Intel's Core 2 Extreme & Core 2 Duo: The Empire Strikes Back
by Anand Lal Shimpi on July 14, 2006 12:00 AM EST- Posted in
- CPUs
FSB Bottlenecks: Is 1333MHz Necessary?
Although all desktop Core 2 processors currently feature a 1066MHz FSB, Intel's first Woodcrest processors (the server version of Conroe) offer 1333MHz FSB support. Intel doesn't currently have a desktop chipset with support for the 1333MHz FSB, but the question we wanted answered was whether or not the faster FSB made a difference.
We took our unlocked Core 2 Extreme X6800 and ran it at 2.66GHz using two different settings: 266MHz x 10 and 333MHz x 8; the former corresponds to a 1066MHz FSB and is the same setting that the E6700 runs at, while the latter uses a 1333MHz FSB. The 1333MHz setting used a slightly faster memory bus (DDR2-811 vs. DDR2-800) but given that the processor is not memory bandwidth limited even at DDR2-667 the difference between memory speeds is negligible.
With Intel pulling in the embargo date of all Core 2 benchmarks we had to cut our investigation a bit short, so we're not able to bring you the full suite of benchmarks here to investigate the impact of FSB frequency. That being said, we chose those that would be most representative of the rest.
Why does this 1333MHz vs. 1066MHz debate even matter? For starters, Core 2 Extreme owners will have the option of choosing since they can always just drop their multiplier and run at a higher FSB without overclocking their CPUs (if they so desire). There's also rumor that Apple's first Core 2 based desktops may end up using Woodcrest and not Conroe, which would mean that the 1333MHz FSB would see the light of day on some desktops sooner rather than later.
The final reason this comparison matters is because in reality, Intel's Core architecture is more data hungry than any previous Intel desktop architecture and thus should, in theory, be dependent on a nice and fast FSB. At the same time, thanks to a well engineered shared L2 cache, FSB traffic has been reduced on Core 2 processors. So which wins the battle: the data hungry 4-issue core or the efficient shared L2 cache? Let's find out.
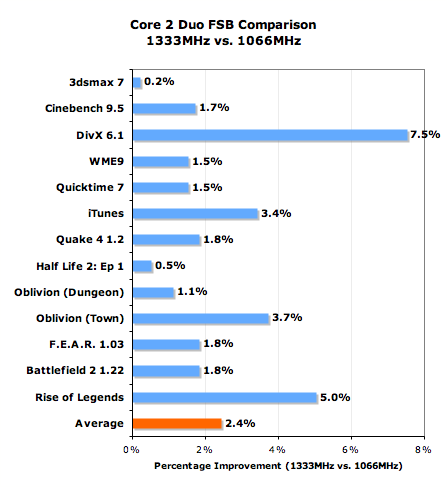
On average at 2.66GHz, the 1333MHz FSB increases performance by 2.4%, but some applications can see an even larger increase in performance. Under DivX, the performance boost was almost as high as going from a 2MB L2 to a 4MB L2. Also remember that as clock speed goes up, the dependence on a faster FSB will also go up.
Thanks to the shared L2 cache, core to core traffic is no longer benefitted by a faster FSB so the improvements we're seeing here are simply due to how data hungry the new architecture is. With its wider front end and more aggressive pre-fetchers, it's no surprise that the Core 2 processors benefit from the 1333MHz FSB. The benefit will increase even more as the first quad core desktop CPUs are introduced. The only question that remains is how long before we see CPUs and motherboards with official 1333MHz FSB support?
If Apple does indeed use a 1333MHz Woodcrest for its new line of Intel based Macs, running Windows it may be the first time that an Apple system will be faster out of the box than an equivalently configured, non-overclocked PC. There's an interesting marketing angle.








202 Comments
View All Comments
coldpower27 - Friday, July 14, 2006 - link
Are there supposed to be there as they aren't functioning in Firefox 1.5.0.4coldpower27 - Friday, July 14, 2006 - link
You guys fixed it awesome.Orbs - Friday, July 14, 2006 - link
On "The Test" page (I think page 2), you write:please look back at the following articles:
But then there are no links to the articles.
Anyway, Anand, great report! Very detailed with tons of benchmarks using a very interesting gaming configuration, and this review was the second one I read (so it was up pretty quickly). Thanks for not saccrificing quality just to get it online first, and again, great article.
