Barcelona Architecture: AMD on the Counterattack
by Anand Lal Shimpi on March 1, 2007 12:05 AM EST- Posted in
- CPUs
Getting Spendy with Transistors - L3 cache
AMD lost the cache race to Intel long ago, but that's more of a result of manufacturing capacity than anything else. AMD knew it could not compete with Intel's ability to churn out more transistors on smaller processes faster, so it did the next best thing and integrated a memory controller. With the K8's on-die memory controller, AMD reduced the need for larger caches, which is why even current Athlon 64 X2s only have a 512KB L2 cache per core - a figure that Intel introduced back in 2002 with its Northwood core.
These days two Core 2 cores share up to 4MB of L2 cache, while the fastest offerings from AMD weigh in at half that. The gap will continue to widen with Barcelona, as each of its four cores will only have a 512KB L2 cache. While a quad-core Barcelona chip will have 2MB of total L2 cache for all four cores, a quad-core Kentsfield currently has 8MB of L2 cache for all four cores. By the end of this year, Intel's Penryn is expected to have 12MB of L2 cache for all of its cores.
In order to keep die sizes manageable, AMD constructed its quad-core Barcelona out of four cores each with a 128KB L1 and 512KB L2, much like most mainstream K8 based products today. However, the era of multithreaded applications demands that multi-core CPUs should have some common pool of high speed memory to keep them running at peak efficiency.
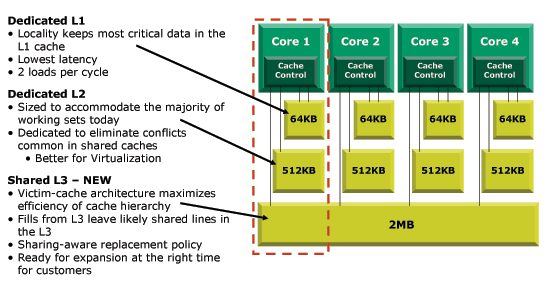
With four cores sharing a single die, AMD didn't want to complicate its design by introducing a large unified L2 cache. Instead, it took the K8 cache hierarchy and added a third level of cache to the mix - shared among all four cores. At 65nm, a quad-core Barcelona will have a 2MB L3 cache that is shared by all four cores.
The hierarchy in Barcelona works like this: the L2 caches are filled with victims from the L1 cache. When a cache gets full, data that was not recently used is evicted to make room for new data that the cache controller determines is good to keep in the cache. In a victim cache structure, the evicted data is placed in a storage area known as a victim cache instead of being removed from cache all together. If the data should become useful again, the cache controller simply has to fetch it from the victim cache rather than much slower main memory; victims from Barcelona's L1 are kicked out to the L2 cache.
The new L3 cache, acts as a victim for the L2 cache. So when the small L2 cache fills up, evicted data is sent to the larger L3 cache where it is kept until space is needed. The algorithms that govern the L3 cache's operation are designed to accommodate data that is likely to be needed by multiple cores. If the CPU fetches a bit of code, a copy is left in the L3 cache since the code is likely to be shared among the four cores. Pure data load requests however go through a separate process. The cache controller looks at history and if the data has been shared before, a copy will be left in the L3 cache; otherwise it will be invalidated.
Associativity hasn't been changed for the L1 and L2 caches; they are still 2-way and 16-way set associative, respectively. However, the new L3 cache is 32-way set associative. It has been designed to increase the hit rate of a relatively small cache compared to its competition.
AMD lost the cache race to Intel long ago, but that's more of a result of manufacturing capacity than anything else. AMD knew it could not compete with Intel's ability to churn out more transistors on smaller processes faster, so it did the next best thing and integrated a memory controller. With the K8's on-die memory controller, AMD reduced the need for larger caches, which is why even current Athlon 64 X2s only have a 512KB L2 cache per core - a figure that Intel introduced back in 2002 with its Northwood core.
These days two Core 2 cores share up to 4MB of L2 cache, while the fastest offerings from AMD weigh in at half that. The gap will continue to widen with Barcelona, as each of its four cores will only have a 512KB L2 cache. While a quad-core Barcelona chip will have 2MB of total L2 cache for all four cores, a quad-core Kentsfield currently has 8MB of L2 cache for all four cores. By the end of this year, Intel's Penryn is expected to have 12MB of L2 cache for all of its cores.
In order to keep die sizes manageable, AMD constructed its quad-core Barcelona out of four cores each with a 128KB L1 and 512KB L2, much like most mainstream K8 based products today. However, the era of multithreaded applications demands that multi-core CPUs should have some common pool of high speed memory to keep them running at peak efficiency.
With four cores sharing a single die, AMD didn't want to complicate its design by introducing a large unified L2 cache. Instead, it took the K8 cache hierarchy and added a third level of cache to the mix - shared among all four cores. At 65nm, a quad-core Barcelona will have a 2MB L3 cache that is shared by all four cores.
The hierarchy in Barcelona works like this: the L2 caches are filled with victims from the L1 cache. When a cache gets full, data that was not recently used is evicted to make room for new data that the cache controller determines is good to keep in the cache. In a victim cache structure, the evicted data is placed in a storage area known as a victim cache instead of being removed from cache all together. If the data should become useful again, the cache controller simply has to fetch it from the victim cache rather than much slower main memory; victims from Barcelona's L1 are kicked out to the L2 cache.
The new L3 cache, acts as a victim for the L2 cache. So when the small L2 cache fills up, evicted data is sent to the larger L3 cache where it is kept until space is needed. The algorithms that govern the L3 cache's operation are designed to accommodate data that is likely to be needed by multiple cores. If the CPU fetches a bit of code, a copy is left in the L3 cache since the code is likely to be shared among the four cores. Pure data load requests however go through a separate process. The cache controller looks at history and if the data has been shared before, a copy will be left in the L3 cache; otherwise it will be invalidated.
Associativity hasn't been changed for the L1 and L2 caches; they are still 2-way and 16-way set associative, respectively. However, the new L3 cache is 32-way set associative. It has been designed to increase the hit rate of a relatively small cache compared to its competition.








83 Comments
View All Comments
TwistyKat - Friday, March 2, 2007 - link
I remember a comment an IBM exec made in an online interview a few years back when it indirectly implied that AMD would not be around in five years. It was unclear exactly what he meant by that.zsdersw - Thursday, March 1, 2007 - link
Fortunately for all of us, most people aren't like you.bamacre - Thursday, March 1, 2007 - link
Yup, AMD is selling at prices so low, they must be losing money. Dell isn't paying shlt for amd cpu's, as you can tell from their pricing.