Barcelona Architecture: AMD on the Counterattack
by Anand Lal Shimpi on March 1, 2007 12:05 AM EST- Posted in
- CPUs
Getting Spendy with Transistors - L3 cache
AMD lost the cache race to Intel long ago, but that's more of a result of manufacturing capacity than anything else. AMD knew it could not compete with Intel's ability to churn out more transistors on smaller processes faster, so it did the next best thing and integrated a memory controller. With the K8's on-die memory controller, AMD reduced the need for larger caches, which is why even current Athlon 64 X2s only have a 512KB L2 cache per core - a figure that Intel introduced back in 2002 with its Northwood core.
These days two Core 2 cores share up to 4MB of L2 cache, while the fastest offerings from AMD weigh in at half that. The gap will continue to widen with Barcelona, as each of its four cores will only have a 512KB L2 cache. While a quad-core Barcelona chip will have 2MB of total L2 cache for all four cores, a quad-core Kentsfield currently has 8MB of L2 cache for all four cores. By the end of this year, Intel's Penryn is expected to have 12MB of L2 cache for all of its cores.
In order to keep die sizes manageable, AMD constructed its quad-core Barcelona out of four cores each with a 128KB L1 and 512KB L2, much like most mainstream K8 based products today. However, the era of multithreaded applications demands that multi-core CPUs should have some common pool of high speed memory to keep them running at peak efficiency.
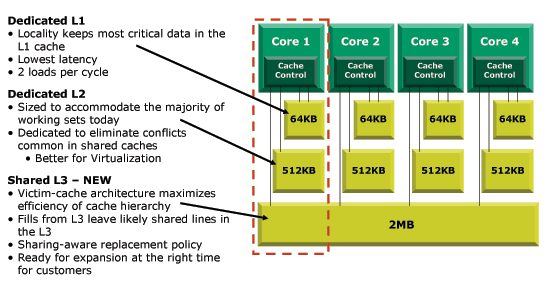
With four cores sharing a single die, AMD didn't want to complicate its design by introducing a large unified L2 cache. Instead, it took the K8 cache hierarchy and added a third level of cache to the mix - shared among all four cores. At 65nm, a quad-core Barcelona will have a 2MB L3 cache that is shared by all four cores.
The hierarchy in Barcelona works like this: the L2 caches are filled with victims from the L1 cache. When a cache gets full, data that was not recently used is evicted to make room for new data that the cache controller determines is good to keep in the cache. In a victim cache structure, the evicted data is placed in a storage area known as a victim cache instead of being removed from cache all together. If the data should become useful again, the cache controller simply has to fetch it from the victim cache rather than much slower main memory; victims from Barcelona's L1 are kicked out to the L2 cache.
The new L3 cache, acts as a victim for the L2 cache. So when the small L2 cache fills up, evicted data is sent to the larger L3 cache where it is kept until space is needed. The algorithms that govern the L3 cache's operation are designed to accommodate data that is likely to be needed by multiple cores. If the CPU fetches a bit of code, a copy is left in the L3 cache since the code is likely to be shared among the four cores. Pure data load requests however go through a separate process. The cache controller looks at history and if the data has been shared before, a copy will be left in the L3 cache; otherwise it will be invalidated.
Associativity hasn't been changed for the L1 and L2 caches; they are still 2-way and 16-way set associative, respectively. However, the new L3 cache is 32-way set associative. It has been designed to increase the hit rate of a relatively small cache compared to its competition.
AMD lost the cache race to Intel long ago, but that's more of a result of manufacturing capacity than anything else. AMD knew it could not compete with Intel's ability to churn out more transistors on smaller processes faster, so it did the next best thing and integrated a memory controller. With the K8's on-die memory controller, AMD reduced the need for larger caches, which is why even current Athlon 64 X2s only have a 512KB L2 cache per core - a figure that Intel introduced back in 2002 with its Northwood core.
These days two Core 2 cores share up to 4MB of L2 cache, while the fastest offerings from AMD weigh in at half that. The gap will continue to widen with Barcelona, as each of its four cores will only have a 512KB L2 cache. While a quad-core Barcelona chip will have 2MB of total L2 cache for all four cores, a quad-core Kentsfield currently has 8MB of L2 cache for all four cores. By the end of this year, Intel's Penryn is expected to have 12MB of L2 cache for all of its cores.
In order to keep die sizes manageable, AMD constructed its quad-core Barcelona out of four cores each with a 128KB L1 and 512KB L2, much like most mainstream K8 based products today. However, the era of multithreaded applications demands that multi-core CPUs should have some common pool of high speed memory to keep them running at peak efficiency.
With four cores sharing a single die, AMD didn't want to complicate its design by introducing a large unified L2 cache. Instead, it took the K8 cache hierarchy and added a third level of cache to the mix - shared among all four cores. At 65nm, a quad-core Barcelona will have a 2MB L3 cache that is shared by all four cores.
The hierarchy in Barcelona works like this: the L2 caches are filled with victims from the L1 cache. When a cache gets full, data that was not recently used is evicted to make room for new data that the cache controller determines is good to keep in the cache. In a victim cache structure, the evicted data is placed in a storage area known as a victim cache instead of being removed from cache all together. If the data should become useful again, the cache controller simply has to fetch it from the victim cache rather than much slower main memory; victims from Barcelona's L1 are kicked out to the L2 cache.
