Intel Penryn Performance Preview: The Fastest gets Faster
by Anand Lal Shimpi on April 18, 2007 8:00 AM EST- Posted in
- CPUs
You knew it had to be coming. A year ago Intel previewed its first Core 2 processors ahead of their release, and with Penryn due out before the end of the year the boys in blue are back again.
Penryn is still pretty early, although Intel was able to reach over 3GHz on all of the samples we tested. Not surprisingly, the number of benchmarks we were able to run was quite limited. Intel also provided us with a handful of its own test results demonstrated at IDF Beijing which we have reproduced here as well.

Penryn in action
As a recap, Penryn is the 45nm micro-architectural update to Intel's current Core 2 processors. The slide below shows most of the improvements to Penryn:
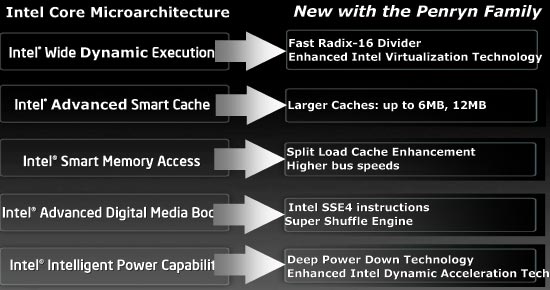
A faster divider and super shuffle engine both improve IPC in very specific applications. As we mentioned in our IDF day 1 coverage, faster FSB speeds appear to be reserved for Penryn based Xeon processors at this point as desktop Penryn cores will use a 1333MHz FSB. Penryn takes the total amount of L2 cache up to 6MB per two cores, giving the quad core Penryn chips a total of 12MB of on-die L2 cache. Penryn also has improved power management technologies, but only for mobile Penryn chips.

