The SSD Relapse: Understanding and Choosing the Best SSD
by Anand Lal Shimpi on August 30, 2009 12:00 AM EST- Posted in
- Storage
Live Long and Prosper: The Logical Page
Computers are all about abstraction. In the early days of computing you had to write assembly code to get your hardware to do anything. Programming languages like C and C++ created a layer of abstraction between the programmer and the hardware, simplifying the development process. The key word there is simplification. You can be more efficient writing directly for the hardware, but it’s far simpler (and much more manageable) to write high level code and let a compiler optimize it.
The same principles apply within SSDs.
The smallest writable location in NAND flash is a page; that doesn’t mean that it’s the largest size a controller can choose to write. Today I’d like to introduce the concept of a logical page, an abstraction of a physical page in NAND flash.
Confused? Let’s start with a (hopefully, I'm no artist) helpful diagram:
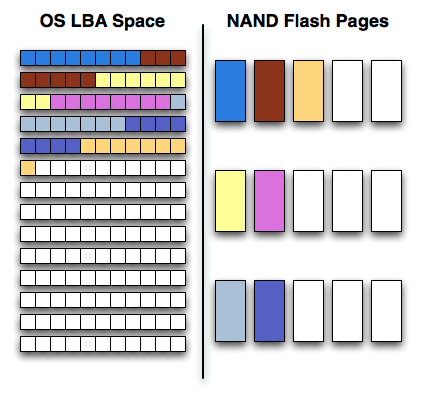
On one side of the fence we have how the software views storage: as a long list of logical block addresses. It’s a bit more complicated than that since a traditional hard drive is faster at certain LBAs than others but to keep things simple we’ll ignore that.
On the other side we have how NAND flash stores data, in groups of cells called pages. These days a 4KB page size is common.
In reality there’s no fence that separates the two, rather a lot of logic, several busses and eventually the SSD controller. The latter determines how the LBAs map to the NAND flash pages.

The most straightforward way for the controller to write to flash is by writing in pages. In that case the logical page size would equal the physical page size.
Unfortunately, there’s a huge downside to this approach: tracking overhead. If your logical page size is 4KB then an 80GB drive will have no less than twenty million logical pages to keep track of (20,971,520 to be exact). You need a fast controller to sort through and deal with that many pages, a lot of storage to keep tables in and larger caches/buffers.
The benefit of this approach however is very high 4KB write performance. If the majority of your writes are 4KB in size, this approach will yield the best performance.
If you don’t have the expertise, time or support structure to make a big honkin controller that can handle page level mapping, you go to a larger logical page size. One such example would involve making your logical page equal to an erase block (128 x 4KB pages). This significantly reduces the number of pages you need to track and optimize around; instead of 20.9 million entries, you now have approximately 163 thousand. All of your controller’s internal structures shrink in size and you don’t need as powerful of a microprocessor inside the controller.
The benefit of this approach is very high large file sequential write performance. If you’re streaming large chunks of data, having big logical pages will be optimal. You’ll find that most flash controllers that come from the digital camera space are optimized for this sort of access pattern where you’re writing 2MB - 12MB images all the time.
Unfortunately, the sequential write performance comes at the expense of poor small file write speed. Remember that writing to MLC NAND flash already takes 3x as long as reading, but writing small files when your controller needs large ones worsens the penalty. If you want to write an 8KB file, the controller will need to write 512KB (in this case) of data since that’s the smallest size it knows to write. Write amplification goes up considerably.
Remember the first OCZ Vertex drive based on the Indilinx Barefoot controller? Its logical page size was equal to a 512KB block. OCZ asked for a firmware that enabled page level mapping and Indilinx responded. The result was much improved 4KB write performance:
| Iometer 4KB Random Writes, IOqueue=1, 8GB sector space | Logical Block Size = 128 pages | Logical Block Size = 1 Page |
| Pre-Release OCZ Vertex | 0.08 MB/s | 8.2 MB/s |








295 Comments
View All Comments
Wwhat - Sunday, September 6, 2009 - link
If you read the first part of the article alone you would see how important a good controller is in a SSD and you would no ask his question probably, plus SSD's use the flash in parallel where a bunch of USB drives would not, the parallel thing is also mentioned in the article.And USB has a lot of overhead actually on the system, both in CPU cycles as well as in IO interrupts.
There are plug in PCI(e) cards to stick SD cards in though, to get a similar setup, but it's a bit of a hack and with the overhead and the management and controllers used and the price to buy many SD cards it's not competitive in the end and you are better of with a real SSD I'm told.
Transisto - Sunday, September 6, 2009 - link
You are right, the controller is very important.I think caching about 4-8 gig of most often accessed program files has the best price/performance ratio, for improving application load time. It it also very easily scalable.
One of the problem I see is integrating this ssd cache in the OS or before booting so it act where it matter the most.