Makes me want a Conroe!
Calin - Friday, July 14, 2006 - link
Great article, and thanks for a well done job. Conroe is everything Intel marketing machine shown it to be.stepz - Friday, July 14, 2006 - link
The Core 2 doesn't have smaller emoty latency than K8. You're seeing the new advanced prefetcher in action. But don't just believe me, check with the SM2.0 author.Anand Lal Shimpi - Friday, July 14, 2006 - link
That's what Intel's explanation implied as well, when they are working well the prefetchers remove the need for an on-die memory controller so long as you have an unsaturated FSB. Inevitably there will be cases where AMD is still faster (from a pure latency perspective), but it's tough to say how frequently that will happen.Take care,
Anand
stepz - Friday, July 14, 2006 - link
Excuse me. You state "Intel's Core 2 processors now offer even quicker memory access than AMD's Athlon 64 X2, without resorting to an on-die memory controller.". That is COMPLETELY wrong and misleading. (see: http://www.aceshardware.com/forums/read_post.jsp?i...">http://www.aceshardware.com/forums/read_post.jsp?i... )It would be really nice from journalistic integrity point of view and all that, if you posted a correction or atleast silently changed the article to not be spreading incorrect information.
Oh... and you really should have smelt something fishy when a memory controller suddenly halves its latency by changing the requestor.
stepz - Friday, July 14, 2006 - link
To clarify. Yes the prefetching and espescially the speculative memory op reordering does wonders for realworld performance. But then let the real-world performance results speak for themselves. But please don't use broken synthetic tests. The advancements help to hide latency from applications that do real work. They don't reduce the actual latency of memory ops that that test was supposed to test. Given that the prefetcher figures out the access pattern of the latency test, the test is utterly meaningless in any context. The test doesn't do anything close to realworld, so if its main purpose is broken, it is utterly useless.JarredWalton - Friday, July 14, 2006 - link
Modified comments from a similar thread further down:Given that the prefetcher figures out the access pattern of the latency test, the test is utterly meaningless in any context."
That's only true if the prefetcher can't figure out access patterns for all other applications as well, and from the results I'm pretty sure it can. You have to remember, even with the memory latency of approximately 35 ns, that delay means the CPU now has about 100 cycles to go and find other stuff to do. At an instruction fetch rate of 4 instructions per cycle, that's a lot of untapped power. So, while it waits on main memory access one, it can be scanning the next accesses that are likely to take place and start queuing them up and priming the RAM. The net result is that you may never actually be able to measure latency higher than 35-40 ns or whatever.
The way I think of it is this: pipeline issues aside, a large portion of what allowed Athlon 64 to outperform NetBurst was reduced memory latency. Remember, Pentium 4 was easily able to outperform Athlon XP in the majority of benchmarks -- it just did so at higher clock speeds. (Don't *even* try to tell me that the Athlon XP 3200+ was as fast as a Pentium 4 3.2 GHz! LOL. The Athlon 64 3200+ on the other hand....) AMD boosted performance by about 25% by adding an integrated memory controller. Now Intel is faster at similar clock speeds, and although the 4-wide architectural design helps, not to mention 4MB shared L2, they almost certainly wouldn't be able to improve performance without improving memory latency -- not just in theory, but in actual practice. Looking at the benchmarks, I have to think that our memory latency scores are generally representative of what applications see.
If you have to engineer a synthetic application specifically to fool the advanced prefetcher and op reordering, what's the point? To demonstrate a "worst case" scenario that doesn't actually occur in practical use? In the end, memory latency is only one part of CPU/platform design. The Athlon FX-62 is 61.6% faster than the Pentium XE 965 in terms of latency, but that doesn't translate into a real world performance difference of anywhere near 60%. The X6800 is 19.3% faster in memory latency tests, and it comes out 10-35% faster in real world benchmarks, so again there's not an exact correlation. Latency is important to look at, but so is memory bandwidth and the rest of the architecture.
The proof is in the pudding, and right now the Core 2 pudding tastes very good. Nice design, Intel.
coldpower27 - Friday, July 14, 2006 - link
But why are you posting the Manchester core's die size?What about the Socket AM2 Windsor 2x512KB model which has a die size of 183mm2?