Platform Strategy: 4x4, Torrenza, Trinity, and Raiden
It wouldn't be fair to completely ignore AMD Live!, as there was a fair amount of time spent talking about it. Unfortunately, AMD Live! is much like Intel's VIIV. That is to say, the "technology" is more of a suggestion about what components to include in computers built for a specific purpose in order to assist in the marketing of an idea. Certainly, the "computer as media center" idea isn't something new. Intel and AMD simply enabled the magic co-branding fairy to make end users feel all warm and squishy inside about their purchase. To be fair, mindshare is a large part of the game, and Centrino has served Intel very well on the mobile front (though I wish this early Centrino I've got had been a Pentium-M with onboard 802.11g).
Moving on, there were some very high powered (as in power draw) announcements. First off, AMD is pushing a new high end enthusiast platform consisting of dual socket motherboards for dual core processors combined with quad GPU solutions. In an incredibly unoriginal moment of indiscretion, this platform has been dubbed 4x4. Uninspired, yet very appropriate: the platform will very likely be large, loud, and so power hungry we will need a gas powered generator to run it. That doesn't mean we wouldn't want to own a system. We just aren't sure we'd want to pay for it.
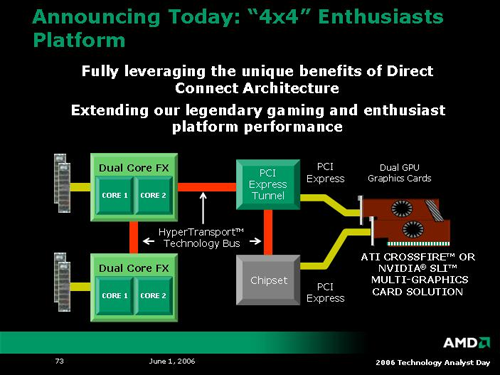
So, the first question we asked about 4x4 was: how much different is this than taking an off the shelf 2P board and dropping in a couple 2xx series Opteron processors with NVIDIA's quad SLI? Unfortunately, we haven't gotten any answer other than to say that there is something that makes it different. From what we understand, 4x4 will support unbuffered DIMMS (while Opterons still require registered memory), and the platform will be focused towards tweakable motherboards. We are looking into all the details. While the more power! kick is always interesting, we have to wonder if there will be any software in the near term that can really harness all this raw potential.
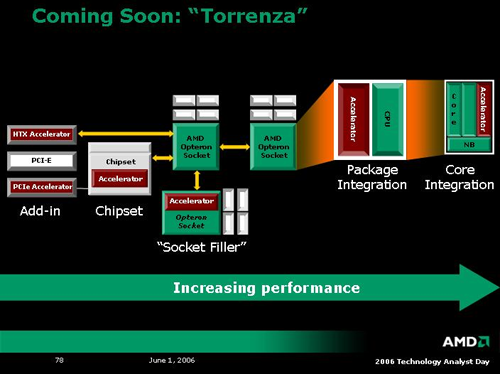
Stepping past the enthusiast platform, we have arguably the most exciting announcement of the day: Torrenza. Along with K8L, AMD plans on openly licensing it's (until now proprietary) coherent HyperTransport technology. At first glance, this may not seem exciting, but AMD is throwing in a little twist: HTX slots. These HTX slots will be standard interfaces connected directly to an AMD CPU's HyperTransport link. If both of these links are coherent, the device and the CPU will be able to communicate directly with each other with cache coherency. Because of this, latency can be reduced greatly over other buses as well, enabling hardware vendors to begin to create true coprocessor technology once again.

