Barcelona Architecture: AMD on the Counterattack
by Anand Lal Shimpi on March 1, 2007 12:05 AM EST- Posted in
- CPUs
Getting Spendy with Transistors - L3 cache
AMD lost the cache race to Intel long ago, but that's more of a result of manufacturing capacity than anything else. AMD knew it could not compete with Intel's ability to churn out more transistors on smaller processes faster, so it did the next best thing and integrated a memory controller. With the K8's on-die memory controller, AMD reduced the need for larger caches, which is why even current Athlon 64 X2s only have a 512KB L2 cache per core - a figure that Intel introduced back in 2002 with its Northwood core.
These days two Core 2 cores share up to 4MB of L2 cache, while the fastest offerings from AMD weigh in at half that. The gap will continue to widen with Barcelona, as each of its four cores will only have a 512KB L2 cache. While a quad-core Barcelona chip will have 2MB of total L2 cache for all four cores, a quad-core Kentsfield currently has 8MB of L2 cache for all four cores. By the end of this year, Intel's Penryn is expected to have 12MB of L2 cache for all of its cores.
In order to keep die sizes manageable, AMD constructed its quad-core Barcelona out of four cores each with a 128KB L1 and 512KB L2, much like most mainstream K8 based products today. However, the era of multithreaded applications demands that multi-core CPUs should have some common pool of high speed memory to keep them running at peak efficiency.
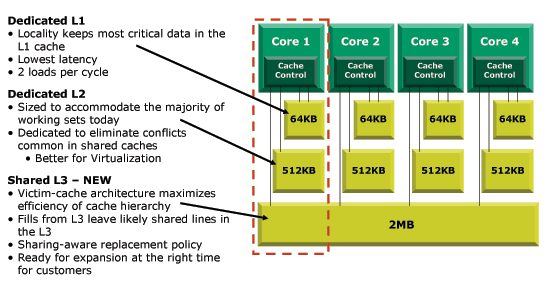
With four cores sharing a single die, AMD didn't want to complicate its design by introducing a large unified L2 cache. Instead, it took the K8 cache hierarchy and added a third level of cache to the mix - shared among all four cores. At 65nm, a quad-core Barcelona will have a 2MB L3 cache that is shared by all four cores.
The hierarchy in Barcelona works like this: the L2 caches are filled with victims from the L1 cache. When a cache gets full, data that was not recently used is evicted to make room for new data that the cache controller determines is good to keep in the cache. In a victim cache structure, the evicted data is placed in a storage area known as a victim cache instead of being removed from cache all together. If the data should become useful again, the cache controller simply has to fetch it from the victim cache rather than much slower main memory; victims from Barcelona's L1 are kicked out to the L2 cache.
The new L3 cache, acts as a victim for the L2 cache. So when the small L2 cache fills up, evicted data is sent to the larger L3 cache where it is kept until space is needed. The algorithms that govern the L3 cache's operation are designed to accommodate data that is likely to be needed by multiple cores. If the CPU fetches a bit of code, a copy is left in the L3 cache since the code is likely to be shared among the four cores. Pure data load requests however go through a separate process. The cache controller looks at history and if the data has been shared before, a copy will be left in the L3 cache; otherwise it will be invalidated.
Associativity hasn't been changed for the L1 and L2 caches; they are still 2-way and 16-way set associative, respectively. However, the new L3 cache is 32-way set associative. It has been designed to increase the hit rate of a relatively small cache compared to its competition.
AMD lost the cache race to Intel long ago, but that's more of a result of manufacturing capacity than anything else. AMD knew it could not compete with Intel's ability to churn out more transistors on smaller processes faster, so it did the next best thing and integrated a memory controller. With the K8's on-die memory controller, AMD reduced the need for larger caches, which is why even current Athlon 64 X2s only have a 512KB L2 cache per core - a figure that Intel introduced back in 2002 with its Northwood core.
These days two Core 2 cores share up to 4MB of L2 cache, while the fastest offerings from AMD weigh in at half that. The gap will continue to widen with Barcelona, as each of its four cores will only have a 512KB L2 cache. While a quad-core Barcelona chip will have 2MB of total L2 cache for all four cores, a quad-core Kentsfield currently has 8MB of L2 cache for all four cores. By the end of this year, Intel's Penryn is expected to have 12MB of L2 cache for all of its cores.
In order to keep die sizes manageable, AMD constructed its quad-core Barcelona out of four cores each with a 128KB L1 and 512KB L2, much like most mainstream K8 based products today. However, the era of multithreaded applications demands that multi-core CPUs should have some common pool of high speed memory to keep them running at peak efficiency.
With four cores sharing a single die, AMD didn't want to complicate its design by introducing a large unified L2 cache. Instead, it took the K8 cache hierarchy and added a third level of cache to the mix - shared among all four cores. At 65nm, a quad-core Barcelona will have a 2MB L3 cache that is shared by all four cores.
