The Intel 12th Gen Core i9-12900K Review: Hybrid Performance Brings Hybrid Complexity
by Dr. Ian Cutress & Andrei Frumusanu on November 4, 2021 9:00 AM ESTCPU Tests: SPEC MT Performance - P and E-Core Scaling
Update Nov 6th:
We’ve finished our MT breakdown for the platform, investigating the various combination of cores and memory configurations for Alder Lake and the i9-12900K. We're posting the detailed scores for the DDR5 results, following up the aggregate results for DDR4 as well.
The results here solely cover the i9-12900K and various combinations of MT performance, such as 8 E-cores, 8 P-cores with 1T as well as 2T, and the full 24T 8P2T+8E scenario. The results here were done on Linux due to easier way to set affinities to the various cores, and they’re not completely comparable to the WSL results on the previous page, however should be within small margins of error for most tests.
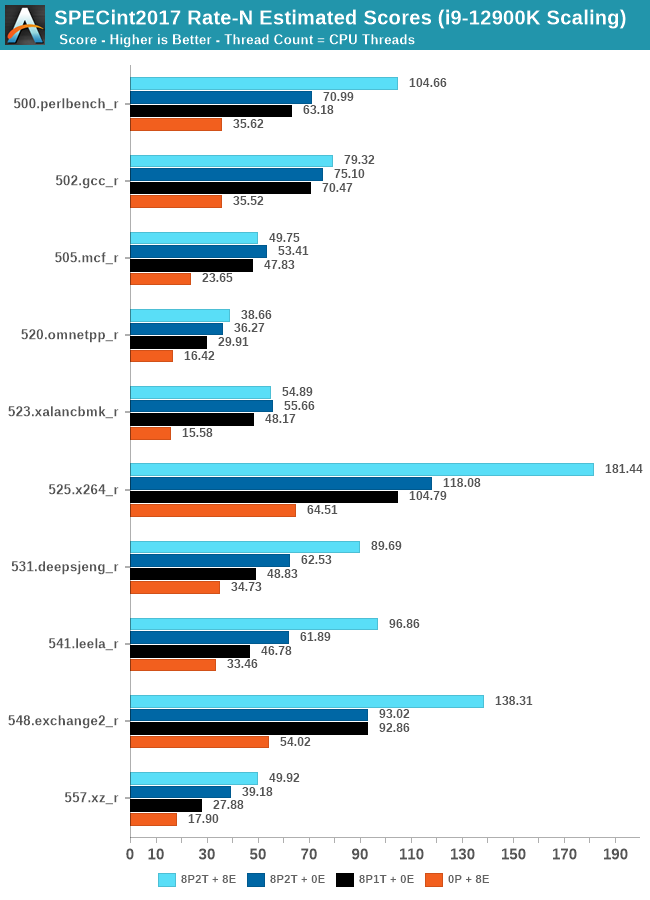
In the integer suite, the E-cores are quite powerful, reaching scores of around 50% of the 8P2T results, or more.
Many of the more core-bound workloads appear to very much enjoy just having more cores added to the suite, and these are also the workloads that have the largest gains in terms of gaining performance when we add 8 E-cores on top of the 8P2T results.
Workloads that are more cache-heavy, or rely on memory bandwidth, both shared resources on the chip, don’t scale too well at the top-end of things when adding the 8 E-cores. Most surprising to me was the 502.gcc_r result which barely saw any improvement with the added 8 E-cores.
More memory-bound workloads such as 520.omnetpp or 505.mcf are not surprising to see them not scale with the added E-cores – mcf even seeing a performance regression as the added cores mean more memory contention on the L3 and memory controllers.
