10Gbit Ethernet: Killing Another Bottleneck?
by Johan De Gelas on March 8, 2010 12:00 PM EST- Posted in
- IT Computing
In the second quarter of this year, we’ll have affordable servers with up to 48 cores (AMD’s Magny-cours) and 64 threads (Intel Nehalem EX). The most obvious way to wield all that power is to consolidate massive amounts of virtual machines on those powerhouses. Typically, we’ll probably see something like 20 to 50 VMs on such machines. Port aggregation with a quad-port gigabit Ethernet card is probably not going to suffice. If we have 40 VMs on a quad-port Ethernet, that is less than 100Mbit/s per VM. We are back in the early Fast Ethernet days. Until virtualization took over, our network intensive applications would get a gigabit pipe; now we will be offering them 10 times less? This is not acceptable.
Granted, few applications actually need a full 1Gbit/s pipe. Database servers need considerably less, only a few megabits per second. Even at full load, the servers in our database tests rarely go beyond 10Mbit/s. Web servers are typically satisfied with a few tens of Mbit/s, but AnandTech's own web server is frequently bottlenecked by its 100Mbit connection. Fileservers can completely saturate Gbit links. Our own fileserver in the Sizing Servers Lab is routinely transmitting 120MB/s (a saturated 1Gbit/s link). The faster the fileserver is, the shorter the waiting time to deploy images and install additional software. So if we want to consolidate these kinds of workloads on the newest “über machines”, we need something better than one or two gigabit connections for 40 applications.
Optical 10Gbit Ethernet – 10GBase-SR/LR - saw the light of day in 2002. Similar to optical fibre channel in the storage world, it was very expensive technology. Somewhat more affordable, 10G on “Infiniband-ish” copper cable (10GBase-CX4) was born in 2004. In 2006, 10Gbit Ethernet via UTP cable (10GBase-T) held the promise that 10G Ethernet would become available on copper UTP cables. That promise has still not materialized in 2010; CX4 is by far the most popular copper based 10G Ethernet. The reason is that the 10GBase-T PHYs need too much power. The early 10GBase-T solutions needed up to 15W per port! Compare this to the 0.5W that a typical gigabit port needs, and you'll understand why you find so few 10GBase-T ports in servers. Broadcom reported a breakthrough just a few weeks ago: Broadcom claims that their newest 40nm PHYs use less than 4W per port. Still, it will take a while before the 10GBase-T conquers the world, as this kind of state-of-the art technology needs some time to mature.
We decided to check out the some of the more mature CX4-based solutions as they are decently priced and require less power. For example, a dual-port CX4 card goes as low as 6W… that is 6W for the controller, two ports and the rest of the card. So a complete dual-port NIC needs considerably less than one of the early 10GBase-T ports. But back to our virtualized server: can 10Gbit Ethernet offer something that the current popular quad-port gigabit NICs can’t?
Adapting the network layers for virtualization
When lots of VMs are hitting the same NIC, quite a few performance problems may arise. First, one network intensive VM may completely fill up the transmit queues and block the access to the controller for some time. This will increase the network latency that the other VMs see. The hypervisor has to emulate a network switch that sorts and routes the different packets of the various active VMs. Such an emulated switch costs quite a bit of processor performance, and this emulation and other network calculations might all be running on one core. In that case, the performance of this one core might limit your network bandwidth and raise network latency. That is not all, as moving data around without being able to use DMA means that the CPU has to handle all memory move/copy actions too. In a nutshell, a NIC with one transmit/receive queue and a software emulated switch is not an ideal combination if you want to run lots of network intensive VMs: it will reduce the effective bandwidth, raise the NIC latency and increase the CPU load significantly.
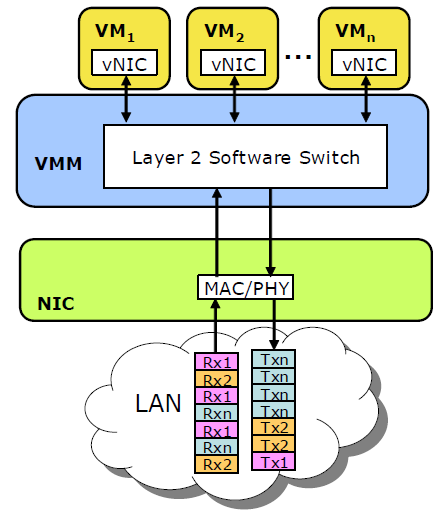
Several companies have solved this I/O bottleneck by making use of the multiple queues". Intel calls it VMDq; Neterion calls it IOV. A single NIC controller is equipped with different queues. Each receive queue can be assigned to a virtual NIC of your VM and mapped to the guest memory of your VM. Interrupts are load balanced across several cores, avoiding the problem that one CPU is completely overwhelmed by the interrupts of tens of VMs.