Penryn up and running








66 Comments
View All Comments
ShapeGSX - Wednesday, April 18, 2007 - link
"I can account for the other 9% right now: higher FSB, more cache."Yes, and those are architectural changes to the chip.
Look at the first page of the article. There aren't that many changes to these new chips. It is just an evolutionary step. Nobody is billing it as anything but. But an average 20% increase in just one year is still very impressive.
Factor in the SSE4 boost that Divx encoding gets, and the leap is even more impressive.
KeypoX - Wednesday, April 18, 2007 - link
while it is impressive to have a 20% increase it still beats the fact that it is mostly more clock speed and more cache. It will be more impressive to see if these can overclock like the c2d's ya know like 1-1.5ghz oc's on average. Then i will be impressed. Still waiting for the amd response too :(defter - Wednesday, April 18, 2007 - link
The clock speed difference is only about 9%, considering the scaling is not linear, clock speed alone accounts for maybe 6-7% performance increase. This means IPC is improved by over 10%, this is very impressive and reminds me of Willamette->Northwood transition. Compare this for example with AMD's 130nm->90nm and 90nm->65nm transitions that gave no increase in IPC at all.I many of you put too much emphasis on cache, in games, doubling the cache from 2MB to 4MB at 3GHz gives about 10-15% increase in performance: http://www.pconline.com.cn/diy/cpu/reviews/0704/99...">http://www.pconline.com.cn/diy/cpu/reviews/0704/99...
Increasing the cache further by 50% to 6MB will naturally produce less benefits, thus the cache alone doesn't explain the >10% IPC improvement. There are also noticable improvements elsewhere.
Goty - Wednesday, April 18, 2007 - link
Wow, you have no idea what you're talking about. IPC did not change at all with Penryn.TA152H - Wednesday, April 18, 2007 - link
Actually, you don't if you think that's true. Do you know what IPC means? Instructions Per Cycle? Based on the results published, there is no other explanation. Keeping in mind that there are always, or almost always, other factors involved in benchmarks besides raw CPU power, even getting an improvement equal to the clock speed increase is an accomplishment, when you exceed this you are obviously doing more per clock cycle. What other explanation is there?To emphasize this even further, just adding instructions that are used and do more work would increase the amount of work per cycle, although not technically not IPC. But, by the accepted meaning of the word, it would. Adding cache could also improve IPC, although if it comes with additionally latency it could hurt it too.
So, he's right, it's only a matter of the extent of the improvement. I don't like blanket numbers like 10% because it acts like all applications behave the same, but certainly for the applications they ran, it did show an IPC improvement.
Goty - Wednesday, April 18, 2007 - link
Exactly, IPC is Instructions Per Clock. Adding instructions like SSE4 won't increase the IPC (especially since there are no applications that I know of out there that utilize SSE4).I know that the only way to increase performance other than increasing the number of clock cycles you get in in a certain time frame is to increase the real IPC, I was referring to the maximum attainable by the architecture in a best case scenario (which is, I believe, also what the poster above me was referring to and what manufacturers mean when discussion IPC.).
TA152H - Wednesday, April 18, 2007 - link
Your logic is flawed. Either SSE4 increases IPC or it doesn't, irrespective of what uses it currently. If you want to go by the actual name, it wouldn't regardless. If you go by the true, and useful, meaning of the word, work per cycle, they could in certain applications add to it.IPC does not mean best case scenario, it means in real world situations. The problem is, defining that. Rather than argue about it, just think about how useful a number would be that doesn't approach real world situations and just is based on how wide the processor is. It isn't useful at all, whereas something that got close to real world use would be a lot more useful. That's why it has that meaning. Maximum IPC isn't really that important, since it's more theoretical than real. Only how it relates to running software matters, but, of course, that's not easy to quantify because software is different from one app to another.
IPC is a pretty useless number anyway, taken out of the context of clock speed. Just as useless as clock speed is taken outside of the context of IPC. Although, having said that, with x86, I think you're beginning to approach a level of maturity with the design (with the demise of the miserable P7) that IPC is pretty similar. Back in the bad old days, outside of the crappy 186 and 386, you'd see massive improvements. 286 was at least 2x faster than the 8086, probably closer to 3x. 486 was 2x faster than the 386, Pentium was at least 60% faster than the 486, and the Pentium Pro was roughly 35% faster and ran at higher clock speeds than the Pentium. Now, unless you really screw up with a design like the P7, you don't see these huge improvements. Put another way, the Athlon 64 isn't that much faster on an IPC basis than the magnificent K5 :P. For that matter, the Core 2 isn't a huge improvement over the Pentium Pro per cycle. Considering it's been 10 and 11 years respectively, IPC isn't growing nearly as fast as clock cycles, which are now also dead in the water. K5 ran at 116.7 in it's finest incarnation, PPro at 200. Roughly a 2500%, and 1500%. IPC is up maybe 25% in the same interval?
defter - Wednesday, April 18, 2007 - link
You don't have any clue...
How many FP instructions for example K5 could start and finish within let's say 10 cycles? Then compare those numbers to Athlon64....
Then you could look at some Pentium III coppermine vs. Banias, Banias vs. Dothan, Dothan vs. Yonah single core and Yonah vs. Core2 benchmarks. You would see that there are huge real IPC increase between Pentium III and Core2. And Pentium III has significantly higher real IPC than original Pentium Pro.
TA152H - Wednesday, April 18, 2007 - link
Actually, you don't have a clue. K5 wasn't known for floating point, and most people don't use floating point. I was talking about integer, that should have been obvious to you. The K5 had a horrible floating point unit, as did the K6.However, on integer, the K5 had extremely high IPC, but the clock rate was very low. The 116.7 K5 ran roughly the same speed as a Pentium 166. Did you know this before posting your stupid remarks?
Pentium III has a big improvement over the Pentium Pro? Are you an idiot? They are essentially the same processor. On 16-bit code it would be faster, for sure, but who still runs that? The move from the Pentium Pro to the Pentium II was to address that, and make it less expensive because the Pentium Pro ran the L2 cache at full speed and was part of the processor package. It was too expensive for mainstream use. The Pentium III was a Pentium II with SSE, and the Coppermine added a 256K cache on the chip, instead of the 512K the Katmai had. So, it ended up where the Pentium Pro was, although the Coppermine's cache was faster. Was it a lot faster? No way, you obviously don't know what you're talking about.
The Core 2 isn't that much faster than a Tualatin clock normalized either. As I said, they are slightly faster with each generation, but it's not enormous like the clock speeds. For two generations, it's really quite low. Look at the difference between the 286 and 486, or 386 and Pentium. You were seeing 3x to 4x the improvement. The difference in the Pentium Pro and Core 2 isn't even close to that, it's relatively minor. Compared to the clock speed, 200 MHz to 2.93 GHz. Hmmmm, you understand my point now?
defter - Thursday, April 19, 2007 - link
Of course I knew that. But being as fast as Pentium at 50% higher clock speed isn't that great accomplishment for modern CPUs like Athlon64. Most people don't use floating point??? Yeah, right, I wonder why AMD significantly improved FPU in Barcelona if nobody will use it....
LOL, I wonder who don't know what he is talking about. P3 Coppermine was about 10% faster than P3 Katmai at the same clock. When you then consider that original PPro had slow external L2 cache, and it lacked MMX and SSE instructions, you will notice that there is significant clock-to-clock performance improvement between PPro and Coppermine.
Yes it is, Tualatin was clerly faster than Coppermine, Banias was clearly faster than Tualatin, Dothan was clearly faster than Banias, Yonah was clearly faster than Dothan (FP improvements) and Core2 was clearly faster than Yonah at the same clock speed. Thus there is a large difference between Core2 and P3 Coppermine.