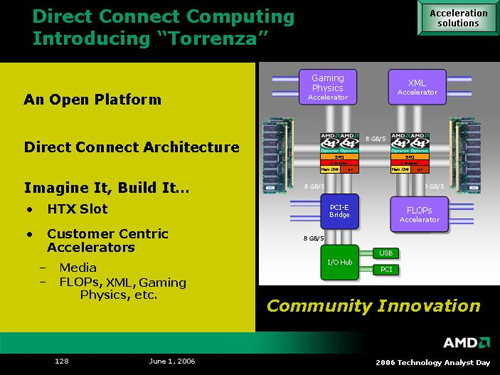
In addition to the flexibility of allowing the addition of such "accelerators" (as AMD calls them) to be added in via HTX slots, the architecture of the K8L line will be flexible enough that AMD could choose to incorporate some of these coprocessor technologies on a CPU package, or even on a CPU die itself. This is possible because the interconnect interface is the same at any level of integration. Not only will companies be able to develop their own unique solutions to extend the capabilities of the system processor, but it may even be possible to see such technology integrated into future AMD parts at a more fundamental level.
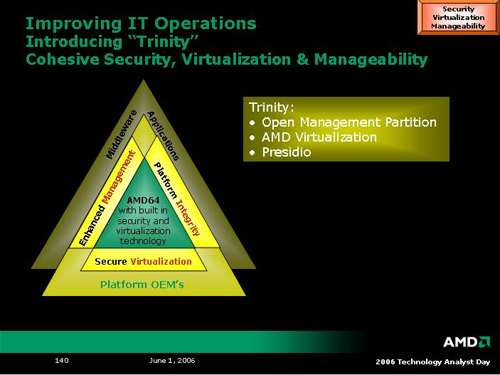
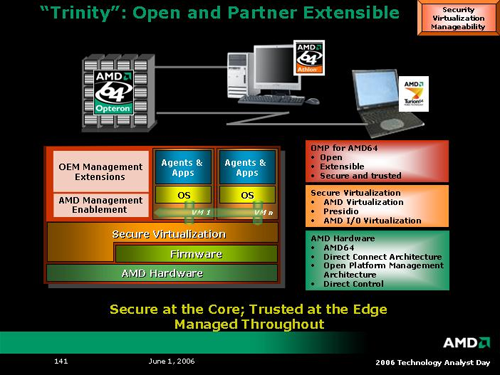
The next two platform level technologies AMD spoke on are named Trinity and Raiden. At many levels, Raiden seems more like an AMD Live! style initiative enabled by Trinity and other technologies, but we're getting ahead of ourselves. At its core, Trinity is AMD's platform level support for hardware virtualization. In addition to previously introduced Pacifica technology, AMD is working with the PCISIG to develop advanced I/O virtualization in addition to enhancing security and manageability of virtualized hardware at every level. The actual hardware that will enable Trinity wasn't explicitly expounded upon, but we did get these two slides with a brief description of how security, manageability and virtualization can't be handled as three separate problems.
Moving on to Raiden, AMD wishes to change the way businesses look at the way they provide computing to their employees. Rather than hardware, AMD believes businesses would be better served by focusing on compute cycles. Server and PC hardware can be setup in blade-like configurations, and employees can run thin clients which stream their OS from the compute server. Ideally, the reality of where their "compute power" comes from won't be important to the end user as long as there was no difference in experience. Having a large number of under utilized computers is a cost companies could avoid by sharing the processing power of fewer machines over a large number of people.
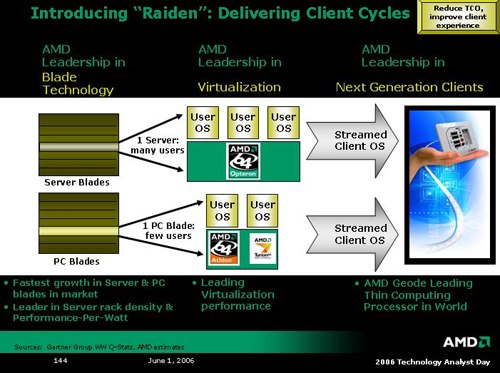
If there is any technology that is Raiden specific, AMD was not forthcoming. From what we can tell, AMD will leverage the current enthusiasm over blade systems and its Trinity virtualization platform to push customers toward a centralized computational model on the basis of power and cost savings. Certainly the benefits are there if the technology can support it, and hopefully we will be able to get some clarification on how Raiden translates to actual hardware.
