AMD Core Counts and Bulldozer: Preparing for an APU World
by Anand Lal Shimpi on November 30, 2009 12:00 AM EST- Posted in
- CPUs
Last week Johan posted his thoughts from an server/HPC standpoint on AMD's roadmap. Much of my analysis was limited to desktop/mobile, so if you're making million dollar server decisions then his article is better suited for your needs.
He also unveiled a couple of details about AMD's Bulldozer architecture that I thought I'd call out in greater detail. Johan has been working on a CMP vs. SMT article so I'll try to not step on his toes too much here.
It all started about two weeks ago when I got a request from AMD to have a quick conference call about Bulldozer. I get these sorts of calls for one of two reasons. Either:
1) I did something wrong, or
2) Intel did something wrong.
This time it was the former. I hate when it's the former.
It's called a Module
This is the Bulldozer building block, what AMD is calling a Bulldozer Module:
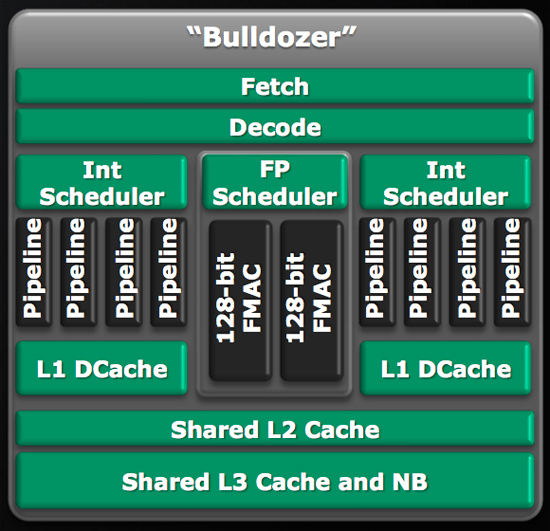
AMD refers to the module as being two tightly coupled cores, which starts the path of confusing terminology. A few of you wondered how AMD was going to be counting cores in the Bulldozer era; I took your question to AMD via email:
Also, just to confirm, when your roadmap refers to 4 bulldozer cores that is four of these cores:
http://images.anandtech.com/reviews/cpu/amd/FAD2009/2/bulldozer.jpg
Or does each one of those cores count as two? I think it's the former but I just wanted to confirm.
AMD responded:
Anand,
Think of each twin Integer core Bulldozer module as a single unit, so correct.
I took that to mean that my assumption was correct and 4 Bulldozer cores meant 4 Bulldozer modules. It turns out there was a miscommunication and I was wrong. Sorry about that :)
Inside the Bulldozer Module
There are two independent integer cores on a single Bulldozer module. Each one has its own L1 instruction and data cache (thanks Johan), as well as scheduling/reordering logic. AMD is also careful to mention that the integer throughput of one of these integer cores is greater than that of the Phenom II's integer units.
Intel's Core architecture uses a unified scheduler fielding all instructions, whether integer or floating point. AMD's architecture uses independent integer and floating point schedulers. While Bulldozer doubles up on the integer schedulers, there's only a single floating point scheduler in the design.
Behind the FP scheduler are two 128-bit wide FMACs. AMD says that each thread dispatched to the core can take one of the 128-bit FMACs or, if one thread is purely integer, the other can use all of the FP execution resources to itself.
AMD believes that 80%+ of all normal server workloads are purely integer operations. On top of that, the additional integer core on each Bulldozer module doesn't cost much die area. If you took a four module (eight core) Bulldozer CPU and stripped out the additional integer core from each module you would end up with a die that was 95% of the size of the original CPU. The combination of the two made AMD's design decision simple.AMD has come back to us with a clarification: the 5% figure was incorrect. AMD is now stating that the additional core in Bulldozer requires approximately an additional 50% die area. That's less than a complete doubling of die size for two cores, but still much more than something like Hyper Threading.








94 Comments
View All Comments
gost80 - Monday, November 30, 2009 - link
Judging apparent benefit of this architecture over Intel's can be done only if the die size per _module_ is also made available. So, how about it?Zool - Thursday, December 3, 2009 - link
The thing is that the picture in this article contains shared L2 cache and L3 cache too and its quite unclear from the picture if L2 is shared to one module or all modules.(sharing all modules 2 times with L2 and L3 would be quite useless)The bulldozer picture in the other article from anandtech http://it.anandtech.com/IT/showdoc.aspx?i=3681&...">http://it.anandtech.com/IT/showdoc.aspx?i=3681&... shows clearly that the L2 cache belongs to module.
So clearly ading 50% to the core(which is everything till L1) is much less than 2 whole cores each with its own same size L2 cache ( Nehalem has only tiny 256KB cache per core from die area reasons).
If we take whole die size with 8MB L3 cache and 1MB L2 cache per module/core (+ things like memmory controler,hypertransport core/module conects) the final die increase could end in 10-15% or even less.
Zool - Thursday, December 3, 2009 - link
So a 4 module Bulldozer core with 512KB L2 cache and 6MB L3 cache could be something like 10-15% bigger than a 4 core PhenomII with 512KB L2 cache per core and same 6MB L3 cache. For 80% more integer performance that wouldnt be bad.And about Oracle , the server cpu-s from both intel and AMD are running in ranges from few hundred dolars to over 2k dolars with minimal performance increase just more sockets suported and everyone is buying them. So i wouldnt care less for them than a fly on my window. It will end on final pricing per core for cpu not core/modul license price.
swindelljd - Wednesday, December 2, 2009 - link
I bet Oracle is salivating over the new core count technique since it is sure to create a huge surge in their revenue because they charge per core on the x86 platform.