Out of Order execution: AMD versus Intel
To make this article more accessible and to make the differences between the AMD K8 and the new Intel Core architecture more clear, I tried to make both CPU diagrams in the same style. Here's the Core architecture overview: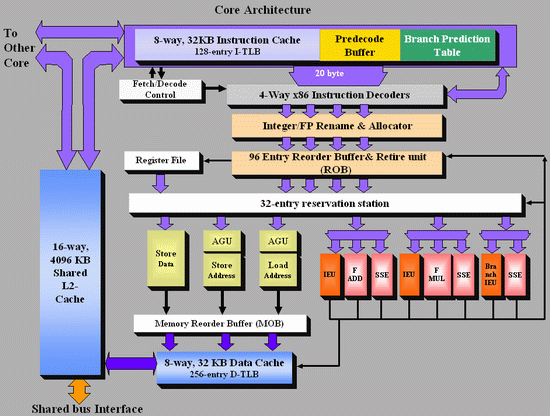
And here's the K8 architecture:
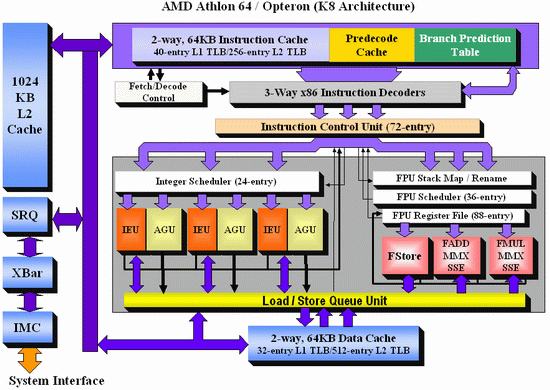
There are a few obvious differences: Core has bigger OoO buffers: the 96 entry ROB buffer is - also thanks to Macro-op fusion - quite a bit bigger than the 72 Entry Macro-op buffer of K8. The P6 architecture could order only 40 instructions, this was doubled to 80 in the P-M architecture (Banias, Dothan, Yonah), and now it's increased even further to 96 for the Core architecture. We've created a table which compares the most important architectural details of several current CPU families:
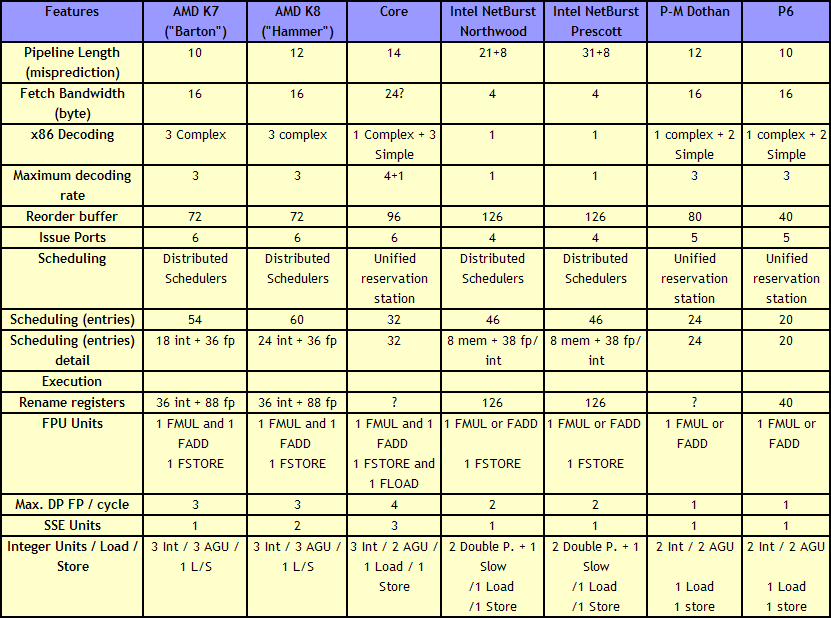 |
| Click to enlarge |
The Core architecture uses a central reservation station, while the Athlon uses distributed schedulers. The advantage of a central reservation station is that utilization is better, however distributed schedulers allow more entries. NetBurst also uses distributed schedulers.
Using a central reservation station is another clear example of how Core is in fact the "P8", the second big improvement of the P6 architecture. Just like the P6 architecture, it uses a Reservation Station (RS) and allocates a specific execution unit to execute the micro-op. After execution, the micro-op results are stored in the ROB entry for that micro-op. This aspect of the Core design is clearly taken from the Yonah, Dothan and P6 architectures.
The biggest differences are not immediately visible on the diagrams above. Previous Intel architectures can only perform one branch prediction every two cycles, but Core can sustain one branch per cycle. The Athlon 64 can also perform one branch prediction per cycle.
Another impressive area is Core's SSE multimedia power. Three very powerful 128-bit SSE/SSE2/SSE3 units are available, and two of them are symmetric. Core will outperform the Athlon 64 vastly when it comes to 128-bit SSE2/3 processing.
On K8, 128-bit SSE instructions are decoded into two separate 64-bit instructions. Each Athlon 64 SSE unit can only do one 64-bit instruction at a time, so the Core architecture has essentially at least 2 times the processing power here. With 64-bit FP, Core can do 4 Double Precision FP calculations per cycle, while the Athlon 64 can do 3.
When it comes to integer execution resources, the Core architecture is an improvement over the Pentium 4 and Dothan CPUs, and is at the same level (if we only look at the number of execution units) as the Athlon 64. The Athlon 64 seems to have a small advantage when it comes to calculating addresses: it has 3 AGU compared to Core's 2. This could give the Athlon 64 an advantage in some less common integer workloads such as decrypting algorithms. The deeper, more flexible (Memory disambiguation, see further) out of order buffers and bigger, faster L2-cache of the Core should negate this small advantage in most integer workloads.








