AMD's Ryzen 9 6900HS Rembrandt Benchmarked: Zen3+ Power and Performance Scaling
by Dr. Ian Cutress on March 1, 2022 9:30 AM ESTCPU Tests: SPEC Performance
SPEC2017 is a series of standardized tests used to probe the overall performance between different systems, different architectures, different microarchitectures, and setups. The code has to be compiled, and then the results can be submitted to an online database for comparison. It covers a range of integer and floating point workloads, and can be very optimized for each CPU, so it is important to check how the benchmarks are being compiled and run.
For compilers, we use LLVM both for C/C++ and Fortran tests, and for Fortran we’re using the Flang compiler. The rationale of using LLVM over GCC is better cross-platform comparisons to platforms that have only have LLVM support and future articles where we’ll investigate this aspect more. We’re not considering closed-sourced compilers such as MSVC or ICC.
clang version 10.0.0
clang version 7.0.1 (ssh://git@github.com/flang-compiler/flang-driver.git
24bd54da5c41af04838bbe7b68f830840d47fc03)-Ofast -fomit-frame-pointer
-march=x86-64
-mtune=core-avx2
-mfma -mavx -mavx2
Our compiler flags are straightforward, with basic –Ofast and relevant ISA switches to allow for AVX2 instructions. We decided to build our SPEC binaries on AVX2, which puts a limit on Haswell as how old we can go before the testing will fall over. This also means we don’t have AVX512 binaries, primarily because in order to get the best performance, the AVX-512 intrinsic should be packed by a proper expert, as with our AVX-512 benchmark. All of the major vendors, AMD, Intel, and Arm, all support the way in which we are testing SPEC.
To note, the requirements for the SPEC licence state that any benchmark results from SPEC have to be labeled ‘estimated’ until they are verified on the SPEC website as a meaningful representation of the expected performance. This is most often done by the big companies and OEMs to showcase performance to customers, however is quite over the top for what we do as reviewers.
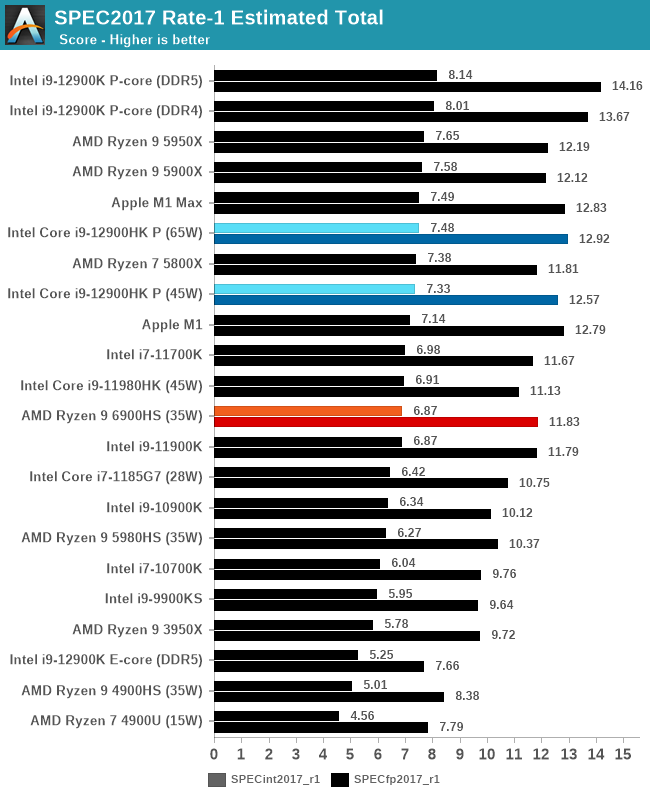
In the single threaded test, the jump over the regular Zen 3 Ryzen mobile variant (5980HS) at the same power is quite substantial: +9.6% on integer performance and +14.1% on floating point. The move from DDR4 to DDR5 is quite substantial in that regard, and it’s seen in a lot of our upcoming benchmarks.
We didn’t see any change from 35 W to 45 W to 65 W in our AMD testing as the power consumption of the chip in single threaded workloads did not exceed 24 W, however we did see performance difference in Intel’s Alder Lake going from 45 W to 65 W, showcasing how much power the core can consume.
But if we compared that to Intel’s latest Alder Lake offerings, there’s a deficit in both categories – even though our lowest data here is at 45 W, we can see that the 45 W testing of the previous generation Intel also beats the 6900HS at SPECint (but AMD wins in SPECfp). This is something that carries through to multi-threaded performance.