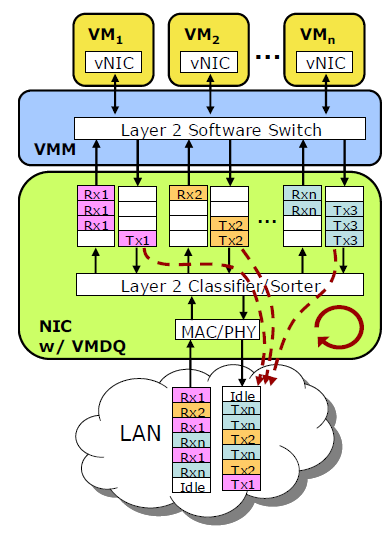
When packets arrive at the controller, the NIC’s Layer 2 classifier/sorter sorts the packets and places them (based on the virtual MAC addresses) in the queue assigned to a certain VM. Layer 2 routing is thus done in hardware and not in software anymore. The hypervisor looks in the right queue and then routes those packets towards the right VM. Packets that have to go out of your physical server are placed in the transmit queues of each VM. In the ideal situation, each VM has its own queue. Packets are sent to the physical wire in a round-robin fashion.
The hypervisor has to support this and your NIC vendor must of course have an “SR-IOV” capable driver for the hypervisor. VMware ESX 3.5 and 4.0 have support for VMDq and similar technologies, calling it “NetQueue”. Microsoft Windows 2008 R2 supports this too, under the name “VMQ”.








49 Comments
View All Comments
RequiemsAllure - Tuesday, March 9, 2010 - link
So, basically what these cards are doing (figuratively speaking) they are taking in"multiplexing" 8 or 16 requests (how however many virtual queues) together into a single NIC sorting (demultiplexing) them to a respective VM the VM then takes care of the request and sends it on its way.can anyone tell me if i got this right?
has407 - Wednesday, March 10, 2010 - link
Yes, I think you've got it... that's pretty much how it works. At the risk of oversimplifying... these cards are like a multi-port switch with 10Gbe uplinks.Consider a physical analog (depending on the card, and not exact but close enough): 8/16x 1Gbe ports on the server connected to a switch with 8/16x 1Gbe ports and 1/2x 10Gbe uplinks to the backbone.
Now replace that with a card on the server and 1/2x 10Gbe backbone ports. Port/switch/cable consolidation ratios of 8:1 or 16:1 can save serious $$$ (and with better/dynamic bandwidth allocation).
The typical sticking point is that 10Gbe switches/routers are still quite expensive, and unless you've got a critical mass of 10Gbe, the infrastructure cost can be a tough hump to get over.
LuxZg - Tuesday, March 9, 2010 - link
I've got to admit that I've skimped through the article (and first page ad a half of commnts).. But it seems through your testing & numbers that you haven't used a dedicated NIC for every card in the 4x 1Gbit example (4 VMs test), otherwise you'd get lower CPU numbers simly because you skip on the load scheduling that's done on CPU.Any "VM expert" will tell you that you have 3 basic bottlenecks in any VM server:
- RAM (the more the better, mostly not a problem)
- disks (again, more is better, and absolutele minimum is at least one drive per VM)
- NICs
For NICs basic rule would be - if VM is loaded with network-heavy application, than VM should have a dedicated NIC. CPU utilization drops heavily, and NIC utilization is higher.
Having one 10Gbit NIC shared among 8 VMs which are all bottlenecked by NICs means you have your 35% CPU load. With one NIC dedicated to each VM you'd have CPU load near zero at file-copy loads (NIC has hardware scheduler, disc controller has the same for HDDs).
Like I've said, maybe I've overlooked something in article, but it seems to me your test are based on wrong assumptions. Besides, if you've got 8 file servers as VM, you've got an unnecessary overhead as well, it's one application (file serving) so no need to virtualize to 8 VMs on same hardware.
As a conclusion, VMs are all about planning, so I believe your test had a wrong approach.
JohanAnandtech - Tuesday, March 9, 2010 - link
"a dedicated NIC for every VM"That might be the right approach when you have a few VMs on the server, but it does not seem to be reasonable when you have tens of VMs running. What do you mean by dedicating? pass-through? port grouping? Only Pass-through has near zero CPU load AFAIK, and I don't see many scenarios where pass-through is handy.
