NVIDIA's Fermi: Architected for Tesla, 3 Billion Transistors in 2010
by Anand Lal Shimpi on September 30, 2009 12:00 AM EST- Posted in
- GPUs
Architecting Fermi: More Than 2x GT200
NVIDIA keeps referring to Fermi as a brand new architecture, while calling GT200 (and RV870) bigger versions of their predecessors with a few added features. Marginalizing the efforts required to build any multi-billion transistor chip is just silly, to an extent all of these GPUs have been significantly redesigned.
At a high level, Fermi doesn't look much different than a bigger GT200. NVIDIA is committed to its scalar architecture for the foreseeable future. In fact, its one op per clock per core philosophy comes from a basic desire to execute single threaded programs as quickly as possible. Remember, these are compute and graphics chips. NVIDIA sees no benefit in building a 16-wide or 5-wide core as the basis of its architectures, although we may see a bit more flexibility at the core level in the future.
Despite the similarities, large parts of the architecture have evolved. The redesign happened at low as the core level. NVIDIA used to call these SPs (Streaming Processors), now they call them CUDA Cores, I’m going to call them cores.
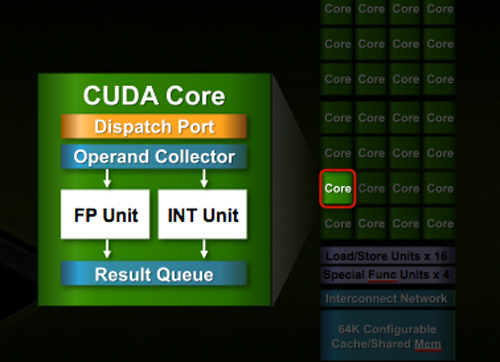
All of the processing done at the core level is now to IEEE spec. That’s IEEE-754 2008 for floating point math (same as RV870/5870) and full 32-bit for integers. In the past 32-bit integer multiplies had to be emulated, the hardware could only do 24-bit integer muls. That silliness is now gone. Fused Multiply Add is also included. The goal was to avoid doing any cheesy tricks to implement math. Everything should be industry standards compliant and give you the results that you’d expect.
Double precision floating point (FP64) performance is improved tremendously. Peak 64-bit FP execution rate is now 1/2 of 32-bit FP, it used to be 1/8 (AMD's is 1/5). Wow.
NVIDIA isn’t disclosing clock speeds yet, so we don’t know exactly what that rate is yet.
In G80 and GT200 NVIDIA grouped eight cores into what it called an SM. With Fermi, you get 32 cores per SM.
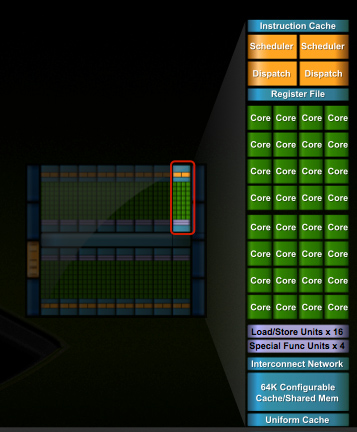
The high end single-GPU Fermi configuration will have 16 SMs. That’s fewer SMs than GT200, but more cores. 512 to be exact. Fermi has more than twice the core count of the GeForce GTX 285.
| Fermi | GT200 | G80 | |
| Cores | 512 | 240 | 128 |
| Memory Interface | 384-bit GDDR5 | 512-bit GDDR3 | 384-bit GDDR3 |
In addition to the cores, each SM has a Special Function Unit (SFU) used for transcendental math and interpolation. In GT200 this SFU had two pipelines, in Fermi it has four. While NVIDIA increased general math horsepower by 4x per SM, SFU resources only doubled.
The infamous missing MUL has been pulled out of the SFU, we shouldn’t have to quote peak single and dual-issue arithmetic rates any longer for NVIDIA GPUs.
NVIDIA organizes these SMs into TPCs, but the exact hierarchy isn’t being disclosed today. With the launch's Tesla focus we also don't know specific on ROPs, texture filtering or anything else related to 3D graphics. Boo.
A Real Cache Hierarchy
Each SM in GT200 had 16KB of shared memory that could be used by all of the cores. This wasn’t a cache, but rather software managed memory. The application would have to knowingly move data in and out of it. The benefit here is predictability, you always know if something is in shared memory because you put it there. The downside is it doesn’t work so well if the application isn’t very predictable.