It wouldn't be fair to completely ignore AMD Live!, as there was a fair amount of time spent talking about it. Unfortunately, AMD Live! is much like Intel's VIIV. That is to say, the "technology" is more of a suggestion about what components to include in computers built for a specific purpose in order to assist in the marketing of an idea. Certainly, the "computer as media center" idea isn't something new. Intel and AMD simply enabled the magic co-branding fairy to make end users feel all warm and squishy inside about their purchase. To be fair, mindshare is a large part of the game, and Centrino has served Intel very well on the mobile front (though I wish this early Centrino I've got had been a Pentium-M with onboard 802.11g).
Moving on, there were some very high powered (as in power draw) announcements. First off, AMD is pushing a new high end enthusiast platform consisting of dual socket motherboards for dual core processors combined with quad GPU solutions. In an incredibly unoriginal moment of indiscretion, this platform has been dubbed 4x4. Uninspired, yet very appropriate: the platform will very likely be large, loud, and so power hungry we will need a gas powered generator to run it. That doesn't mean we wouldn't want to own a system. We just aren't sure we'd want to pay for it.
So, the first question we asked about 4x4 was: how much different is this than taking an off the shelf 2P board and dropping in a couple 2xx series Opteron processors with NVIDIA's quad SLI? Unfortunately, we haven't gotten any answer other than to say that there is something that makes it different. From what we understand, 4x4 will support unbuffered DIMMS (while Opterons still require registered memory), and the platform will be focused towards tweakable motherboards. We are looking into all the details. While the more power! kick is always interesting, we have to wonder if there will be any software in the near term that can really harness all this raw potential.
Stepping past the enthusiast platform, we have arguably the most exciting announcement of the day: Torrenza. Along with K8L, AMD plans on openly licensing it's (until now proprietary) coherent HyperTransport technology. At first glance, this may not seem exciting, but AMD is throwing in a little twist: HTX slots. These HTX slots will be standard interfaces connected directly to an AMD CPU's HyperTransport link. If both of these links are coherent, the device and the CPU will be able to communicate directly with each other with cache coherency. Because of this, latency can be reduced greatly over other buses as well, enabling hardware vendors to begin to create true coprocessor technology once again.
In addition to the flexibility of allowing the addition of such "accelerators" (as AMD calls them) to be added in via HTX slots, the architecture of the K8L line will be flexible enough that AMD could choose to incorporate some of these coprocessor technologies on a CPU package, or even on a CPU die itself. This is possible because the interconnect interface is the same at any level of integration. Not only will companies be able to develop their own unique solutions to extend the capabilities of the system processor, but it may even be possible to see such technology integrated into future AMD parts at a more fundamental level.
The next two platform level technologies AMD spoke on are named Trinity and Raiden. At many levels, Raiden seems more like an AMD Live! style initiative enabled by Trinity and other technologies, but we're getting ahead of ourselves. At its core, Trinity is AMD's platform level support for hardware virtualization. In addition to previously introduced Pacifica technology, AMD is working with the PCISIG to develop advanced I/O virtualization in addition to enhancing security and manageability of virtualized hardware at every level. The actual hardware that will enable Trinity wasn't explicitly expounded upon, but we did get these two slides with a brief description of how security, manageability and virtualization can't be handled as three separate problems.
Moving on to Raiden, AMD wishes to change the way businesses look at the way they provide computing to their employees. Rather than hardware, AMD believes businesses would be better served by focusing on compute cycles. Server and PC hardware can be setup in blade-like configurations, and employees can run thin clients which stream their OS from the compute server. Ideally, the reality of where their "compute power" comes from won't be important to the end user as long as there was no difference in experience. Having a large number of under utilized computers is a cost companies could avoid by sharing the processing power of fewer machines over a large number of people.