I think there could be a near x25-m speedup from optimized caching and good controller no matter what SSD form factor it rely on. SD, CF, usb , pci or onboard.
Why it seams nobody talk about eboostr type of caching AND ,,, on other news ,,, Intel's Braidwood flash memory module could kill SSD market.
I am quite of a performance seeker.
But I don't think I need 80gig of SSD in my desktop,just some 8gb of good caching. Mabe a 60gb ssd on a laptop.
Well... I'm gonna pay for that controller once, not twice (160gb?)
Wwhat - Saturday, September 5, 2009 - link
Not that it's not a good article, although it does seem like 2 articles in one, but what I miss is getting to brass tacks regarding the filesystem used, and why there isn't a SSD-specific file system made, and what choices can be made during formatting in regards to blocksize, obviously if you select large blocks on filesystem level a would impact he performance of the garbage collection right? It actually seem the author never delved very deeply into filesystems from reading this.The thing is that even with large blocks on filesystem level the system might still use small segments for the actuall keepin track, and if it needs to write small bits to keep track of large blocks you'd still have issues, that's why I say a specific SSD filesystem migh be good, but only if there isn't a new form of SSD in the near future that makes the effort poinless, and if a filesystem for SSD was made then the firmware should not try to compensate for exising filesystem issues with SSD's.
I read that the SD people selected exFAT as filesystem for their next generation, and that also makes me wonder, is that just to do with licensing costs or is NTFS bad for flash based devices?
Point being at the filesystem needs to be highlighted more I think,
Bolas - Friday, September 4, 2009 - link
Would someone please hit Dell with the clue-board and convince them to offer the Intel SSD's in their Alienware systems? The Samsung SSD's are all that is stopping me from buying an Alienware laptop at the moment.EatTheMeat - Friday, September 4, 2009 - link
Congratulations on another fab masterclass. This is easily the best educational material on the internet regarding SSDs, and contrary to some comments, I think you've pitched your recommendations just right. I can also appreciate why you approached this article with some trepidation. Bravo.I have a RAID question for Anand (or anyone else who feels qualified :-))
I'm thinking of setting up 2 160GB x25-m G2 drives in RAID-0 for Win 7. I'd simply use the ICH10R controller for it. It's not so much to increase performance but rather to increase capacity and make sure each drive wears equally. After considering it further I'm wondering if SSD RAID is wise. First there's the eternal question of stripe size and write amplification. It makes sense to me to set the stripe size to be the same as, or a fraction of, the block size of the SSD. If you choose the wrong stripe size does it influence write amplification?
I'm aware that performance should increase with larger spripes, but I'm more concerned about what's healthy for the SSD.
Do you think I should just let SSD RAID wait until RAID drivers are optimised for SSDs?
I know you're planning a RAID article for SSDs - I for one look forward to it greatly. I've read all your other SSD articles like four times!
Bolas - Friday, September 4, 2009 - link
If SSD's in RAID lose the benefit of the TRIM command, then you're shooting yourself in the foot if you set them up in RAID. If you need more capacity, wait for the Intel 320GB SSD drives next year. Or better yet, use a 160 GB for your boot drive, then set up some traditional hard disk drives in RAID for your storage requirements.EatTheMeat - Friday, September 4, 2009 - link
Thanks for reply. I definitely hear you about the TRIM functionality as I doubt RAID drivers will pass this through before 2010. Still though, it doesn't look like the G2s drop much in performance with use anyway from Anand's graphs. With regard to waiting for 320 GB drives - I can't. These things are just too enticing, and you could always say that technology will be better / faster / cheaper next year. I've decided to take the plunge now as I'm fed up with an i7 965 booting and loading apps / games like a snail even from a RAID drive.I just don't want to bugger the SSDs up with loads of write amplification / fragmentation due to RAID-0. ie, is RAID-0 bad for the health of SSDs like defragmentation / prefetch is? I wonder if anyone knows the answer to this question yet.
jagreenm - Saturday, September 5, 2009 - link
What about just using Windows drive spanning for 2 160's?EatTheMeat - Saturday, September 5, 2009 - link
As far as I know drive spanning doesn't even the wear between the discs. It just fills up first one and then the other. That's important with SSDs because RAID can really help reduce drive wear by spreading all reads and writes across 2 drives. In fact, it should more than half drive wear as both drives will have large scratch portions. Not so with spanning as far as I know.Does anyone know if I'm talking sh1t here? :-)
pepito - Monday, November 16, 2009 - link
If you are not sure, then why do you assert such things?I don't know about Windows, but at least in Linux when using LVM2 or RAID0 the writes spread evenly against all block devices.
That means you get twice the speed and better drive wear.
I would like to think that microsoft's implementation works more or less the same way, as this is completely logical (but then again, its microsoft, so who can really know?).