AMD's Quad-Core Barcelona: Defending New Territory
by Johan De Gelas on September 10, 2007 12:15 AM EST- Posted in
- IT Computing
Software Rendering: zVisuel (32-bit Windows)
This benchmark is the zVisuel Kribi 3D test, which is exclusive to AnandTech.com and which simulates the assembly of an exclusive mechanical watch. The complete model is very detailed with around 300,000 polygons and a lot of texture, bump, and reflection maps. More than 1000 frames are rendered and the average FPS (frames per second) is reported. All this is rendered on the "Kribi 3D" engine, an ultra-powerful real-time software rendering 3D engine. That all this happens at reasonable speeds is a result of the fact that the newest AMD and Intel architectures contain four cores and can perform up to eight 32-bit FP operations per clock cycle and per core. The people of zVisuel told us that - in reality - the current Core architecture can sustain six FP operations in well optimized loops.

The 3D model of the benchmark in the middle of its assembly
Can the newest AMD architecture sustain the same amount of massive FP power? Eric Bron provided us with a benchmark which is based on real world use by a well know zVisuel client. The first benchmark does not use antialiasing
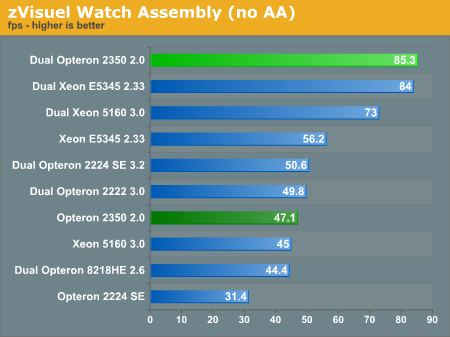
The tables are turning: while the newest AMD quad-core had to let the faster clocked Intel quad-core Xeon go in the LINPACK tests, it takes a small but still measurable lead in zVisuel. Notice that the Intel CPU has the advantage when it comes to raw processing power: it is about 19% faster in a single CPU configuration. Once you add a second CPU in both systems, that 19% lead is turned into a 3% advantage for AMD. Also note that a 2GHz Quad Opteron 2350 is about as fast as a dual 3GHz Opteron 2222 DC.
Be aware though that you need the Enterprise edition of Windows 2003 to see this kind of performance. The 32-bit Windows 2003 standard does not support NUMA and the bandwidth hungry AMD quad-core does not like that at all. Performance was up to 14% (!) lower, showing only 73 fps instead of 85 fps.
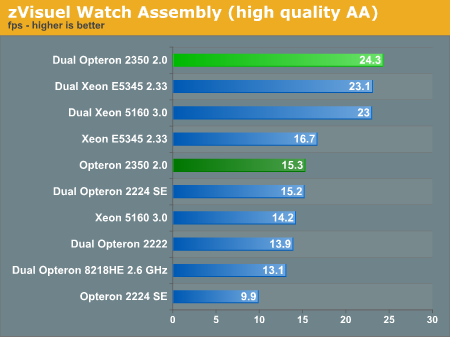
We performed the same benchmark, but with antialiasing applied. AA makes the application a bit more memory intensive. The AMD quad-core extends its lead from 3% to 5%, and a single 2GHz quad-core is now capable of even outperforming a 3.2GHz dual Opteron SE 2224.
The LINPACK and zVisuel benchmarks make it clear that Intel and AMD have about the same raw FP processing power (clock for clock), but that the Barcelona core has the upper hand when the application has to access the memory a lot.
This benchmark is the zVisuel Kribi 3D test, which is exclusive to AnandTech.com and which simulates the assembly of an exclusive mechanical watch. The complete model is very detailed with around 300,000 polygons and a lot of texture, bump, and reflection maps. More than 1000 frames are rendered and the average FPS (frames per second) is reported. All this is rendered on the "Kribi 3D" engine, an ultra-powerful real-time software rendering 3D engine. That all this happens at reasonable speeds is a result of the fact that the newest AMD and Intel architectures contain four cores and can perform up to eight 32-bit FP operations per clock cycle and per core. The people of zVisuel told us that - in reality - the current Core architecture can sustain six FP operations in well optimized loops.
