The Intel 12th Gen Core i9-12900K Review: Hybrid Performance Brings Hybrid Complexity
by Dr. Ian Cutress & Andrei Frumusanu on November 4, 2021 9:00 AM ESTFundamental Windows 10 Issues: Priority and Focus
In a normal scenario the expected running of software on a computer is that all cores are equal, such that any thread can go anywhere and expect the same performance. As we’ve already discussed, the new Alder Lake design of performance cores and efficiency cores means that not everything is equal, and the system has to know where to put what workload for maximum effect.
To this end, Intel created Thread Director, which acts as the ultimate information depot for what is happening on the CPU. It knows what threads are where, what each of the cores can do, how compute heavy or memory heavy each thread is, and where all the thermal hot spots and voltages mix in. With that information, it sends data to the operating system about how the threads are operating, with suggestions of actions to perform, or which threads can be promoted/demoted in the event of something new coming in. The operating system scheduler is then the ring master, combining the Thread Director information with the information it has about the user – what software is in the foreground, what threads are tagged as low priority, and then it’s the operating system that actually orchestrates the whole process.
Intel has said that Windows 11 does all of this. The only thing Windows 10 doesn’t have is insight into the efficiency of the cores on the CPU. It assumes the efficiency is equal, but the performance differs – so instead of ‘performance vs efficiency’ cores, Windows 10 sees it more as ‘high performance vs low performance’. Intel says the net result of this will be seen only in run-to-run variation: there’s more of a chance of a thread spending some time on the low performance cores before being moved to high performance, and so anyone benchmarking multiple runs will see more variation on Windows 10 than Windows 11. But ultimately, the peak performance should be identical.
However, there are a couple of flaws.
At Intel’s Innovation event last week, we learned that the operating system will de-emphasise any workload that is not in user focus. For an office workload, or a mobile workload, this makes sense – if you’re in Excel, for example, you want Excel to be on the performance cores and those 60 chrome tabs you have open are all considered background tasks for the efficiency cores. The same with email, Netflix, or video games – what you are using there and then matters most, and everything else doesn’t really need the CPU.
However, this breaks down when it comes to more professional workflows. Intel gave an example of a content creator, exporting a video, and while that was processing going to edit some images. This puts the video export on the efficiency cores, while the image editor gets the performance cores. In my experience, the limiting factor in that scenario is the video export, not the image editor – what should take a unit of time on the P-cores now suddenly takes 2-3x on the E-cores while I’m doing something else. This extends to anyone who multi-tasks during a heavy workload, such as programmers waiting for the latest compile. Under this philosophy, the user would have to keep the important window in focus at all times. Beyond this, any software that spawns heavy compute threads in the background, without the potential for focus, would also be placed on the E-cores.
Personally, I think this is a crazy way to do things, especially on a desktop. Intel tells me there are three ways to stop this behaviour:
- Running dual monitors stops it
- Changing Windows Power Plan from Balanced to High Performance stops it
- There’s an option in the BIOS that, when enabled, means the Scroll Lock can be used to disable/park the E-cores, meaning nothing will be scheduled on them when the Scroll Lock is active.
(For those that are interested in Alder Lake confusing some DRM packages like Denuvo, #3 can also be used in that instance to play older games.)
For users that only have one window open at a time, or aren’t relying on any serious all-core time-critical workload, it won’t really affect them. But for anyone else, it’s a bit of a problem. But the problems don’t stop there, at least for Windows 10.
Knowing my luck by the time this review goes out it might be fixed, but:
Windows 10 also uses the threads in-OS priority as a guide for core scheduling. For any users that have played around with the task manager, there is an option to give a program a priority: Realtime, High, Above Normal, Normal, Below Normal, or Idle. The default is Normal. Behind the scenes this is actually a number from 0 to 31, where Normal is 8.
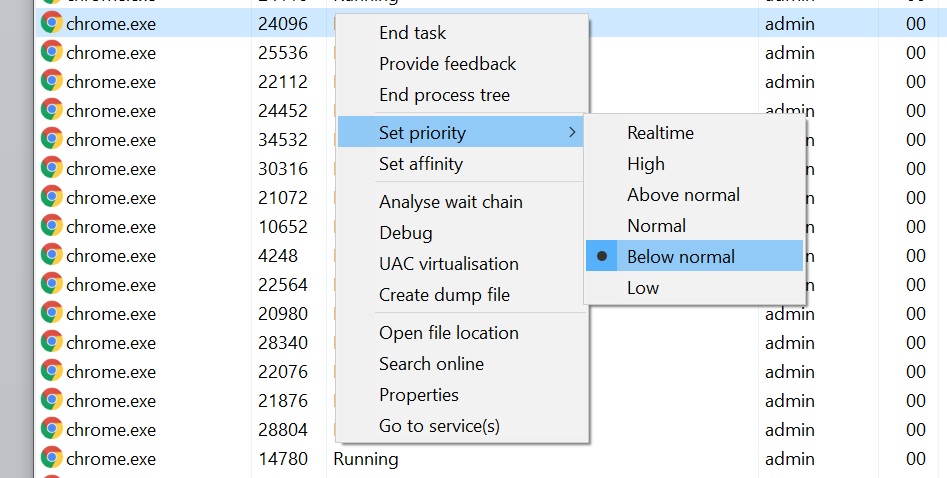
Some software will naturally give itself a lower priority, usually a 7 (below normal), as an indication to the operating system of either ‘I’m not important’ or ‘I’m a heavy workload and I want the user to still have a responsive system’. This second reason is an issue on Windows 10, as with Alder Lake it will schedule the workload on the E-cores. So even if it is a heavy workload, moving to the E-cores will slow it down, compared to simply being across all cores but at a lower priority. This is regardless of whether the program is in focus or not.
