OCZ's Vertex 2 Pro Preview: The Fastest MLC SSD We've Ever Tested
by Anand Lal Shimpi on December 31, 2009 12:00 AM EST- Posted in
- Storage
AnandTech Storage Bench
I introduced our storage suite in our last SSD article and it’s back, now with more data :)
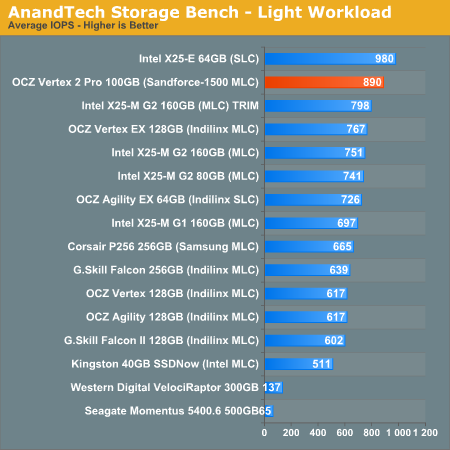
Of the MLC SSDs represented here, there’s just nothing faster than the SandForce based OCZ Vertex 2 Pro.
Intel’s SLC based X25-E actually does very well, especially for a controller that’s as old as it is. It is worth noting however that the only thing separating Intel from SandForce-level performance is the X25-M’s low sequential write speed...
The first in our benchmark suite is a light usage case. The Windows 7 system is loaded with Firefox, Office 2007 and Adobe Reader among other applications. With Firefox we browse web pages like Facebook, AnandTech, Digg and other sites. Outlook is also running and we use it to check emails, create and send a message with a PDF attachment. Adobe Reader is used to view some PDFs. Excel 2007 is used to create a spreadsheet, graphs and save the document. The same goes for Word 2007. We open and step through a presentation in PowerPoint 2007 received as an email attachment before saving it to the desktop. Finally we watch a bit of a Firefly episode in Windows Media Player 11.
There’s some level of multitasking going on here but it’s not unreasonable by any means. Generally the application tasks proceed linearly, with the exception of things like web browsing which may happen in between one of the other tasks.
The recording is played back on all of our drives here today. Remember that we’re isolating disk performance, all we’re doing is playing back every single disk access that happened in that ~5 minute period of usage. The light workload is composed of 37,501 reads and 20,268 writes. Over 30% of the IOs are 4KB, 11% are 16KB, 22% are 32KB and approximately 13% are 64KB in size. Less than 30% of the operations are absolutely sequential in nature. Average queue depth is 6.09 IOs.
The performance results are reported in average I/O Operations per Second (IOPS):
If there’s a light usage case there’s bound to be a heavy one. In this test we have Microsoft Security Essentials running in the background with real time virus scanning enabled. We also perform a quick scan in the middle of the test. Firefox, Outlook, Excel, Word and Powerpoint are all used the same as they were in the light test. We add Photoshop CS4 to the mix, opening a bunch of 12MP images, editing them, then saving them as highly compressed JPGs for web publishing. Windows 7’s picture viewer is used to view a bunch of pictures on the hard drive. We use 7-zip to create and extract .7z archives. Downloading is also prominently featured in our heavy test; we download large files from the Internet during portions of the benchmark, as well as use uTorrent to grab a couple of torrents. Some of the applications in use are installed during the benchmark, Windows updates are also installed. Towards the end of the test we launch World of Warcraft, play for a few minutes, then delete the folder. This test also takes into account all of the disk accesses that happen while the OS is booting.
The benchmark is 22 minutes long and it consists of 128,895 read operations and 72,411 write operations. Roughly 44% of all IOs were sequential. Approximately 30% of all accesses were 4KB in size, 12% were 16KB in size, 14% were 32KB and 20% were 64KB. Average queue depth was 3.59.