87 Comments
View All Comments
Betwon - Wednesday, May 3, 2006 - link
Without branch prediction, K8 will become very very poor. Too terrible!The prediction is much better than the forever penalty.
The penalty of disprediction is just the penalty of doing nothing.(don't predict)
The penalty is fairly high. If you are against the prediction, you will find that the penalty will happen in K8 every 3 instructions averagely. K8@1.8G(without branch predictor ) will fail to win the old Pentium3@1G(with branch predictor ).
This is the drawback of lack of prediction, whether branches or memory access: It can not speeds up anything, but often slows down.
Without branch prediction, K8 will be down!
Betwon - Wednesday, May 3, 2006 - link
It is very interesting that the P4's Load/store/Memory reordering method, which is very different with Core's.For P4, it always assumes that all load-ops can hit and find the load data from the store buffer or L1 data cache.
Before one load-op is executed, it has to obtain the load address and all prior-store address and compare with them. If it is found that the load address is equal to one prior-store address, the load-op will assume that the store data is in the store buffer and the data has been ready and vaild, then start to execute speculatively.
If the address-euqal is not found, the load-op will assume that the load data is in L1 data cache, and the data is ready and vaild, then start to execute speculatively.
If the speculation fail or the miss happen, the speculative load-op and the relative speculative micro-ops have to be reexecuted -- it is called as 'replay'.
The load-op can be executed speculatively, after it knew it's load address and compared the load address with the all prior-store address.
The load-op can not be executed speculatively before it knew it's load address and compared the load address with the all prior-store address.
The load-op speculates whether the load data is ready and vaild, but not speculate whether there is the true dependency with prior-store.
But Core can speculate whether there is the true dependency with prior-store. Core has the smart predictor which can predict the store-to-load dependency precisely, before the load-op address is compared with the prior-store address.
Betwon - Wednesday, May 3, 2006 - link
If you really want to know what is the Intel's load reordering and memory misambiguation, I can tell you the facts:http://www.stanford.edu/~merez/papers/LoadSched_IS...">http://www.stanford.edu/~merez/papers/LoadSched_IS...
Speculation Techniques for Improving Load Related Instruction Scheduling 1999
Adi Yoaz, Mattan Erez, Ronny Ronen, and Stephan Jourdan -- From Intel's Haifa, they designed the Load/Store Unit of Core.
I had said that anandtech should study many things about CPU. Of course, I should study more things about CPU.
Betwon - Wednesday, May 3, 2006 - link
sub ebp,ebpmov ecx, 1000000000
B1:
mov eax,[ebx]
sub esi,1
sub edi,1
cmp ecx,ebp
je B2
mov edx,[ebx]
sub esi,1
sub edi,1
cmp ecx,ebp
je B2
mov eax,[ebx]
sub esi,1
sub edi,1
cmp ecx,ebp
je B2
mov edx,[ebx]
sub esi,1
sub edi,1
cmp ecx,ebp
je B2
mov eax,[ebx]
sub esi,1
sub edi,1
cmp ecx,ebp
je B2
mov edx,[ebx]
sub ecx,1
sub edi,1
cmp ebp,ebp
je B1
B2:
If the asm codes take 6000000000 cycles --> up to five x86 instructions at a time.
It is so easy to verify.
we can not call K5 -- 4 decoders, because it is too immature.
emboss - Monday, May 1, 2006 - link
I'm not even sure the Core architecture has 4 decoders. There's lots of references in the Intel Optimisation manual to say that there's still only three (two simple + one complex):"On Intel Core Solo and Intel Core Duo processors, decoding of most packed SSE instructions is done by all three decoders. As a result the front end can process up to three packed SSE instructions every cycle." (page 1-32)
"Improvement in decoder and micro-op fusion allows the front end to see most instructions as single µop instructions. This increases the throughput of the three decoders in the front end." (page 1-31)
While it certainly wouldn't be the first time Intel manuals have been wrong, they're usually reasonably accurate.
Also from the optimisation manual, it implies that the front end/decoder doing the fusion (for example, see the second quote above).
JarredWalton - Monday, May 1, 2006 - link
Not sure if you're referring to Core Solo/Duo manuals or to Core "Conroe/Merom" manuals. The article is covering the *next* Core architecture, so I wouldn't be at all surprised if Core Duo only has 3 decoders while Conroe bumps that to 4.emboss - Monday, May 1, 2006 - link
Oops, yes, my mistake. I was referring to Solo/Duo. Damn those marketers :)This still leaves me puzzled over the unexpected SSE performance on Solo/Duo. Thinking about it a bit more, the performance would have been 4x "expected" (single uop SSE with two FADD units vs double uop SSE with only one FADD unit), whereas I was only getting a bit less than double. Gnah, back to emperical optimisation.
Furen - Monday, May 1, 2006 - link
Yes, Yonah only has 3 decoders (and the same port arrangement as Dothan, too).Loki726 - Monday, May 1, 2006 - link
Great job Johan!Its articles like this that keep anandtech head and shoulders above everyone else. Instead of just running the latest and greatest core you get through the same old benchmarks and throwing some pretty comparison graphs at the reader, you actually take the time to figure out what parts of the architecture contribute to the performance you see in benchmarks. Keep it up!
On a small side note, on your first figure of intel's core architecture on page 4, I think the cache size should be 4096kb. 4gb seems rather large...
Goi - Monday, May 1, 2006 - link
Nice read. Did you get all your information solely from Jack Doweck, or are there papers outlining the Core architecture. I've read those for the Pentium-M and Netburst architecture(as well as several other architectures) but I haven't seen one of the Core yet.