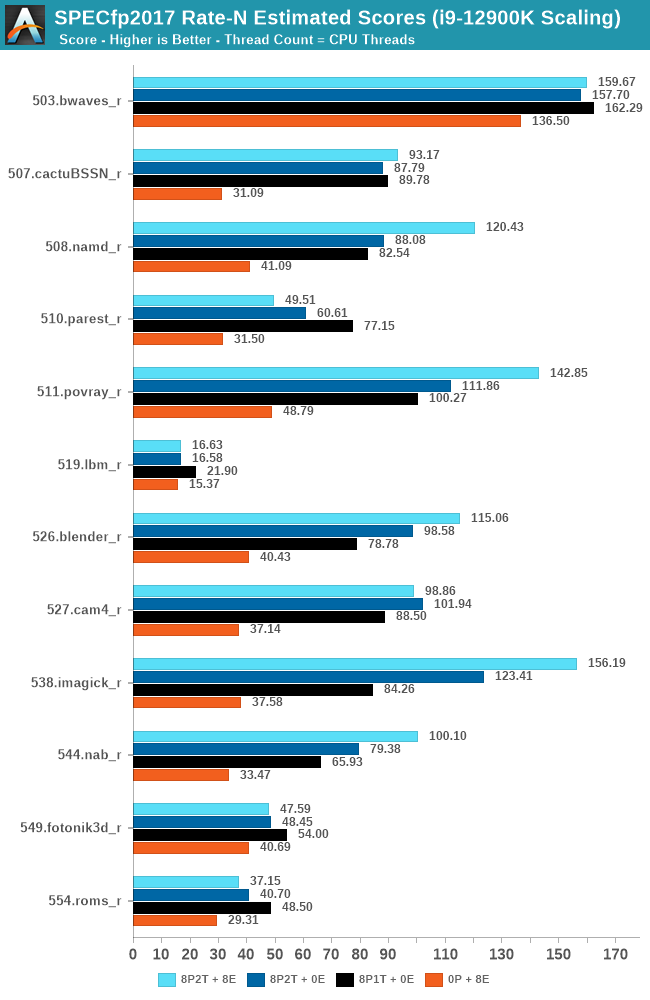
In the FP suite, the E-cores more clearly showcase a lower % of performance relative to the P-cores, and this makes sense given their design. Only few more compute-bound tests, such as 508.namd, 511.povray, or 538.imagick see larger contributions of the E-cores when they’re added in on top of the P-cores.
The FP suite also has a lot more memory-hungry workload. When it comes to DRAM bandwidth, having either E-cores or P-cores doesn’t matter much for the workload, as it’s the memory which is bottlenecked. Here, the E-cores are able to achieve extremely large performance figures compared to the P-cores. 503.bwaves and 519.lbm for example are pure DRAM bandwidth limited, and using the E-cores in MT scenarios allows for similar performance to the P-cores, however at only 35-40W package power, versus 110-125W for the P-cores result set.
Some of these workloads also see regressions in performance when adding in more cores or threads, as it just means more memory traffic contention on the chip, such as seen in the 8P2T+8E, 8P2T regressions over the 8P1T results.
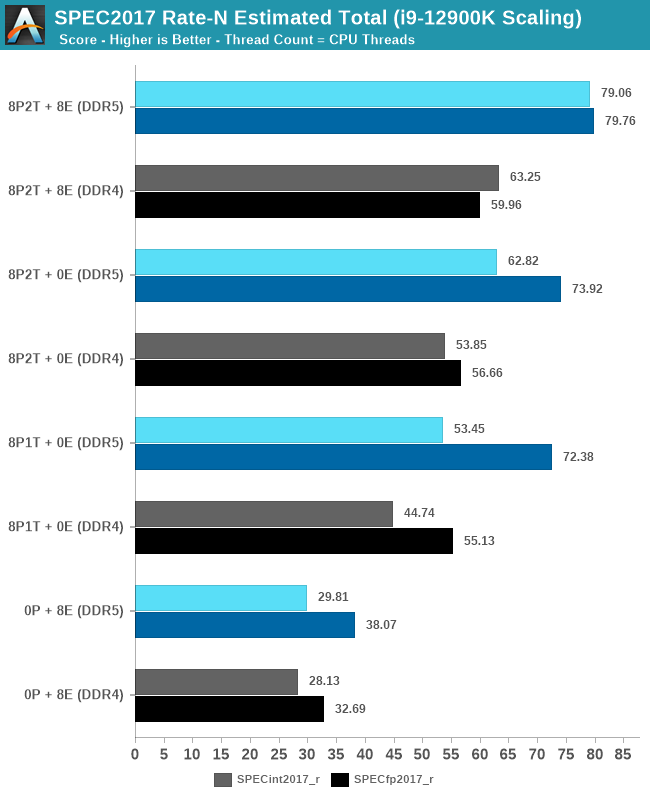
What’s most interesting here is the scaling of performance and the attribution between the P-cores and the E-cores. Focusing on the DDR5 set, the 8 E-cores are able to provide around 52-55% of the performance of 8 P-cores without SMT, and 47-51% of the P-cores with SMT. At first glance this could be argued that the 8P+8E setup can be somewhat similar to a 12P setup in MT performance, however the combined performance of both clusters only raises the MT scores by respectively 25% in the integer suite, and 5% in the FP suite, as we are hitting near package power limits with just 8P2T, and there’s diminishing returns on performance given the shared L3. What the E-cores do seem to allow the system is to allows to reduce every-day average power usage and increase the efficiency of the socket, as less P-cores need to be active at any one time.








