AMD's Quad-Core Barcelona: Defending New Territory
by Johan De Gelas on September 10, 2007 12:15 AM EST- Posted in
- IT Computing
64-bit Linux HPC Performance: LINPACK
There is one kind of code where Core really ate the AMD CPUs for breakfast. It was close to embarrassing: floating point intensive code that makes heavy use of vector SIMD, also called packed SSE (and SSE2/SSE3) runs up to two times as fast on a Xeon 5160 (3GHz) than on Opteron 2222 (3GHz) . This is also one of the (but probably not the main) reason why AMD was also falling a bit behind in the gaming area.
AMD has really gone a long way to improve the performance of 128-bit packed SSE instructions:
Meet LINPACK, a benchmark application based on the LINPACK TPP code, which has become the industry standard benchmark for HPC. It solves large systems of linear equations by using a high performance matrix kernel. We used Intel's version of LINPACK, which uses the highly optimized Intel Math Kernel Library. The Intel MKL is quite popular and in an Intel dominated world, AMD's CPUs have to be able to run Intel optimized code well.
We used a workload of square matrices of sizes 5000 to 30000 by steps of 5000, and we ran four (dual dual-core) or eight threads (dual quad-core). As the system was equipped with 8GB of RAM, the large matrixes all ran in memory. LINPAC is expressed in GFLOPs (Giga/Billions of Floating Operations Per Second). We'll start with the quad-core scores (one quad or two duals).
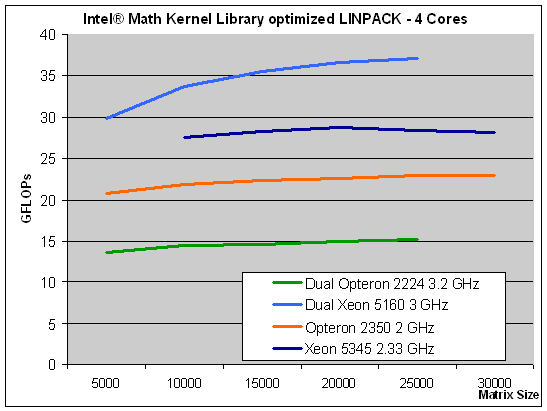
Yes, this code is very Intel friendly but it does exist in the real world, and it is remarkably interesting. Look at what Barcelona is doing: it is outperforming a 60% higher clocked Opteron 2224 SE. That means that clock for clock, the third generation Opteron is no less than 142% faster. That is a massive improvement!
Thanks to meticulous tuning for the Intel's cores, the Xeon is still winning the benchmark. A 17% higher clocked Xeon 5345 is about 25-26% faster than Barcelona, but the days where this kind of code resulted in embarrassing defeats for AMD are over. We are very curious how a LINPACK compiled with AMD's math kernel libraries and other compilers would do, but the late arrival didn't allow us to do much recompiling.
Now let's take a look at the eight thread results. We kept the Xeon 5160 (four threads) in this graph, so you can easily compare the results with the previous graph.
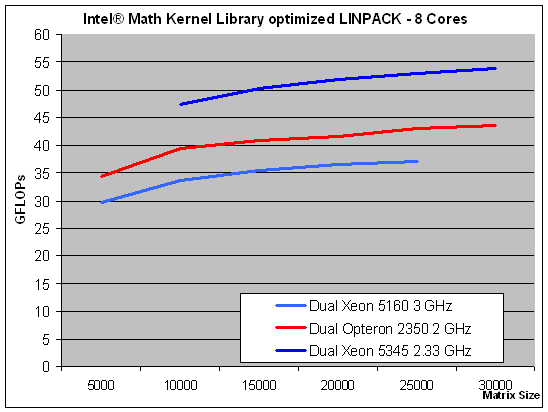
Normally you would expect that this kind of code with huge matrices has to access the memory a lot, but masterly optimization together with hardware prefetching ensures most of the data is already in the cache. The quad-core Xeon wins again, but the victory is a bit smaller: the advantage is 20%-23%. Let us see if Intel can still keep the lead when we look at a benchmark which is very SSE intensive and which is optimized for Intel CPUs, but this time it's developed by a third party.
There is one kind of code where Core really ate the AMD CPUs for breakfast. It was close to embarrassing: floating point intensive code that makes heavy use of vector SIMD, also called packed SSE (and SSE2/SSE3) runs up to two times as fast on a Xeon 5160 (3GHz) than on Opteron 2222 (3GHz) . This is also one of the (but probably not the main) reason why AMD was also falling a bit behind in the gaming area.