Of the normal benchmarks we run, this issue flared up mainly with the rendering tasks like CineBench, Corona, POV-Ray, but also happened with yCruncher and Keyshot (a visualization tool). In speaking to others, it appears that sometimes Chrome has a similar issue. The only way to fix these programs was to go into task manager and either (a) change the thread priority to Normal or higher, or (b) change the thread affinity to only P-cores. Software such as Project Lasso can be used to make sure that every time these programs are loaded, the priority is bumped up to normal.








474 Comments
View All Comments
mode_13h - Tuesday, November 9, 2021 - link
Well, AMD does have V-Cache and Zen 3+ in the queue. But if you want to short them, be my guest!Sivar - Monday, November 8, 2021 - link
This is an amazingly deep, properly Anandtech review, even ignoring time constraints and the unusual difficulty of this particular launch.I bet Ian and Andrei will be catching up on sleep for weeks.
xhris4747 - Tuesday, November 9, 2021 - link
Hiricebunny - Tuesday, November 9, 2021 - link
It’s disappointing that Anandtech continues to use suboptimal compilers for their platforms. Intel’s Compiler classic demonstrated 41% better performance than Clang 12.0.0 in the SPECrate 2017 Floating Point suite.mode_13h - Wednesday, November 10, 2021 - link
I think it's fair, though. Most workloads people run aren't built with vendor-supplied compilers, they use industry standards of gcc, clang, or msvc. And the point of benchmarks it to give you an idea of what the typical user experience would be.ricebunny - Wednesday, November 10, 2021 - link
But are they not compiling the code for the M1 series chips with a vendor supplied compiler?Second, almost all benchmarks in SPECrate 2017 Floating Point are scientific codes, half of which are in Fortran. That’s exactly the target domain of the Intel compiler. I admit, I am out of date with the HPC developments, but back when I was still in the game icc was the most commonly used compiler.
mode_13h - Thursday, November 11, 2021 - link
> are they not compiling the code for the M1 series chips with a vendor supplied compiler?It's just a slightly newer version of LLVM than what you'd get on Linux.
> almost all benchmarks in SPECrate 2017 Floating Point are scientific codes,
3 are rendering, animation, and image processing. Some of the others could fall more in the category of engineering than scientific, but whatever.
> half of which are in Fortran.
Only 3 are pure fortran. Another 4 are some mixture, but we don't know the relative amounts. They could literally link in BLAS or some FFT code for some trivial setup computation, and that would count as including fortran.
https://www.spec.org/cpu2017/Docs/index.html#intra...
BTW, you conveniently ignored how only one of the SPECrate 2017 int tests is fortran.
mode_13h - Thursday, November 11, 2021 - link
Oops, I accidentally counted one test that's only SPECspeed.So, in SPECrate 2017 fp:
3 are fortran
3 are fortran & C/C++
7 are only C/C++
ricebunny - Thursday, November 11, 2021 - link
Yes, I made the same mistake when counting.Without knowing what the Fortran code in the mixed code represents I would not discard it as irrelevant: those tests could very well spend a majority of their time executing Fortran.
As for the int tests, the advantage of the Intel compiler was even more pronounced: almost 50% over Clang. IMO this is too significant to ignore.
If I ran these tests, I would provide results from multiple compilers. I would also consult with the CPU vendors regarding the recommended compiler settings. Anandtech refuses to compile code with AVX512 support for non Alder Lake Intel chips, whereas Intel’s runs of SPECrate2017 enable that switch?
xray9 - Sunday, November 14, 2021 - link
> At Intel’s Innovation event last week, we learned that the operating system> will de-emphasise any workload that is not in user focus.
I see performance critical for audio applications which need near-real time performance.
It's already a pain to find good working drivers that do not allocate CPU core for too long, not to block processes with near-realtime demands.
And for performance tuning we use already the Windows option to priotize for background processes, which gives the process scheduler a higher and fix time quantum, to be able to work more efficient on processes and to lower the number of context switches.
And now we get this hybrid design where everything becomes out of control and you can only hope and pray, that the process scheduling will not be too bad. I am not amused about that and very skeptical, that this will work out well.