The new L3 cache, acts as a victim for the L2 cache. So when the small L2 cache fills up, evicted data is sent to the larger L3 cache where it is kept until space is needed. The algorithms that govern the L3 cache's operation are designed to accommodate data that is likely to be needed by multiple cores. If the CPU fetches a bit of code, a copy is left in the L3 cache since the code is likely to be shared among the four cores. Pure data load requests however go through a separate process. The cache controller looks at history and if the data has been shared before, a copy will be left in the L3 cache; otherwise it will be invalidated.
Associativity hasn't been changed for the L1 and L2 caches; they are still 2-way and 16-way set associative, respectively. However, the new L3 cache is 32-way set associative. It has been designed to increase the hit rate of a relatively small cache compared to its competition.








83 Comments
View All Comments
JustKidding - Friday, March 2, 2007 - link
So what you are saying is that it's not the size of your cache that matters as much as how well you use it.VooDooAddict - Thursday, March 1, 2007 - link
With Cache size differences usually having small impact on performance for Athlon64s, the slight trade off for better yields and margins seems the better choice for AMD here.
Regs - Thursday, March 1, 2007 - link
Where was this article 8 months ago? ;)I agree with Anands closing article that AMD now needs it's own "snowball effect" for the next couple of years. 4-5 years with a sitting target against a giant like Intel prooved to be costly in terms of competivness.
We all saw it coming when Intel developed the first Pentium M. It looks like AMD got the message as well and started the Barcelona project. Maybe AMD learned their lesson.
iwodo - Thursday, March 1, 2007 - link
So bascially all intel 's C2D improvement are made into Barcelona. And apart from Virtualization improvement there are nothing new from AMD that Intel doesn't have?On performance note Barcelona doesn't seem to offer better clock scaling. I.e even if it is 30% faster then its current K8 it will only have slight advantage against C2D clock per clock. Not to mention it is up against Penryn. Although Penryn is nothing much then a few minor tweaks and more cache. It does allow intel to scale higher in clock speed.
And given AMD slow roll out rate, and AMD limited production capacity Barcelona never seem like much of a threat.
The article does not mention anything about FP improvement. Are AMD keeping them secret for now or is that all we are going to see?
Spoelie - Thursday, March 1, 2007 - link
The FP improvement is the SSE improvement, and according to the theory it's more powerful than what core2 duo is offering.There are improvements mentioned that are not in core2 (+ other way around, like instruction fusing), and improvements that are inspired on the same principle but implemented differently. The architectures themselves differ widely (see earlier article that compares K8 with Core2 - reservation station etc.) so different implementations of principally the same optimizations on a different architecture will have vastly different effects. Even after these improvements, the capabilities (how much can you decode, etc) of each read nothing alike. And if it were all the same, AMD has the platform advantage, so it would still end up faster by virtue of nothing else but that. Some guesstimates made by varying sites would put Barcelona ahead in FP code and at the same level or slightly behind in INT code. But those are just guesstimates.
What I'm trying to say here is that barcelona is still very different from core2, and that we just don't know yet in which direction the pendulum will swing ;)
Shintai - Thursday, March 1, 2007 - link
No....precisely in theory is where Barcelona lacks. Core 2 Duo could in theory do 6 64bit or 3 128bit SSE instructions per cycle. Barcelona can do 4 64bit or 2 128bit. AMD provided this information aswell.Griswold - Thursday, March 1, 2007 - link
Wishful thinking.Spoelie - Thursday, March 1, 2007 - link
Hmmm, in the earlier article, there was explicit emphasis on the fact that 2 of the 3 units are symmetric in core2, but I'm not too sure what it means. It does imply however that those 3 units of core2 can only be used fully in certain combinations, and are not 3 independent units. On 128-bit performance, what was said is this: "so the Core architecture has essentially at least 2 times the processing power here [compared to K8]". Not 3 times, but "at least" 2 times, so again the 3 times will probably only be in certain situations.The next paragraph said this:
"With 64-bit FP, Core can do 4 Double Precision FP calculations per cycle, while the *Athlon64* can do 3."
So K8 was not at such a big disadvantage when it came to 64-bit SSE, if Barcelona doubles everything SSE, it should come ahead in this area.
So to me it looks like for 128-bit, core2 will be faster in some situations, on par in others, and for 64-bit, Barcelona would be ahead.
If this is wrong, I do not know where some of the articles I read over time came from, implying Barcelona would be better overall in SSE.
Shintai - Friday, March 2, 2007 - link
Core 2 got 3 individual SSE ports:http://www.realworldtech.com/page.cfm?ArticleID=RW...">http://www.realworldtech.com/page.cfm?ArticleID=RW...
AMD says 4 double:
http://www.anandtech.com/showdoc.aspx?i=2768&p...">http://www.anandtech.com/showdoc.aspx?i=2768&p...
And 64 or 128bit doesnt matter. I dont know how you think that way.
Barcelona got 2 SSE ports. They are able to do 2 128bit or 4 64bit. Most 128bit actually contains 2 64bit or 4 32bit.
Core 2 got 3 SSE ports. They are able to do 3 128bit or 6 64bit.
flyck - Friday, March 2, 2007 - link
core duo has 3 SSE units but they are not symmetric, meaning that not every unit can execute all commands. Core duo can do at best 4DP flops/ cycle. the same as barcelona.