474 Comments
View All Comments
mode_13h - Tuesday, November 9, 2021 - link
Well, AMD does have V-Cache and Zen 3+ in the queue. But if you want to short them, be my guest!Sivar - Monday, November 8, 2021 - link
This is an amazingly deep, properly Anandtech review, even ignoring time constraints and the unusual difficulty of this particular launch.I bet Ian and Andrei will be catching up on sleep for weeks.
xhris4747 - Tuesday, November 9, 2021 - link
Hiricebunny - Tuesday, November 9, 2021 - link
It’s disappointing that Anandtech continues to use suboptimal compilers for their platforms. Intel’s Compiler classic demonstrated 41% better performance than Clang 12.0.0 in the SPECrate 2017 Floating Point suite.mode_13h - Wednesday, November 10, 2021 - link
I think it's fair, though. Most workloads people run aren't built with vendor-supplied compilers, they use industry standards of gcc, clang, or msvc. And the point of benchmarks it to give you an idea of what the typical user experience would be.ricebunny - Wednesday, November 10, 2021 - link
But are they not compiling the code for the M1 series chips with a vendor supplied compiler?Second, almost all benchmarks in SPECrate 2017 Floating Point are scientific codes, half of which are in Fortran. That’s exactly the target domain of the Intel compiler. I admit, I am out of date with the HPC developments, but back when I was still in the game icc was the most commonly used compiler.
mode_13h - Thursday, November 11, 2021 - link
> are they not compiling the code for the M1 series chips with a vendor supplied compiler?It's just a slightly newer version of LLVM than what you'd get on Linux.
> almost all benchmarks in SPECrate 2017 Floating Point are scientific codes,
3 are rendering, animation, and image processing. Some of the others could fall more in the category of engineering than scientific, but whatever.
> half of which are in Fortran.
Only 3 are pure fortran. Another 4 are some mixture, but we don't know the relative amounts. They could literally link in BLAS or some FFT code for some trivial setup computation, and that would count as including fortran.
https://www.spec.org/cpu2017/Docs/index.html#intra...
BTW, you conveniently ignored how only one of the SPECrate 2017 int tests is fortran.
mode_13h - Thursday, November 11, 2021 - link
Oops, I accidentally counted one test that's only SPECspeed.So, in SPECrate 2017 fp:
3 are fortran
3 are fortran & C/C++
7 are only C/C++
ricebunny - Thursday, November 11, 2021 - link
Yes, I made the same mistake when counting.Without knowing what the Fortran code in the mixed code represents I would not discard it as irrelevant: those tests could very well spend a majority of their time executing Fortran.
As for the int tests, the advantage of the Intel compiler was even more pronounced: almost 50% over Clang. IMO this is too significant to ignore.
If I ran these tests, I would provide results from multiple compilers. I would also consult with the CPU vendors regarding the recommended compiler settings. Anandtech refuses to compile code with AVX512 support for non Alder Lake Intel chips, whereas Intel’s runs of SPECrate2017 enable that switch?
xray9 - Sunday, November 14, 2021 - link
> At Intel’s Innovation event last week, we learned that the operating system> will de-emphasise any workload that is not in user focus.
I see performance critical for audio applications which need near-real time performance.
It's already a pain to find good working drivers that do not allocate CPU core for too long, not to block processes with near-realtime demands.
And for performance tuning we use already the Windows option to priotize for background processes, which gives the process scheduler a higher and fix time quantum, to be able to work more efficient on processes and to lower the number of context switches.
And now we get this hybrid design where everything becomes out of control and you can only hope and pray, that the process scheduling will not be too bad. I am not amused about that and very skeptical, that this will work out well.