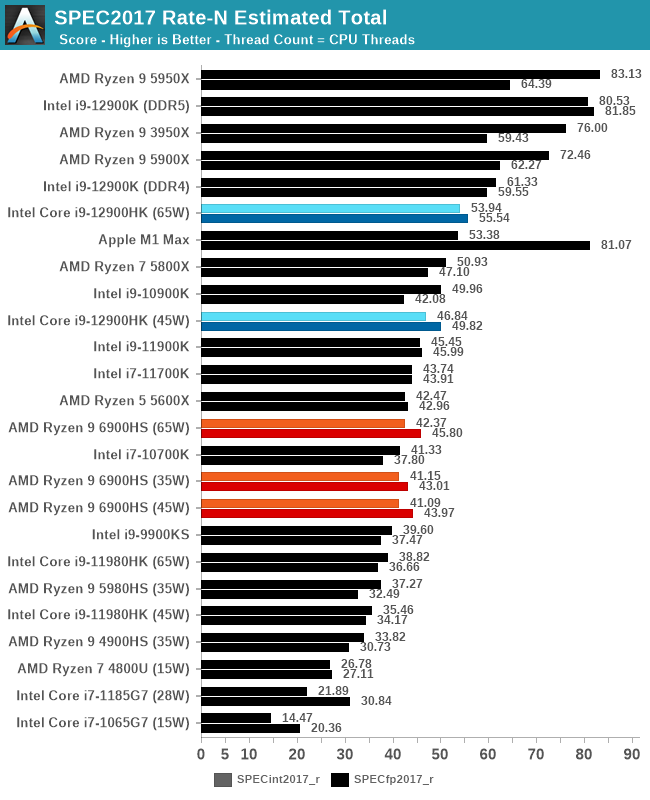
For Multi-Threaded performance, we only saw the slightest improvement from AMD moving up to 65 W, perhaps showcasing that the hardware is limited in other ways than just power and the uplift from DDR4 to DDR5. In any event, at 35 W, AMD still surpasses what the previous generation Intel i9-11980HK can provide at 65 W.
But if we compare it to Intel’s latest Alder Lake processors, featuring 6 performance cores and 8 efficiency cores, we now have 20 threads up against AMD’s 16 threads. If we compare 45 W to 45 W, Intel has a +14.0% lead in integer and a +13.3% lead in floating point, despite the 20% increase in threads. With Intel introducing this dual tier performance with hybrid SoCs, multi-threaded performance is going to be a combination of fast+slow and it all comes down to how the system can divide up the work.








92 Comments
View All Comments
mode_13h - Thursday, March 24, 2022 - link
> Mulholland Drive is perhaps my favourite film of all films.After your last post, I was already going to start (re-)watching Lynch's films, but maybe I'll start there.
GeoffreyA - Monday, March 28, 2022 - link
MD is the best. All his other films tend to be something of a mess or too obscure or too excessive. In particular, I despise Lost Highway. Straight Story is good for the whole family though, and Elephant Man.GeoffreyA - Monday, March 28, 2022 - link
Another film I love is Kieslowski's "Trois couleurs rouge" (Three Colours: Red).mode_13h - Wednesday, March 30, 2022 - link
I saw Red, long ago. I remember it made an impression on me, but not much else.I remember watching bits of Elephant Man with my parents, but they rented and watched it at home and I think I was too young to really sit and watch the whole thing.
Never saw Lost Highway, but I think one of the first MP3s I got was a rip of the Trent Reznor song from it + remixes.
Heh, I just watched the documentary: Jodorowsky's Dune. What a trippy guy! He literally cast Salvador Dali as the Emperor and seems to have been H.R. Geiger's route into the movie business. We can probably thank the fact that he cast Mick Jagger as Feyd-Rautha as the reason Sting ended up in Lynch's version.
I think it's safe to say it would've been a *very* different movie. He seemed most fascinated by the aspects of the book that least impressed me (i.e. the mysticism and psychedelic stuff). He said he wanted the movie to seem like a long acid trip and even admitted to changing the ending. Unapologetically. He's *that* kind of film maker ...which is okay, but just not if you're a fan of the book.
GeoffreyA - Friday, April 1, 2022 - link
The first time I saw Red, I didn't think much of it, except that it was very polished stylistically; but it's the sort of film that gains a lot from repeat viewings, and possesses a beautiful symmetry and design. It seems to distill, in a simpler fashion, the "plot" we sometimes see in life.I've often heard about Jodorowsky's Dune and need to watch that documentary. Well, if Geiger's designs were supposed to be there, it would've been a striking movie, that's for sure! I get the feeling I might have actually enjoyed it. Anyhow, looks as if the faithful Dune adaptation is still to be made. Where is this mighty director?
GeoffreyA - Friday, April 1, 2022 - link
(Come to think of it, DeMille might have done a good job.)mode_13h - Saturday, April 2, 2022 - link
> I've often heard about Jodorowsky's Dune and need to watch that documentary.You'd get a little more from the documentary if you'd read the book, first. Otherwise, you wouldn't have as much appreciation for the aspects of the book that attracted him. Plus, there's a bit of a spoiler, later in the documentary, where he talks about how he was going to change the ending.
GeoffreyA - Sunday, April 3, 2022 - link
I see. Thanks for that warning!Violet Giraffe - Friday, March 11, 2022 - link
Are you mad? Apple is at least a year behind the real CPU manufacturers. And Zen 4 will leave it on the side of the road.Violet Giraffe - Friday, March 11, 2022 - link
M1 is cute, nothing more. It's GPU is relatively powerful compared to other mobile chips, otherwise it sucks. I have an M1 Mac Mini so it's first-hand experience.