AMD has really gone a long way to improve the performance of 128-bit packed SSE instructions:
- Instruction fetch has been doubled to 32 bytes
- 128-bit SSE computations now decode into a single micro-op (two in K8)
- The load unit can load two 128-bit numbers from the L1 cache each cycle
- FP Reservation stations are still 36 entry, but they're now 128-bits wide instead of 64-bits
- All three FPU executions units were widened to 128-bit (64-bit before)
- The L2 cache has double the bandwidth to cope with this
Meet LINPACK, a benchmark application based on the LINPACK TPP code, which has become the industry standard benchmark for HPC. It solves large systems of linear equations by using a high performance matrix kernel. We used Intel's version of LINPACK, which uses the highly optimized Intel Math Kernel Library. The Intel MKL is quite popular and in an Intel dominated world, AMD's CPUs have to be able to run Intel optimized code well.
We used a workload of square matrices of sizes 5000 to 30000 by steps of 5000, and we ran four (dual dual-core) or eight threads (dual quad-core). As the system was equipped with 8GB of RAM, the large matrixes all ran in memory. LINPAC is expressed in GFLOPs (Giga/Billions of Floating Operations Per Second). We'll start with the quad-core scores (one quad or two duals).
Yes, this code is very Intel friendly but it does exist in the real world, and it is remarkably interesting. Look at what Barcelona is doing: it is outperforming a 60% higher clocked Opteron 2224 SE. That means that clock for clock, the third generation Opteron is no less than 142% faster. That is a massive improvement!
Thanks to meticulous tuning for the Intel's cores, the Xeon is still winning the benchmark. A 17% higher clocked Xeon 5345 is about 25-26% faster than Barcelona, but the days where this kind of code resulted in embarrassing defeats for AMD are over. We are very curious how a LINPACK compiled with AMD's math kernel libraries and other compilers would do, but the late arrival didn't allow us to do much recompiling.
Now let's take a look at the eight thread results. We kept the Xeon 5160 (four threads) in this graph, so you can easily compare the results with the previous graph.
Normally you would expect that this kind of code with huge matrices has to access the memory a lot, but masterly optimization together with hardware prefetching ensures most of the data is already in the cache. The quad-core Xeon wins again, but the victory is a bit smaller: the advantage is 20%-23%. Let us see if Intel can still keep the lead when we look at a benchmark which is very SSE intensive and which is optimized for Intel CPUs, but this time it's developed by a third party.








46 Comments
View All Comments
erikejw - Tuesday, September 11, 2007 - link
I take back what I said.I mixed up 3 different reviews that does not correlate and is not comparable.
I did not realize that until now even though I looked at them again.
Optimizations put off on AMD processors was just hearsay and likely with the results presented but since I was wrong about the results that part is probably wrong too.
So now everything I have to say is, great article :)
Now I look forward to the tests with the 2.5GHz part and some overclock on it to see what a 2.8 or even a 3GHz part would do.
kalyanakrishna - Tuesday, September 11, 2007 - link
Sorry ... with all the discussion, your methodology is incomplete and leading to a biased result. Maybe there is code that is optimized for Intel processor - but the focus of the article is performance - thats what you intended it to be ... if not, please redo the article, change your deductions and focus it on code compatibility. No one measuring performance on their systems will use Intel Xeon optimized code on AMD processors. There are bunch of other compilers and performance libraries available. If not, please use a compiler that WILL optimize for both - pathscale, gcc and more ...I agree with your processor frequency aspect ... however, neither did Intel have a high speed freq on the launch date. The way it should have been presented is "at same frequency ... there is not much difference in performance" "at higher clocks, Intel does have advantage that comes at a price" Is this the same deduction you brought out in your article? Far from it ... do you concur?
And your reasoning that you didnt have time to optimize the code is not acceptable. What was the point of this article - throw out some incomplete article on the day of the launch so everyone doesnt think AnandTech doesnt have a comment on Barcelona or maintain your high standards and put out a well written, mature and complete article based on results based from a rock solid testing methodology with critical analysis?
The article was leaning towards a dramatic touch than presenting a neutral analysis. And, please stop saying Linpack is Intel friendly. The code is NOT, the way you compiled it is optimized for LinPack!! There is a HUGE difference. A code can only be Intel "friendly" when it is written with special attention to make sure it fully exploits all the features that Xeon has to offer and not necessarily by any other processors. And, if you do read my email to you - you will notice my stand on that point and lot more.
So, I kindly request you to immediately take down this article with a correction or redo your article and change the focus. Maybe you had a different idea in your mind when writing it ... but the way it was written is not what you said you wanted it to be. All the comments you made now are not brought out in the article.
Thank you for your time.
kalyanakrishna - Tuesday, September 11, 2007 - link
And of course, we didnt even get to the point where the test setup says "BIOS Note: Hardware prefetcing turned off" but in your analysis section it says"but masterly optimization together with hardware prefetching ensures most of the data is already in the cache. The quad-core Xeon wins again, but the victory is a bit smaller: the advantage is 20%-23%."
