Intel's Core 2 Extreme & Core 2 Duo: The Empire Strikes Back
by Anand Lal Shimpi on July 14, 2006 12:00 AM EST- Posted in
- CPUs
FSB Bottlenecks: Is 1333MHz Necessary?
Although all desktop Core 2 processors currently feature a 1066MHz FSB, Intel's first Woodcrest processors (the server version of Conroe) offer 1333MHz FSB support. Intel doesn't currently have a desktop chipset with support for the 1333MHz FSB, but the question we wanted answered was whether or not the faster FSB made a difference.
We took our unlocked Core 2 Extreme X6800 and ran it at 2.66GHz using two different settings: 266MHz x 10 and 333MHz x 8; the former corresponds to a 1066MHz FSB and is the same setting that the E6700 runs at, while the latter uses a 1333MHz FSB. The 1333MHz setting used a slightly faster memory bus (DDR2-811 vs. DDR2-800) but given that the processor is not memory bandwidth limited even at DDR2-667 the difference between memory speeds is negligible.
With Intel pulling in the embargo date of all Core 2 benchmarks we had to cut our investigation a bit short, so we're not able to bring you the full suite of benchmarks here to investigate the impact of FSB frequency. That being said, we chose those that would be most representative of the rest.
Why does this 1333MHz vs. 1066MHz debate even matter? For starters, Core 2 Extreme owners will have the option of choosing since they can always just drop their multiplier and run at a higher FSB without overclocking their CPUs (if they so desire). There's also rumor that Apple's first Core 2 based desktops may end up using Woodcrest and not Conroe, which would mean that the 1333MHz FSB would see the light of day on some desktops sooner rather than later.
The final reason this comparison matters is because in reality, Intel's Core architecture is more data hungry than any previous Intel desktop architecture and thus should, in theory, be dependent on a nice and fast FSB. At the same time, thanks to a well engineered shared L2 cache, FSB traffic has been reduced on Core 2 processors. So which wins the battle: the data hungry 4-issue core or the efficient shared L2 cache? Let's find out.
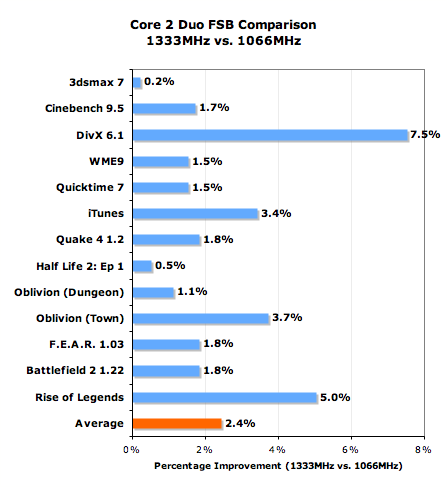
On average at 2.66GHz, the 1333MHz FSB increases performance by 2.4%, but some applications can see an even larger increase in performance. Under DivX, the performance boost was almost as high as going from a 2MB L2 to a 4MB L2. Also remember that as clock speed goes up, the dependence on a faster FSB will also go up.
Thanks to the shared L2 cache, core to core traffic is no longer benefitted by a faster FSB so the improvements we're seeing here are simply due to how data hungry the new architecture is. With its wider front end and more aggressive pre-fetchers, it's no surprise that the Core 2 processors benefit from the 1333MHz FSB. The benefit will increase even more as the first quad core desktop CPUs are introduced. The only question that remains is how long before we see CPUs and motherboards with official 1333MHz FSB support?
If Apple does indeed use a 1333MHz Woodcrest for its new line of Intel based Macs, running Windows it may be the first time that an Apple system will be faster out of the box than an equivalently configured, non-overclocked PC. There's an interesting marketing angle.








202 Comments
View All Comments
code255 - Friday, July 14, 2006 - link
Thanks a lot for the Rise of Legends benchmark! I play the game, and I was really interested in seeing how different CPUs perform in it.And GAWD DAMN the Core 2 totally owns in RoL, and that's only in a timedemo playback environment. Imagine how much better it'll be over AMD in single-player games where lots of AI calculations need to be done, and when the settings are at max; the high-quality physics settings are very CPU intensive...
I've so gotta get a Core 2 when they come out!
