on to more generalized compute tasks. GPGPU has long been heralded as the next big thing for GPUs, as in the right hands at the right task they will be much faster than a CPU would be. Fermi in turn is a serious bet on GPGPU/HPC use of the GPU, as a number of architectural tweaks went in to Fermi to get the most out of it as a compute platform. The GTX 480 in turn may be targeted as a gaming product, but it has the capability to be a GPGPU powerhouse when given the right task.
The downside to GPGPU use however is that a great deal of GPGPU applications are specialized number-crunching programs for business use. The consumer side of GPGPU continues to be underrepresented, both due to a lack of obvious, high-profile tasks that would be well-suited for GPGPU use, and due to fragmentation in the marketplace due to competing APIs. OpenCL and DirectCompute will slowly solve the API issue, but there is still the matter of getting consumer orientated GPGPU applications out in the first place.
With the introduction of OpenCL last year, we were hoping by the time Fermi was launched that we would see some suitable consumer applications that would help us evaluate the compute capabilities of both AMD and NVIDIA’s cards. That has yet to come to pass, so at this point we’re basically left with synthetic benchmarks for doing cross-GPU comparisons. With that in mind we’ve run a couple of different things, but the results should be taken with a grain of salt as they don’t represent any single truth about compute performance on NVIDIA or AMD’s cards.
Out of our two OpenCL benchmarks, we’ll start with an OpenCL implementation of an N-Queens solver from PCChen of Beyond3D. This benchmark uses OpenCL to find the number of solutions for the N-Queens problem for a board of a given size, with a time measured in seconds. For this test we use a 17x17 board, and measure the time it takes to generate all of the solutions.
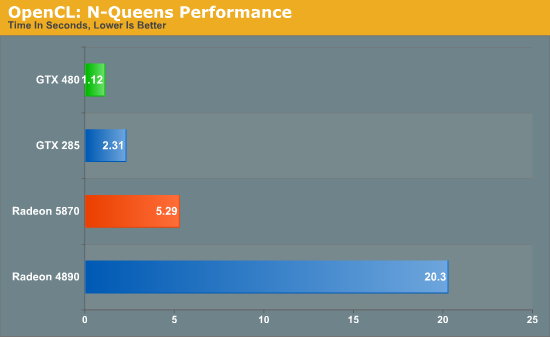
This benchmark offers a distinct advantage to NVIDIA GPUs, with the GTX cards not only beating their AMD counterparts, but the GTX 285 also beating the Radeon 5870. Due to the significant underlying differences of AMD and NVIDIA’s shaders, even with a common API like OpenCL the nature of the algorithm still plays a big part in the performance of the resulting code, so that may be what we’re seeing here. In any case, the GTX 480 is the fastest of the GPUs by far, beating out the GTX 285 by over half the time, and coming in nearly 5 times faster than the Radeon 5870.
Our second OpenCL benchmark is a post-processing benchmark from the GPU Caps Viewer utility. Here a torus is drawn using OpenGL, and then an OpenCL shader is used to apply post-processing to the image. Here we measure the framerate of the process.

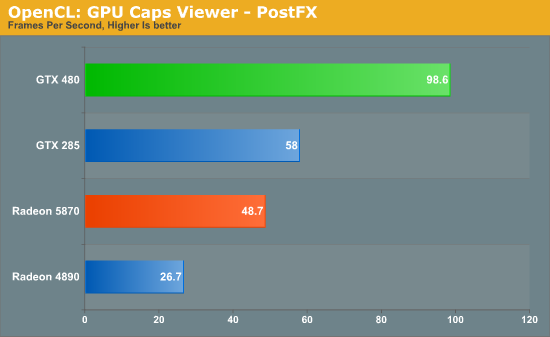
Once again the NVIDIA cards do exceptionally well here. The GTX 480 is the clear winner, while even the GTX 285 beats out both Radeon cards. This could once again be the nature of the algorithm, or it could be that the GeForce cards really are that much better at OpenCL processing. These results are going to be worth keeping in mind as real OpenCL applications eventually start arriving.
Moving on from cross-GPU benchmarks, we turn our attention to CUDA benchmarks. Better established than OpenCL, CUDA has several real GPGPU applications, with the limit being that we can’t bring the Radeons in to the fold here. So we can see how much faster the GTX 480 is over the GTX 285, but not how this compares to AMD’s cards.
We’ll start with Badaboom, Elemental Technologies’ GPU-accelerated video encoder for CUDA. Here we are encoding a 2 minute 1080i clip and measuring the framerate of the encoding process.