Also, if you use dedicated NICs for network intensive apps, that means that you can not use that bandwidth for the occasional spike in another "non NIC priviledged" VM.
It might not be feasible at all if you use DRS or Live migration.
The whole point of VMDQ is to offer the bandwidth necessary to the VM that needs it (for example give one VM 5 GBit/s, One VM 1 gbit/s and the others only 1 Mbit/s) and that the layer 2 routing overhead is mostly on the NIC. It seems to me that the planning you promote is very inflexible and I can see several scenario's where dedicated NICs will perform worse than one big pipe which can be load balanced accross the different VMs.
LuxZg - Wednesday, March 10, 2010 - link
Yes, I meant "dedicated" as "pass-through".Yes, there are several scenarios where "one big" is better than several small ones, but think if 35% CPU load (and that's 35% of a very-expensive-CPU) is worth as sacrifice to have a reserve for few occasional spikes.
I do agree that putting several VMs on one NIC is ok, but that's for applications that aren't loaded with heavy network transfers. VM load balancing should be done for example like this (just a stupid example, don't hold onto it too hard):
- you have file server as one VM
- you have mail server on second VM
- you have some CPU-heavy app on separate VM
File server is heavy on networking and disc subsystem, but almost none on RAM/CPU. Mail server is dependant on several variables (antiSPAM, antivirus, amount of mailboxes & incoming mail, etc), so it can be light-to-heavy load for all subsystems. For this example let's say it's a lighter kind of load. Let's say this hardware machine has 2 NICs. You've got few CPUs with multiple cores, and plenty of disc/RAM. So what's right to do? Adding a CPU intensive VM, so that CPU isn't idle too much. You dedicate one NIC to file server, and you let mail server share NIC with CPU-intensive VM. That way file server has enough bandwidth that isn't taxing CPU to 35% cos of stupid virtual routing of great amounts of network packets, CPU is left mostly free for the CPU-intensive VM, and mail server happily lives in between the two, as it will be satisfied with leftover CPU and networking..
Now scale that to 20-30 VMs, and all you need is 10 NICs. For VMs that aren't network dependant you put them on "shared NICs", and for network-intensive apps you give those VMs dedicated NIC.
Just remember - 35% of a multi-socket & multi-core server is a huge expense, when you can do it on a dedicated NIC. NIC is, was, and will be much more cost effective for doing network packet scheduling than CPU.. Why pay several thousand $$$ for CPU if all you need is another NIC.
LuxZg - Tuesday, March 9, 2010 - link
I hate my own typos.. 2nd sentence.. "dedicated NIC for every VM" .. not "for every card".. probably there are more nonsense.. I'm in a hurry, sorry ppl!anakha32 - Tuesday, March 9, 2010 - link
All the new 10G kit appears to be coming with SFP+ connectors. They can be used either with a transceiver for optical, or a pre-terminated copper cable (known as 'SFP+ Direct Attach').CX4 seems to be deprecated as the cables are quite big and cumbersome.
zypresse - Tuesday, March 9, 2010 - link
I've seen some mini-Clusters (3-10 machines) lately with ethernet interconnects. Although I doubt that this is best solution, it would be nice to know how 10G ethernet actually performs in that area.Calin - Tuesday, March 9, 2010 - link
I don't find a power use of <10W for a 10Gb link such a bad compromise over 0.5W per 1Gb Ethernet link (assuming that you can use that 10Gb link at close to maximum capacity). If nothing else, you're trading two 4-port 1Gb network cards for one 10Gb card.MGSsancho - Tuesday, March 9, 2010 - link
Suns 40BGs adapters are not terribly expensive (start at $1500.) apparently they support 8 virtual lanes? So Mellanox provides Sun their silicon. went to their site and they do have other silicon/cards that explicitly state they support Virtual Protocol Interconnect. I'm curious if this is the same thing. I know you stated that the need really isn't there but would be interesting to see if you can ask for testing samples or look into the viability of Infiniband. Looking at their partners page they provide the silicon for xsigo as a previous poster stated. Again would be nice to see if 40Gb Infiniband with and without VPI technologies is superior to 10Gb Ethernet with acceleration as you provided with us today. For SANs, anything to lower latency for iscsi is desired. Perhaps spending a little for reduced latency on the network layer makes it worth the extra price for faster transactions? So many possibilities! Thank you for all the insightful research you have provided us!