That says enough about the completeness and accuracy of your article. The article is full of superlatives like masterly, meticulous to describe Intel processors. The bias cant be any more blatant.
Now, will you please take it down and stop spreading the wrong message!!! There is nothing wrong in saying it was an incomplete article and in the interests of accuracy we would like to retract our claims!! Stop sending the wrong message to your huge reader base and influence their opinion of a potentially good product!
fitten - Tuesday, September 11, 2007 - link
Potentially... but not yet a good product, IMO. Hopefully AMD will have another stepping out sometime by the end of the year that may actually be competitive. As of right now, Barcelona isn't competitive with Intel offerings. The problem is that the target is moving as Intel will be releasing new chips by the end of the year.As far as Intel compilers are concerned, you do realize that Intel's compilers are better than GCC (which is NOT known for agressive optimizations and stellar performance) and are downloadable from their site. Code compiled with Intel compilers tends to execute faster on both Intel and AMD processors than code compiled with GCC in many cases.
As far as accuracy of the various reviews... it's AMD's fault for getting only a few systems to a few reviewers only 48 hours before the launch date. I believe this was intentional in order to delay any thorough testing of Barcelona in the short term. Plus, there's the whole bit about AMD requiring that reviewers submit reviews to AMD for sanitizing before publishing them, as well. I'm quite convinced that AMD knew (and knows) that Barcelona is a turd and are just trying to buy time by various nefarious methods so that they can have a little more time to get their act together. If it weren't for investors and the world pushing AMD to actually release on their (much delayed) launch date, I'm quite sure AMD would have rather waited a few months so they'd have a better stepping to debut.
kalyanakrishna - Tuesday, September 11, 2007 - link
This is exactly what I am talking about ... see the comments on Digg:http://www.digg.com/hardware/Finally_AMD_s_Barcelo...">http://www.digg.com/hardware/Finally_AMD_s_Barcelo...
Now, please retract your observations.
kalyanakrishna - Wednesday, September 12, 2007 - link
Johan,Comment by swindelljd below ...
I believe you underestimated the impact your article has on purchasing decisions of the customers. :)
I hope customers do continue to look at AnandTech as a source of impartial, genuine and correct data on performance of new technologies.
As Spiderman's uncle would say "With great power, comes great responsibility". :) :)
swindelljd - Thursday, September 13, 2007 - link
Yes, I would say anandtech.com has the most comprehensive, thoughtful, well organized, un-biased and current analysis of any site/content that currently exists. Many other sites even reference or simply use anandtech.com's analysis barely augmenting with their own.I have definitely used them in the past for both personal purchases (enthusiast OC'ing) and business purchases of my production hardware environment. In each case I've used multiple sources but always find myself returning to anandtech.com.
I'd hate to see them delay the release of an article just because there was "just one more test to run". Like many things in life, sometimes it's more important to simply work with the information at hand (even if not quite complete) than to wait to make a decision. Some might call that "analysis-paralysis".
Ultimately it's up to me when making purchasing decisions to weigh all the information and consider how much issues such as you pointed out regarding "not quite complete" analysis would impact a real world scenario.
I applaud anandtech.com for all the work they do (and the LONG hours they must put in) in quantifying what in some cases is unquantifiable.
Now back to my original question - why do the Woodcrest/MySQL benchmarks taken approx 14 months apart vary by so much and for the worse? Did the benchmark used change or am I just misreading the benchmark?
thanks,
John
kalyanakrishna - Thursday, September 13, 2007 - link
John,Its great that you trust the site content so much. I know many people who do. That is why I was shocked to see the shortcomings in the article ... most of which are, I must say, basic to some extent.
I myself have been reading the site since many years and I know many colleagues who refer this site for just about anything ... hence my stand that they realize the importance of their work and publishings.
Maybe its your fondness for the site ... but the specific comments I made are very important and do affect real world results. For any one looking to make a cluster or build an HPC system - thats their real world. Just like database performance is real world to you.
Just to make it explicit... its not a flame war or anything like that ... it is to make sure that the data is correct and a relevant comparison is made.
thanks.
flyck - Tuesday, September 11, 2007 - link
When will there be an update available? :).
JohanAnandtech - Monday, September 10, 2007 - link
2 GHz Intel's were not available to us. And considering AMD's pricepoints, a 2 GHz Opteron 2350 are targetting 2.33 GHz Xeons. It is fairly accepted that AMD has to lure customers with a small price advantage.
Because there is a lot Intel optimized code out there? Do you deny that there are developers out there that use the Intel MKL?