The 3D model of the benchmark in the middle of its assembly
Can the newest AMD architecture sustain the same amount of massive FP power? Eric Bron provided us with a benchmark which is based on real world use by a well know zVisuel client. The first benchmark does not use antialiasing
The tables are turning: while the newest AMD quad-core had to let the faster clocked Intel quad-core Xeon go in the LINPACK tests, it takes a small but still measurable lead in zVisuel. Notice that the Intel CPU has the advantage when it comes to raw processing power: it is about 19% faster in a single CPU configuration. Once you add a second CPU in both systems, that 19% lead is turned into a 3% advantage for AMD. Also note that a 2GHz Quad Opteron 2350 is about as fast as a dual 3GHz Opteron 2222 DC.
Be aware though that you need the Enterprise edition of Windows 2003 to see this kind of performance. The 32-bit Windows 2003 standard does not support NUMA and the bandwidth hungry AMD quad-core does not like that at all. Performance was up to 14% (!) lower, showing only 73 fps instead of 85 fps.
We performed the same benchmark, but with antialiasing applied. AA makes the application a bit more memory intensive. The AMD quad-core extends its lead from 3% to 5%, and a single 2GHz quad-core is now capable of even outperforming a 3.2GHz dual Opteron SE 2224.
The LINPACK and zVisuel benchmarks make it clear that Intel and AMD have about the same raw FP processing power (clock for clock), but that the Barcelona core has the upper hand when the application has to access the memory a lot.








46 Comments
View All Comments
Phynaz - Monday, September 10, 2007 - link
Isn't this intentionally crippling the system?JohanAnandtech - Monday, September 10, 2007 - link
No. Just check what Intel and other companies do when they submit Specjbb scores for example. With HW prefetch on, you get about 10% lower scores.nj2112 - Tuesday, September 11, 2007 - link
Was HW prefetching off for all tests ?lplatypus - Monday, September 10, 2007 - link
I thought that 2x00 series CPUs only supported one coherent hypertransport link, so would this mean that the "Dual Link" feature involving two HT links would require 8300 series CPUs?mino - Tuesday, September 11, 2007 - link
Well, maybe the changed that and all links are active (to enable setups like this) and the CPU just refuses to comunicate more than one coherent hopa away..mino - Tuesday, September 11, 2007 - link
Well, maybe the changed that and all links are active (to enable setups like this) and the CPU just refuses to comunicate more than one coherent hopa away..MDme - Monday, September 10, 2007 - link
Let the games begin!Viditor - Thursday, September 13, 2007 - link
Are you going to be re-doing the review with the shipping version (stepping BA) anytime soon?I'm most curious to see if the improvement of 5%+ claims are true...
MDme - Monday, September 10, 2007 - link
I think Barcelona will be a success in the server world. It's performance is around 20% faster than equivalently clocked xeons with the exception of certain programs like fritz and the linpack intel library where it is around 5-10% slower. But since it scales better than the xeon chips it should negate that and increase it's lead on others as core/sockets increase. add to that it's power efficiency tweaks and aggressive pricing, AMD will be able to hold off intel in the server world.....maybe.With 2.5Ghz Barceys coming up that would be equivalent to around 3-3+ Ghz xeons. So AMD was right that they need to get to 2.6 Ghz....AMD needs to ramp up clock to get the highest-end performance crown, but for now, their offering offers a nice balance of performance and power efficiency for the price.
Now time for the Phenom to get it's act together.
TA152H - Monday, September 10, 2007 - link
The article should have mentioned the performance penalty Intel chips are suffering from with regards to FB-DIMMS. While it's true they should be benchmarked in servers with with memory, it's also widely rumored that they are going to be offering choices in the near future. This memory has a really big impact on a lot of benchmarks, so when looking towards the future, or desktop, it's important to keep in mind the importance of Intel using different memory. I don't think even Intel is stubborn enough to stick with this seriously slow, and power hungry memory. Maybe as a choice it's fine, but it must be clear to them that offering something else as well as FB-DIMMs is very desirable in the server space. Then again, look at how long they stuck with Rambus.