Our final test focuses on actual gameplay in four 3D games: World of Warcraft, Batman: Arkham Asylum, FarCry 2 and Risen, in that order. The games are launched and played, altogether for a total of just under 30 minutes. The benchmark measures game load time, level load time, disk accesses from save games and normal data streaming during gameplay.
The gaming workload is made up of 75,206 read operations and only 4,592 write operations. Only 20% of the accesses are 4KB in size, nearly 40% are 64KB and 20% are 32KB. A whopping 69% of the IOs are sequential, meaning this is predominantly a sequential read benchmark. The average queue depth is 7.76 IOs.









100 Comments
View All Comments
Holly - Friday, January 1, 2010 - link
Hmm, I thought MLC/SLC is more the matter of SSD controller than memory chip itself? Anybody could throw a bit light pls?bji - Friday, January 1, 2010 - link
MLC and SLC are two different types of flash chips. You can find out more at:http://en.wikipedia.org/wiki/MLC_flash">http://en.wikipedia.org/wiki/MLC_flash
http://en.wikipedia.org/wiki/Single-level_cell">http://en.wikipedia.org/wiki/Single-level_cell
Holly - Friday, January 1, 2010 - link
well,according to
http://www.anandtech.com/storage/showdoc.aspx?i=34...">http://www.anandtech.com/storage/showdoc.aspx?i=34...
they are not nescessary the same chips... the transistors are very much the same and it's more or less matter of how you interpret the voltages
quote:
Intel actually uses the same transistors for its SLC and MLC flash, the difference is how you read/write the two.
shawkie - Friday, January 1, 2010 - link
Call me cynical but I'd be very suspicious of benchmark results from this controller. How can you be sure that the write amplification during the benchmark resembles that during real world use? If you write completely random data to the disk then surely its impossible to achieve a write amplification of less than 1.0? I would have thought that home users would be mostly storing compressed images, audio and video which must be pretty close to random. I'd also be interested to know if the deduplication/compression is helping them to increase to the effective reserved space. That would go a long way to mask read-modify-write latency issues but again, what happens if the data on the disk can't be deduplicated/compressed?Swivelguy2 - Friday, January 1, 2010 - link
On the contrary - if you write random data, some (probably lots) of that data will be duplicated on successive writes simply by random chance.When you write already-compressed data, an algorithm has already looked at that data and processed it in a way that makes sure there's very little duplication of data.
Holly - Friday, January 1, 2010 - link
It's always matter of used compression algorithm. There are algorithms that are able to press whole avi movie (= already compressed) to few megabytes. Problem with these algoritms is they are so demanding it takes days even for neuron network to compress and decompress. We had one "very simple" compression algorithm in graphs theory classes.. honestly I got ultimately lost after first read paragraph (out of like 30 pages).So depending on algorithms used you can compress already compressed data. You can take your bitmap, run it through Run Length Encoding, then run it through Huffman encoding and finish with some dictionary based encoding... In most cases you'll compress your data a bit more every time.
There is no chance to tell how this new technology handles it's task in the end. Not until it is ran with Petabytes of data.
bji - Friday, January 1, 2010 - link
Please don't use an authoritative tone when you actually don't know much about the subject. You are likely to confuse readers who believe that what you write is factual.The compression of movies that you were talking about is a lossy compression and would never, ever be suitable in any way for compressing data internally within an SSD.
Run Length Encoding requires knowledge of the internal structure of the data being stored, and an SSD is an agnostic device that knows nothing about the data itself, so that's out.
Huffman encoding (or derivitives thereof) is universally used in pretty much every compression algorithm, so it's pretty much a given that this is a component of whatever compression SandForce is using. Also, dictionary based encoding is once again only relevent when you are dealing with data of a generally restricted form, not for data which you know nothing about, so it's out; and even if it were used, it would be used before Huffman encoding, not after it as you suggested.
I think your basic point is that many different individual compression technologies can be combined (typically by being applied successively); but that's already very much de riguer in compression, with every modern compression algorithm I am familiar with already combining several techniques to produce whatever combination of speed and effective compression ratios is desired. And every compression algorithm has certain types of data that it works better on, and certain types of data that it works worse on, than other algorithms.