The hierarchy in Barcelona works like this: the L2 caches are filled with victims from the L1 cache. When a cache gets full, data that was not recently used is evicted to make room for new data that the cache controller determines is good to keep in the cache. In a victim cache structure, the evicted data is placed in a storage area known as a victim cache instead of being removed from cache all together. If the data should become useful again, the cache controller simply has to fetch it from the victim cache rather than much slower main memory; victims from Barcelona's L1 are kicked out to the L2 cache.
The new L3 cache, acts as a victim for the L2 cache. So when the small L2 cache fills up, evicted data is sent to the larger L3 cache where it is kept until space is needed. The algorithms that govern the L3 cache's operation are designed to accommodate data that is likely to be needed by multiple cores. If the CPU fetches a bit of code, a copy is left in the L3 cache since the code is likely to be shared among the four cores. Pure data load requests however go through a separate process. The cache controller looks at history and if the data has been shared before, a copy will be left in the L3 cache; otherwise it will be invalidated.
Associativity hasn't been changed for the L1 and L2 caches; they are still 2-way and 16-way set associative, respectively. However, the new L3 cache is 32-way set associative. It has been designed to increase the hit rate of a relatively small cache compared to its competition.








83 Comments
View All Comments
BitByBit - Tuesday, March 6, 2007 - link
One apparently overlooked detail of Barcelona's architecture is its instruction fetch ability: Barcelona is able to send 32 bytes (128 bits) to its decoders per cycle, where Core can send only 16 bytes to be decoded, increasing the likelihood of 'split fetch' cases in the latter. This means that, even if Core does have more raw FP power in terms of its execution units, Barcelona can expect greater utilisation of its FPUs/SSE, and the impact of this will be even more pronounced when running 64 bit code, due to the increased size of 64 bit instruction blocks. If Barcelona does, as expected, outperform Core in IPC in 32 bit mode, the performance gap may well increase in 64 bit mode.JarredWalton - Thursday, March 1, 2007 - link
Did you miss page 3? The SSE128 stuff largely deals with FP and cache improvements. Standard FP is still used, but most programs are optimizing for SSE2/3 as that can run circles around x87 FP performance.Spoelie - Thursday, March 1, 2007 - link
Is there no information on the bandwidth between the new caches? Or are they left the same? I'm only asking because last I read, Intel had a huge advantage in that department, with double or so the bandwidth between the caches. Isn't that important in FP-code, especially if you have to feed 4 cores (so the bw at the level 3 cache..)JarredWalton - Thursday, March 1, 2007 - link
Page 3: the cache bandwidth as I understand it should be doubled (128-bit vs. 64-bit), and several other areas have wider data paths as well. I think Intel has a 256-bit cache bus, so they still have more cache bandwidth, but as a whole it's difficult to say which will end up faster right now. The integrated memory controller has a lot of influence on a lot of areas, after all.Spoelie - Thursday, March 1, 2007 - link
K7 to K8 transition did the doubling of the 64bit interface to the 128bit one.. Core indeed has a 256bit interface (as far as I remember, even the P3 had a 256bit interface to L2). So according to page 3 the interface would be doubled again this time around?I'm only asking because I remember this quote from Johan De Gelas' article a while back.
"The Core architecture's L1 cache delivers about twice as much bandwidth (Measured by ScienceMark), while it's L2-cache is about 2.5 times faster than the Athlon 64/Opteron one."
And that must have *some* impact on performance. I think the bandwidth of the L3 cache will also be key, but haven't seen any official information about it.
BitByBit - Friday, March 2, 2007 - link
K8 had a 64-bit read and a 64-bit write path to its L2 cache, giving a total of 128 bits. Barcelona has a 128-bit read and 128-bit write path to its L2, giving a total of 256 bits - the same as Core.One thing that surprised me on the subject of cache was the associativity of the L1, which I had expected to see increased to 4-way. This would have allowed AMD to extend its lead in L1 hitrate and regain the ground lost in this area since the introduction of Core. Maybe we'll see an improvement to L1 associativity in future iterations of Barcelona.
haplo602 - Thursday, March 1, 2007 - link
Great article, was a very interesting read.Looks like I'll invest in an upgrade sometime beginning of 2008 when these new CPUs make their 2nd revision :-)
Gigahertz19 - Thursday, March 1, 2007 - link
Argh this article is such a cock tease. I read most of it but now I want some prelim benchies or some kind of numbers. Guess we'll have to wait till Mid-2007?I can't stand the anticipation, my girlfriend pulls this same shit every now and then, she'll get me going then quit and laugh....I always tell her I'll pull the same thing on her and see how she likes it but I can never gather up enough will power :)
MrJim - Thursday, March 1, 2007 - link
Hello Anand, great article as always. I suppose your much at home nowadays building your house etc. But when are we going to read more of your blogs or the relaunch of anandtech? I think the plan was to have many of the staff to have their own blogs?Hope you will write more often in the future!
slashbinslashbash - Thursday, March 1, 2007 - link
I agree, I would like to see more Anand blog entries. The blog currently doesn't seem to be working -- I can't pull up any of the older entries. I would like to go back and read through some of the old Macdates.