Nehalem - Everything You Need to Know about Intel's New Architecture
by Anand Lal Shimpi on November 3, 2008 1:00 PM EST- Posted in
- CPUs
New TLBs, Faster Unaligned Cache Accesses
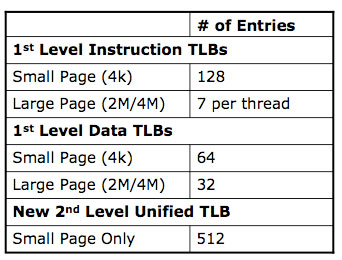
Historically the applications that push a microprocessor’s limits on TLB size and performance are server applications, once again with things like databases. Nehalem not only increases the sizes of its TLBs but also adds a 2nd level unified TLB for both code and data.
Another potentially significant fix that I’ve already talked about before is Nehalem’s faster unaligned cache accesses. The largest size of a SSE memory operation is 16-bytes (128-bits). For any of these load/store operations there are two versions: an op that is aligned on a 16-byte boundary, and an op that is unaligned.
Compilers will use the unaligned operation if they can’t guarantee that a memory access won’t fall on a 16-byte boundary. In all Core 2 processors, the unaligned op was significantly slower than the aligned op, even on aligned data.
The problem is that most compilers couldn’t guarantee that data would be aligned properly and would default to using the unaligned op, even though it would sometimes be used on aligned data.
With Nehalem, Intel has not only reduced the performance penalty of the unaligned op but also made it so that if you use the unaligned op on aligned data, there’s absolutely no performance degradation. Compilers can now always use the unaligned op without any fear of a reduction in performance.
To get around the unaligned data access penalty in previous Core 2 architectures, developers wrote additional code specifically targeted at this problem. Here’s one area where a re-optimization/re-compile would help since on Nehalem they can just go back to using the unaligned op.
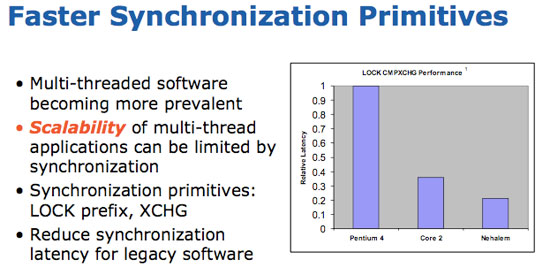
Thread synchronization performance is also improved on Nehalem, which leads us in to the next point.








35 Comments
View All Comments
defter - Friday, August 22, 2008 - link
Links are 20-bit wide, regardless of encoding or whether 1,2,8,16 or 20 bits are used to tranmist the data.I wonder who is flamebaiting here, a previous poster just mentioned the correct link width, he wasn't talking about "usable speed".
rbadger - Thursday, August 21, 2008 - link
"Each QPI link is bi-directional supporting 6.4 GT/s per link. Each link is 2-bytes wide..."This is actually incorrect. Each link is 20 bits wide, not 16 (2 bytes). This information is on the slide posted directly below the paragraph.
JarredWalton - Thursday, August 21, 2008 - link
It's 20-bits but using a standard 8/10 encoding mechanism, so of the 20 bits only 16 are used to transmit data and the other four bits are (I believe) for clock signaling and/or error correction. It's the same thing we see with SATA and HyperTransport.ltcommanderdata - Thursday, August 21, 2008 - link
Since the PCU has a firmware, I wonder if it will be updatable? It would be useful if lessons learn in the power management logic of later steppings and in Westmere can be brought back to all Nehalems through a firmware update for lower power consumption or even better performance with better Turbo mode application. Although a failed or corrupt firmware update on a CPU could be very problematic.wingless - Thursday, August 21, 2008 - link
I thought about this when I read about it the first time too. Flashing your CPU could kill the power management or the whole CPU in one fell swoop!