If there is any technology that is Raiden specific, AMD was not forthcoming. From what we can tell, AMD will leverage the current enthusiasm over blade systems and its Trinity virtualization platform to push customers toward a centralized computational model on the basis of power and cost savings. Certainly the benefits are there if the technology can support it, and hopefully we will be able to get some clarification on how Raiden translates to actual hardware.








40 Comments
View All Comments
peternelson - Saturday, June 3, 2006 - link
High end pcie cards are available if you look for them
eg Areca 8 sata II onto 8x pci express
eg Myrinet 10 gigabit ethernet onto 8x pci express
Plenty of other examples.
Also, witness the highend server boards many are now offering pcie as an option to the former server standard pci-x.
PCIE is here to stay and is a must for anyone interested in a performance system.
There is a direct mapping of pcie onto Hypertransport.
There is already fast networking available on an HTX card.
lopri - Friday, June 2, 2006 - link
Correction: ..video card.. transfers data via PCI Express..;)
saratoga - Friday, June 2, 2006 - link
I'm a little confused. IIRC Core2 can do 2x 128 bit operations, each of which can be an add or multiply, but only one of which can be a load. AMD is restricting the actual operations to just 1 add and 1 multiply, but is removing the restriction on loads? So they'll be better able to feed the vector units then Intel, but have less flexibility once they've loaded?
That doesn't make a whole lot of sense to me. I'd think if their SSE implementation was less agressive, they would not have added more load units to feed it. Has AMD confirmed that there are only 1 add and 1 mult unit? Or is this a case of Intel designing a nice backend and not providing the front end resources to keep it fed?
mino - Friday, June 2, 2006 - link
Well, you're kinda right and wrong at the same time:)However intel's C2 frontend(from L2 up) is far superior to AMD's. And was such since Banias. Also intel's backend(execution units) is now on par but only recently Yonah and older were inferior to AMD's brute force 3-issue backend.
AMD has kinda ingeniously hidden poor backend by IMC however for streamed(desktop) pseudo-random loads intel's huge cache structures mitigated this so they are forced to improve frontend(hard to do) and do some backend optimizations(easy) on the way. Well, they kinda knew they will have to do this since the 90's, they have just chosen to implement IMC and cater to the core itself in the next iteration.
On the 2load units - without them the maxFLOPS would be n, real one x. With them(load units are relatively simple and low power compared to FPU's) they've got MmaxFLOPS around 2n AND real achievable one(IMHO) in the 1.2x~1.5x range. Pretty good ROI for the one added load unit.
saratoga - Saturday, June 3, 2006 - link
Could you explain how?
No it wouldn't. CPUs have registers, so the number of load units has nothing to do with FLOPs. You could have just one load unit and still sustain an arbitrary number of FLOPs, provided you didn't mind using the same registers over and over again, which I suppose could be the case if you're doing an iterative approximation of a value.
I don't think loads count as FLOPs, even if you're loading things to be used in FP operations, so having more load units doesn't increase max FLOPs.
mino - Friday, June 2, 2006 - link
Sory for the english, grammar wasn't my friend :)DigitalFreak - Friday, June 2, 2006 - link
The smartest thing AMD ever did was create HyperTransport. There are so many cool uses for it! Intel, on the other hand, still insists on using their proprietary solutions.DerekWilson - Friday, June 2, 2006 - link
HyperTransport was created by an open consortium.But you do have to remember that AMD implimented a propreitary coherent HT for use in SMP systems. They haven't always been open, even if their method was implimented on top of an open standard.
I do agree that general use of HyperTransport makes I/O much easier on many levels, and was a very good move for AMD. And now that they are opening up cHT, some really cool things can happen -- if the industry is ready. :-)
Viditor - Saturday, June 3, 2006 - link
Actually, it was created by AMD, it was developed by an open consortium.
However coherent HT is still (at least until now) proprietary AMD...
Viditor - Saturday, June 3, 2006 - link
Doh! I need to read first, post second...already asked and answered. Sorry...