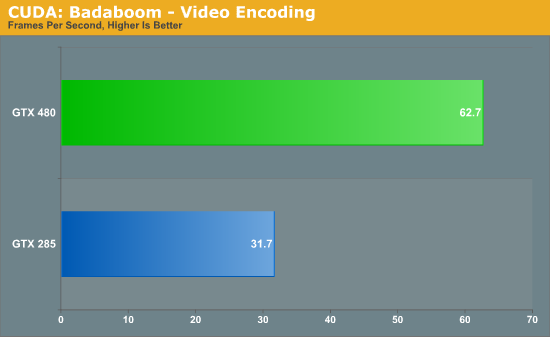
The performance difference with Badaboom is rather straightforward. We have twice the shaders running at similar clockspeeds, and as a result we get twice the performance. The GTX 480 encodes our test clip in a little over half the time it took the GTX 280.
Up next is a special benchmark version of Folding@Home that has added Fermi compatibility. Folding@Home is a Standford research project that simulates protein folding in order to better understand how misfolded proteins lead to diseases. It has been a poster child of GPGPU use, having been made available on GPUs as early as 2006 as a Close-To-Metal application for AMD’s X1K series of GPUs. Here we’re measuring the time it takes to fully process a sample work unit so that we can project how many nodes (units of work) a GPU could complete per day when running Folding@Home.
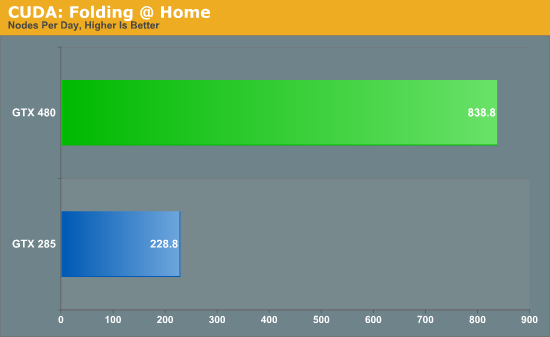
Folding@Home is the first benchmark we’ve seen that really showcases the compute potential for Fermi. Unlike everything else which has the GTX 480 running twice as fast as the GTX 285, the GTX 480 is a fewtimes faster than the GTX 285 when it comes to folding. Here a GTX 480 would get roughly 3.5x as much work done per day as a GTX 285. And while this is admittedly more of a business/science application than it is a home user application (even if it’s home users running it), it gives us a glance at what Fermi is capable when it comes to compuete.
Last, but not least for our look at compute, we have another tech demo from NVIDIA. This one is called Design Garage, and it’s a ray tracing tech demo that we first saw at CES. Ray tracing has come in to popularity as of late thanks in large part to Intel, who has been pushing the concept both as part of their CPU showcases and as part of their Larrabee project.
In turn, Design Garage is a GPU-powered ray tracing demo, which uses ray tracing to draw and illuminate a variety of cars. If you’ve never seen ray tracing before it looks quite good, but it’s also quite resource intensive. Even with a GTX 480, with the high quality rendering mode we only get a couple of frames per second.
On a competitive note, it’s interesting to see NVIDIA try to go after ray tracing since that has been Intel’s thing. Certainly they don’t want to let Intel run around unchecked in case ray tracing and Larrabee do take off, but at the same time it’s rasterization and not ray tracing that is Intel’s weak spot. At this point in time it wouldn’t necessarily be a good thing for NVIDIA if ray tracing suddenly took off.
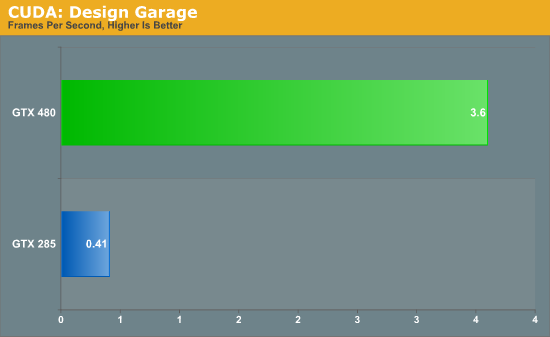
Much like the Folding@Home demo, this is one of the best compute demos for Fermi. Compared to our GTX 285, the GTX 480 is eight times faster at the task. A lot of this comes down to Fermi’s redesigned cache, as ray tracing as a high rate of cache hits which help to avoid hitting up the GPU’s main memory any more than necessary. Programs that benefit from Fermi’s optimizations to cache, concurrency, and fast task switching apparently stand to gain the most in the move from GT200 to Fermi.