Locutus465 - Friday, July 14, 2006 - link
It's good to see intel is back. Now hopefully we'll be seeing some real innovation in the CPU market again. I wonder what the picture is going to look like in a couple years when I'm ready to upgrade again!Spoonbender - Friday, July 14, 2006 - link
First, isn't it misleading to say "memory latency" is better than on AMD systems?What happens is that the actual latency for *memory* access is still (more or less) the same. But the huge cache + misc. clever tricks means you don't have to go all the way to memory as often.
Next up, what about 64-bit? Wouldn't it be relevant to see if Conroe's lead is as impressive in 64-bit? Or is it the same horrible implementation that Netburst used?
JarredWalton - Friday, July 14, 2006 - link
Actually, it's the "clever tricks" that are reducing latency. (Latency is generally calculated with very large data sets, so even if you have 8 or 16 MB of cache the program can still determine how fast the system memory is.) If the CPU can analyze RAM access requests in advance and queue up the request earlier, main memory has more time to get ready, thus reducing perceived latency from the CPU. It's a matter of using transistors to accomplish this vs. using them elsewhere.It may also be that current latency applications will need to be adjusted to properly compute latency on Core 2, but if their results are representative of how real world applications will perceive latency, it doesn't really matter. Right now, it appears that Core 2 is properly architected to deal with latency, bandwidth, etc. very well.
Spoonbender - Friday, July 14, 2006 - link
Well, when I think of latency, I think worst-case latency, when, for some reason, you need to access something that is still in memory, and haven't already been queued.Now, if their prefetching tricks can *always* start memory loads before they're needed, I'll agree, their effective latency is lower. But if it only works, say, 95% of the time, I'd still say their latency is however long it takes for me to issue a memory load request, and wait for it to get back, without a cache hit, and without the prefetch mechanism being able to kick in.
Just technical nitpicking, I suppose. I agree, the latency that applications will typcially perceive is what the graph shows. I just think it's misleading to call that "memory latency"
As you say, it's architected to hide the latency very well. Which is a damn good idea. But that's still not quite the same as reducing the latency, imo.
Calin - Friday, July 14, 2006 - link
You could find the real latency (or most of it) by reading random locations in the main memory. Even the 4MB cache on the Conroe won't be able to prefetch all the main memory.Anyway, the most interesting is what memory latency the application that run feels. This latency might be lower on high-load, high-memory server processors (not that current benchmarks hint at this for Opteron against server-level Core2)
JarredWalton - Friday, July 14, 2006 - link
"You could find the real latency (or most of it) by reading random locations in the main memory."I'm pretty sure that's how ScienceMark 2.0 calculates latency. You have to remember, even with the memory latency of approximately 35 ns, that delay means the CPU now has approximately 100 cycles to go and find other stuff to do. At an instruction fetch rate of 4 instructions per cycle, that's a lot of untapped power. So, while it waits on main memory access one, it can be scanning the next accesses that are likely to take place and start queuing them up. And the net result is that you may never actually be able to measure latency higher than about 35 ns or whatever.
The way I think of it is this: pipeline issues aside, a large portion of what allowed Athlon 64 to outperform at first was reduced memory latency. Remember, Pentium 4 was easily able to outperform Athlon XP in the majority of benchmarks -- it just did so at higher clock speeds. (Don't *even* try to tell me that the Athlon XP 3200+ was as fast as a Pentium 4 3.2 GHz... LOL.) AMD boosted performance by about 25% by adding an integrated memory controller. Now Intel is faster at similar clock speeds, and although the 4-wide architectural design helps, they almost certainly wouldn't be able to improve performance without improving memory latency -- not just, but in actual practice. With us, I have to think that our memory latency scores are generally representative of what applications see. All I can say is, nice design Intel!
JarredWalton - Friday, July 14, 2006 - link
"...allowed Athlon 64 to outperform at first was...."Should be:
"...allowed Athlon 64 to outperform NetBurst was..."
Bad Dragon NaturallySpeaking!
yacoub - Friday, July 14, 2006 - link
""Another way of looking at it is that Intel's Core 2 Duo E6600 is effectively a $316 FX-62".Then the only question that matters at all for those of us with AMD systems is: Can I get an FX-62 for $316 or less (and run it on my socket-939 board)? If so, I would pick one up. If not, I would go Intel.
End of story.
Gary Key - Friday, July 14, 2006 - link
A very good statement. :)