Branch heavy applications and many of the general purpose compute applications that NVIDIA is going after need a real cache. So with Fermi at 40nm, NVIDIA gave them a real cache.
Attached to each SM is 64KB of configurable memory. It can be partitioned as 16KB/48KB or 48KB/16KB; one partition is shared memory, the other partition is an L1 cache. The 16KB minimum partition means that applications written for GT200 that require 16KB of shared memory will still work just fine on Fermi. If your app prefers shared memory, it gets 3x the space in Fermi. If your application could really benefit from a cache, Fermi now delivers that as well. GT200 did have an L1 texture cache (one per TPC), but the cache was mostly useless when the GPU ran in compute mode.

The entire chip shares a 768KB L2 cache. The result is a reduced penalty for doing an atomic memory op, Fermi is 5 - 20x faster here than GT200.








415 Comments
View All Comments
Kougar - Friday, October 2, 2009 - link
Hey Anand:Just wanted to say thanks for the article. Love the quotes and behind-the-scene views, and in general the ever so informative articles like this that just can't be found elsewhere. So, thank you!
bobvodka - Friday, October 2, 2009 - link
Someone earlier askes if supporting doubles was going to waste silicon, I don't think it will.If you look at the through put numbers and the fact that FP64 is half that of FP32 with the SFU disabled I suspect what is going on is that the FP64 calculations are being done by 2 cores at once with the SFU being involved in some way (given how it is decoupled from the cores there is no apprent good reason why the SFU should be disabled during FP64 operation).
A comment was also made re:ECC memory.
I suspect this wont make it to the consumer board; there is no good reason to do so and it would just cost silicon and power for a feature users don't need.
Zool - Friday, October 2, 2009 - link
Maybe the consumer board wont hawe ECC but it will be still in the silicon (disabled). I dont think that they will produce two different silicons just becouse of ECC.bobvodka - Friday, October 2, 2009 - link
hmmm, you are probably right on that score and that might aid yield if they can turn it off as any faults in the ECC areas could be safely ignored.Chances of them using ECC ram on the boards themselves I would have said was zero simply due to cost :)
halcyon - Friday, October 2, 2009 - link
Same foundry, same process, much more transistors....Based on roughly extrapolating scaling from the RV870, how much bigger power draw would this baby have?
The dollar draw from my wallet is going to be really powerful, that's for sure, but how about power?
deeper - Friday, October 2, 2009 - link
Well, not only is the GT300 months away but it looks like the card they showed off is a fake anyhoo, check it out at Charlie Demerjian's www.semiaccurate.comZool - Friday, October 2, 2009 - link
Could you pls delete majority of SiliconDoc replies and than this after them. Its embarassing to read them.Pirks - Friday, October 2, 2009 - link
I call BS. How many people have 2560x1600 30-inchers? Two? Three? Main point - resolutions are _VERY_ far from being stagnated, they have SOOOOOOOOO _MUCH_ room for growth until 2560x1600 which right now covers maybe 1% of the PC gaming market. 90% of PC gamers still use low-res 1680x1050 if not less (I for one have 1400x1050, yeah shame on me, I don't want to spend $800 on hi-end SLI setup just to play Crysis in all its hi-res beauty, for.get.it.)Shame Anand, real shame.
Otherwise top notch quality stuff, as always with Ananad.
bigboxes - Friday, October 2, 2009 - link
1680x1050 = low res??? Seriously? That's hi-def bro. I understand you can do better, but for my 20" widescreen it is definitley hi-def.JarredWalton - Friday, October 2, 2009 - link
I believe what you describe is exactly what is meant by stagnation. From Merriam-Webster: "To become stagnant." Stagnant: "Not advancing or developing." So yeah, I'd say that pretty much sums up display resolutions: they're not advancing.Is that bad? Not necessarily, especially when we have so many applications that do thing based purely on the wonderful pixel instead of on points or DPI. I use a 30" LCD, and I love the extra resolution for working with images, but the text by default tends to be too small. I have to zoom to 150% in a lot of apps (including Firefox/IE) to get what I consider comfortably readable text. I would say that 2560x1600 on a 30" LCD is about as much as I see myself needing for a good, looooong time.