196 Comments
View All Comments
Ryan Smith - Wednesday, March 31, 2010 - link
My master copies are labeled the same, but after looking at the pictures I agree with you; something must have gotten switched. I'll go flip things. Thanks.Wesgoood - Wednesday, March 31, 2010 - link
Correction, Nvidia retained their crown on Anandtech. Even though some resolutions even on here were favored to ATI(mostly the higher ones). On Toms Hardware 5870 pretty much beat GTX 480 from 1900x1200 to 2560x1600, not every time in 1900 but pretty much every single time in 2560.That ...is where the crown is, in the best of the best situations, not ....OMG it beat it in 1680 ...THAT HAS TO BE THE BEST!
Plus the power hungry state of this card is just appauling. Nvidia have shown they can't compete with proper technology, rather having to just cram everything they can onto a chip and prey it works right.
Where as ATI's GPU is designed perfectly to where they have plenty of room to almost double the size of the 5870.
efeman - Wednesday, March 31, 2010 - link
I copied this over from a comment I made on a blog post.I've been with nVidia for the past decade. My brother built his desktop way back when with the Ti 4200, I bought a prefab with a 5950 ultra, my last budget build had an 8600 GTS in it, and I upgraded to the GTX 275 last year. I am in no way a fanboy, nVidia just has treated me very well. If I had made that last decision a few months later after the price hike, it would've definitely been the HD 4890; almost identical performance for ballpark $100 less.
I recently built a new high-end rig (Core i7 and all), but I waited out on dropping the money on a 5800 series card. I knew nVidia's new cards were on the way, and I was excited and willing to wait it out; I expected a lot out of them.
Now that they're are out in the open, I have to say I'm a little shaken. In many cases, the performance of the cards are not where I would've hoped they be (the general consensus seems to be 5-10% increase in performance over their ATI counterparts; I see that failing in many cases, however). It seems like the effort that nVidia put into the cards gave them lots of potential, but most of it is wasted.
"The future of PC gaming" is right in the title of this post, and that's what these cards have been built for. Nvidia has a strong lead over ATI in compute and tessellation performance now, that's obvious; however, that will only provide useful if and when developers decide to put the extra effort into taking advantage of those technologies. Nvidia is gambling right now; it has already given ATI a half-year lead on the DX11 market, and it's pushing cards that won't be fully utilized until who-knows-when (there's no telling when these technologies will be more widely integrated into the gaming market). What will it do in the meantime? ATI is already on it's way to producing its 5000-series refresh; and this time it knows the competition's performance.
I was hoping for the GTX 400s to do the same thing that the GTX 200s did: give nVidia back the high-end performance throne. ATI is not only competitive with it's counterparts, but it still has the 5970 for the enthusiast performance crown (don't forget Eyefinity!). I think nVidia made a mistake in putting so much focus into compute and tessellation performance; it would've been smarter to produce cards with similar die sizes (crappy wafer yields, anyone?), faster raw performance with tessellation/compute as a secondary objective, and more competitive pricing. It wouldn't have been a bad option to create a separate chip for the Tesla cards, one that focused on the compute performance while the GeForce cards focused on the rest.
I still have faith. Maybe nVidia will work wonders with the drivers and producing performance we were waiting for. Maybe it has something awesome brewing deep within its labs. Or maybe my fears will embody themselves, and nVidia is crossing its fingers and hoping for its tessellation/compute performance to give it the market share later on. If so, ATI will provide me with my pair of cards.
That was quite the rant; I wasn't planning on writing that much when I decided to comment on Drew Henry's (nVidia GM) blog post. I suppose I'm passionate about this sort of thing, and I really hope nVidia doesn't lose me after all this time.
Kevinmbaron - Wednesday, March 31, 2010 - link
The fact that this card comes out a year and a 1/2 after the the GTX 295 makes me sick. Add to that the fact that the GTX 295 actually is faster then the GTX 480 in a few benchmarks and very close in others is like a bad dream for nvidia. Forget if they can beat AMD, they can't even beat themselves. They could have did a die shrink on the GTX 295, add some more shadders and double the memory and had that card out a year ago and it would have crushed anything on the market. Instead they risked it all on a hair brained new card. I am a GTX 295 owner. Apperently my card is a all arround better card being it doesnt lag in some games like the 480 does. I guess i will stick with my old GTX 295 for another year. Maybe then there might be a card worth buying. Even the ATI 5970 doesn't have enough juice to justify a new purchase from me. This should be considered horrible news for Nvidia. They should be ashammed of themselves and the CEO should be asked to step down.ol1bit - Thursday, April 1, 2010 - link
I just snagged a 5870 gen 2 I think (XFX) from NewEgg.They have been hard to find in stock, and they are out again.