I am skeptical about SandForce's technology; if it relies on compression then it is likely to perform quite poorly in certain circumstances (as others have pointed out); it reminds me of "web accelerator" snake oil technology that advertised ridiculous speeds out of 56K modems, and which only worked for uncompressed data, and even then, not very well.
Furthermore, this tradeoff of on-board DRAM for extra spare flash seems particularly retarded. Why would you design algorithms that do away with cheap DRAM in favor of expensive flash? You want to use as little flash as possible, because that's the expensive part of an SSD; the DRAM cache is a miniscule part of the total cost of the SSD, so who cares about optimizing that away?
Holly - Friday, January 1, 2010 - link
Well I know quite a bit about the subject, but if you feel offended in any way I am sorry.More I think we got in a bit of misunderstanding.
What I wrote was more or less serie of examples where you could go and compress some already compressed data.
It's quite common knowledge you won't be able to lossless compress well made AVI movie with normally used lossless compression software like ZIP or RAR. But, that is not even a slightest proof there isn't some kind of algorithm that can compress this data to a much smaller volume.
To prove my concept of theory I took the example of bitmap (uncompressed) and then used various lossless compression algorithms. In most cases every time I'd use the algorithm I would get more and more compressed data (well maybe except RLE that could end up with longer result than original file was).
I was not forcing any specific "front end" used algorithms on this controller, because honestly all talks about how (if) it compresses the data is mere speculation. So I went back to origins to keep the idea as simple as possible.
Whole point I was trying to make is there is no way to tell if it saves data traffic on NANDs when you save your file XY on this device simply because there is no knowledge what kind of algorithm is used. We can just guess by trying to compress the file with common algorithms (be it lossless or not) and then try to check if the controller saves NANDs some work or not. OFC, algorithms used on the controller must be lossless and must be stable. But that's about all we can say at this point.
Sorry if I caused some kind of confusion.
What _seems_ to me is that basically there is this difference between X25-M and Vertex 2 Pro logic (taking the 25 vs 11 gigs example used in the article):
System -> 25GB -> X25-M controller -> writes/overwrites -> 25 GB -> NAND flash (but due to overwrites, deletes etc. there is 11GB of data)
compared to Vertex 2 Pro:
System -> 25GB -> SF-1500 controller -> controller logic -> 11 GB -> NAND flash (only 11GB actually written in NAND due to smart controller logic)
sebijisi - Wednesday, January 6, 2010 - link
[quote]It's quite common knowledge you won't be able to lossless compress well made AVI movie with normally used lossless compression software like ZIP or RAR. But, that is not even a slightest proof there isn't some kind of algorithm that can compress this data to a much smaller volume.
[/quote]
Well actually there is. The entropy of the original file bounds the minimum possible size of the compressed file. Same reason you compress first before encrypting something: As the goal of encryption is to generate maximum entropy, encrypted data cannot be compressed further. Not even with some advanced but not yet know algorithm.
shawkie - Friday, January 1, 2010 - link
As long as the data is truly random (i.e. there is no correlation between different bytes) then it cannot be compressed. If you have N bits of data then you have 2^N different values. It is impossible to map all of these different values to less than N bits. If you generate this value randomly its possible you might produce something that can be easily compressed (such as all zeros or all ones) but if you do it enough times you will generate every possible value an equal number of times so on average it will take up at least N bits. Seehttp://www.faqs.org/faqs/compression-faq/part1/sec...">http://www.faqs.org/faqs/compression-faq/part1/sec...
http://en.wikipedia.org/wiki/Lossless_data_compres...">http://en.wikipedia.org/wiki/Lossless_d...on#The_M...
As you note, it is possible to identify already-compressed data and avoid trying to recompress it but this still means you get a write amplification of slightly more than 1.0 for such data.