I think many were waiting to see if the GF100 was a cruel joke or not. I am sorry for Nivida, but love the completion. I hope Nvidia will survive.
I'll bet they are burning the midnight oil for gen 2 of the GF100.
bala_gamer - Friday, April 2, 2010 - link
Did you guys recieve the GTX480 earlier than other reviewers? There were 17 cards tested on 3 drivers and i am assuming tests were done multiple times per game to get an average. installing, reinstalling drivers, etc 10.3 catalyst drivers came out week of march 18.Do you guys have multiple computers benchmarking at the same time? I just cannot imagine how the tests were all done within the time frame.
Ryan Smith - Sunday, April 4, 2010 - link
Our cards arrived on Friday the 19th, and in reality we didn't start real benchmarking until Saturday. So all of that was done in roughly a 5 day span. In true AnandTech tradition, there wasn't much sleep to be had that week. ;-)mrbig1225 - Tuesday, April 6, 2010 - link
I felt compelled to say a few things about nvidia’s Fermi (480/470 GTX). I like to always start out by saying…let’s take the fanboyism out of the equation and look at the facts. I am a huge nvidia fan, however they dropped the ball big time. They are selling people on ONE aspect of DX11 (tessellation) and that’s really the only thing there cards does well but it’s not an efficient design. What people aren’t looking at is that their tessellation is done by the polymorh engine which ties directly into the cuda cores, meaning the more cuda cores occupied by shaders processing…etc the less tessellation performance and vice versa = less frames per sec. As you noticed we see tons of tessellation benchmarks that show the gtx 480 is substantially faster at tessellation, I agree when the conditions suite that type of architecture (and there isn’t a lot of other things going on). We know that the gf100(480/470gtx) is a computing beast, but I don’t believe that will equate to overall gaming performance. The facts are this gpu is huge (3billion + transistors), creates a boat load of heat, and sucks up more power than any of the latest dual gpu cards (295gtx, 5970) came to market 6 months late and is only faster than its single gpu competition by 10-15% and some of us are happy? Oh that’s right it will be faster in the future when dx11 is relevant…I don’t think so for a few reasons but ill name two. If you look at the current crop of dx11 games, the benchmarks and actual dx11 game benchmarks (shaders and tessellation…etc) shows something completely different. I think if tessellation was nvidia’s trump card in games then basically the 5800 series would be beat substantially in any dx11 title with tessellation turned on…we aren’t seeing that(we are seeing the opposite in some circumstances), I don’t think we will. I also am fully aware that tessellation is scalable, but that brings me to another point. I know many of you will say that it is only in extreme tessellation environments that we really start to see the nvidias card take off. Well if you agree with that statement then you will see that nvidia has another issue. The 1st is the way they implement tessellation in their cards (not very scalable imo) 2nd is, the video card industry sales are not comprised of high end gpus, but the cheaper mainstream ones. Since nvidia polymorph engine is tied directly to its shaders…u kinda see where this is going, basicly less powerful cards will be bottlenecked by their lack of shaders for tessellation and vice versa. Developers want to make money, the way they make money is selling lots of games, example crysis was a big game, however it didn’t break any records sales…truth of the matter is most people systems couldn’t run crysis. Now you look at valve software and a lot of their titles sale well because of how friendly it is to mainstream gpus(not the only thing but it does help). The hardware has to be there to support a large # of game sales, meaning that if the majority of parts cannot do extreme levels of tessellation then you will find few games to implement it. Food for thought… can anyone show me a dx11 title that the gtx480 handily beats the 5870 by the same amount that it does in the heaven benchmark or even close to that. I think as a few of you have said, it will come down to what game work better with what architecture..some will benefit nvidia(Farcry2..good example) others Ati (Stalker)…I think that is what we are seeing now. IMOP.S. I think also why people are pissed is because this card was stated to be 60% faster than the 5870. As u can see its not!!
houkouonchi - Thursday, April 8, 2010 - link
Why the hell are the screenshots showing off the AA results in a lossy JPEG format instead of PNG like pretty much anything else?dzmcm - Monday, April 12, 2010 - link
I'm not familiar with Battleforge firsthand, but I understood it uses HD Ambient Occlusion wich is a variation of Screen Space Ambient Occlusion that includes normal maps. And since it's inception in Crysis SSAO has stood for Screen Space AO. So why is it called Self Shadow AO in this article?Bit-tech refers to Stalker:CoP's SSAO as "Soft Shadow." That I'm willing to dismiss. But I think they're wrong.
Am I'm falling behind with my jargon, or are you guys not bothering to keep up?